当通过命令行,根据crawl模板生成spider时,
执行scrapy genspider -t crawl lagou www.lagou.com
出现如下报错(图三):
原因是项目中已有的一句代码:
from items import JobBoleArticleItem,ArticleItemLoader
就是因为命令行格式不能像pycharm那样,命令行不会把你的source root放进pathon path 中,所以命令行找不到item

图3
解决方法:
方法一:
把
from items import JobBoleArticleItem,ArticleItemLoader
改为
from SpiderLearning_py35_64.items import JobBoleArticleItem,ArticleItemLoader
方法二:
第一步、在setting文件中增加以下代码
#获得SpiderLearning_py35_64的目录,也就是E:PyCharmWorkspaceSpiderLearning_py35_64SpiderLearning_py35_64,将其添加到path中
import os project_dir = os.path.abspath(os.path.dirname(__file__))#os.path.dirname(__file__)获得父文件名称 import sys sys.path.insert(0,project_dir) #0是优先级
第二步:这时运行添加crawl spider命令就不会报错了.
原理介绍
==============================================================================
爬虫项目的目录结构是这样的:
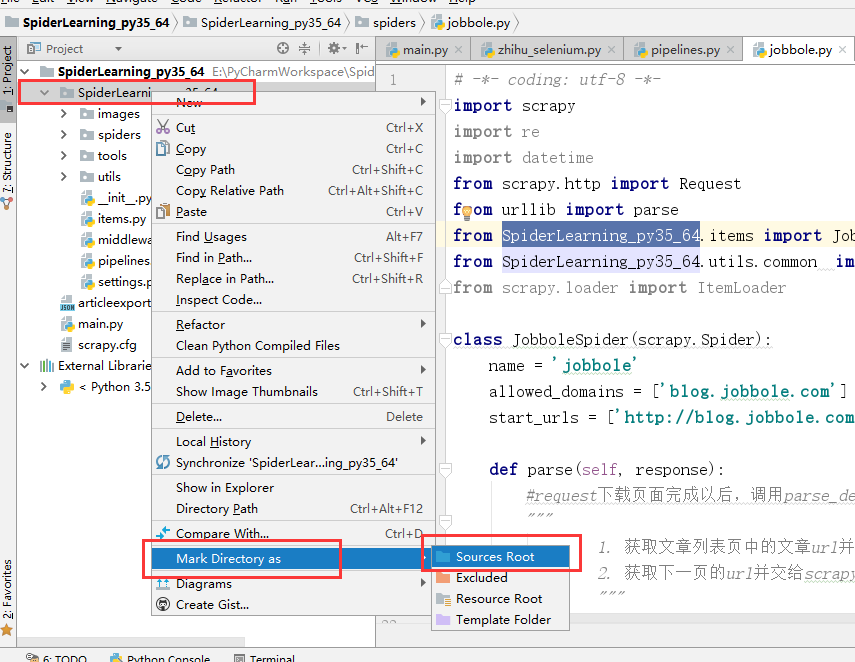
把项目目录下的 SpiderLearning_py35_64设置为Sources root ,pycharm会将Sources root的目录添加到python path中,类似环境变量,如图2。当代码中导入什么东西,会自动去python path下面找。
例如:如果不把SpiderLearning_py35_64设置为Sources root,那么下面这句代码会报错
from items import JobBoleArticleItem,ArticleItemLoader
改为下面这样才可以:
from SpiderLearning_py35_64.items import JobBoleArticleItem,ArticleItemLoader
