作业要求来自https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:见上次博客爬取全部的校园新闻并保存csv
newsdf = pd.read_csv(r'F:duymgzccnews.csv')
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
成功保存:


1 newsdf = pd.read_csv(r'C:UsersCzcPycharmProjects ews.csv') 2 3 import sqlite3 4 ''' 5 with sqlite3.connect('gzccnewsdb.sqlite') as db: 6 newsdf.to_sql('gzccnews',con = db) 7 ''' 8 with sqlite3.connect('gzccnewsdb.sqlite') as db: 9 df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db) 10 11 12 import pymysql 13 from sqlalchemy import create_engine 14 coninfo = "mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8" 15 engine = create_engine(coninfo,encoding="utf-8") 16 17 newsdf.to_sql(name='news',con=engine,if_exists='append',index= False,index_label='id')
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
参考:
爬了一下天猫上的Bra购买记录,有了一些羞羞哒的发现...
Python做了六百万字的歌词分析,告诉你中国Rapper都在唱些啥
分析了42万字歌词后,终于搞清楚民谣歌手唱什么了
十二星座的真实面目
唐朝诗人之间的关系到底是什么样的?
中国姓氏排行榜
三.爬虫注意事项
1.设置合理的爬取间隔,不会给对方运维人员造成压力,也可以防止程序被迫中止。
- import time
- import random
- time.sleep(random.random()*3)
2.设置合理的user-agent,模拟成真实的浏览器去提取内容。
- 首先打开你的浏览器输入:about:version。
- 用户代理:
- 收集一些比较常用的浏览器的user-agent放到列表里面。
- 然后import random,使用随机获取一个user-agent
- 定义请求头字典headers={’User-Agen‘:}
- 发送request.get时,带上自定义了User-Agen的headers
3.需要登录
发送request.get时,带上自定义了Cookie的headers
headers={’User-Agen‘:
'Cookie': }
4.使用代理IP
通过更换IP来达到不断高 效爬取数据的目的。
headers = {
"User-Agent": "",
}
proxies = {
"http": " ",
"https": " ",
}
response = requests.get(url, headers=headers, proxies=proxies)
python大作业之--使用python爬取微信好友
01 准备工作
运行平台:Windows 10
Python版本:Python3.7
首先登陆python版本微信itchat,生成二维码扫描登陆获取微信好友列表

然后统计好友男女数量并打印输出
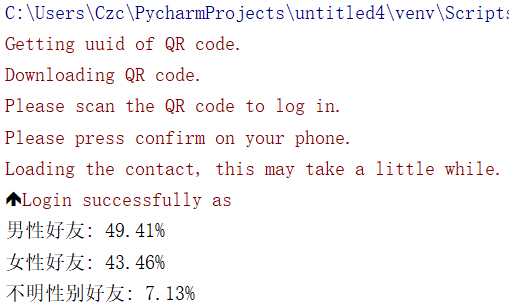
接着使用matplotlib绘图

输出结果可以我的微信好友男女比例大概五五开,即使是在男女37开的学校,说明我微信里的女生数比较少,有待加强。
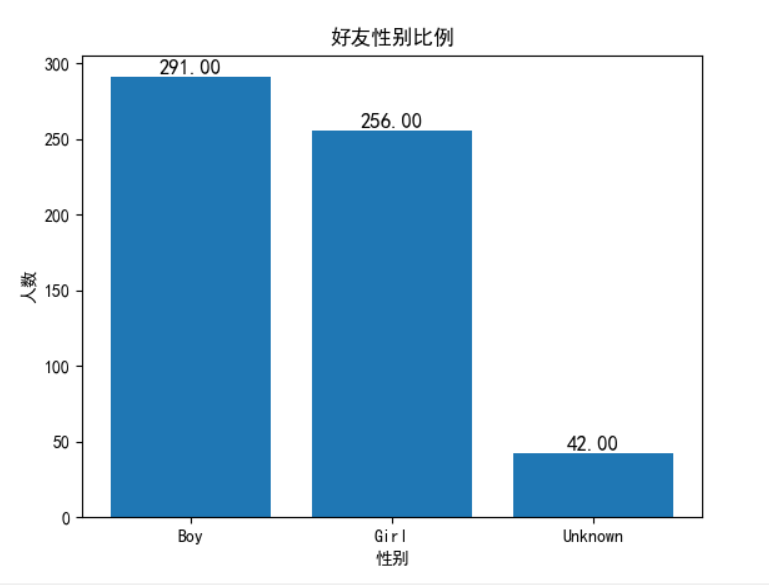
接着获取微信好友的信息

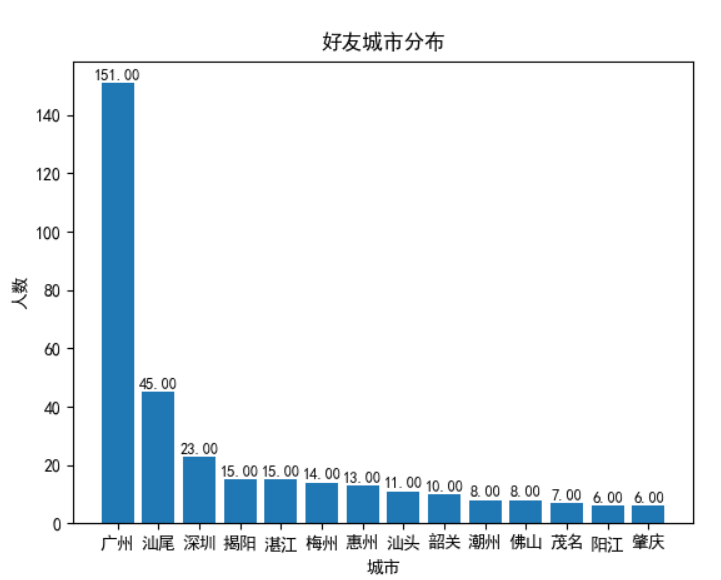
统计好友所在城市信息并绘图输出
输出结果可以看出广州的好友占了大多数,因为是在广州上的大学,所以身边大多数都是广州的吧,还有比较多的城市的就是汕尾了,因为老家在汕尾,所以汕尾的人数也达到了45,紧接着就深圳等大城市了。
根据获取到的微信好友个性签名画词云
输出结果可以看出我微信好友的个性签名比较励志正常的,像努力,时间,开心,自己,平安等,另外广商也是一大特征。

完整代码:
1 # -*- coding: utf-8 -*- 2 3 import numpy as np 4 import itchat 5 import matplotlib.pyplot as plt 6 # 登录微信,会弹出二维码,用手机微信扫一扫即可登录 7 itchat.login() 8 # 获取好友的所有数据 9 friends = itchat.get_friends(update=True)[0:] 10 11 # ***-----统计好友性别比例-----*** 12 # 初始化计数器 13 male = female = other = 0 14 # friends[0]是自己的信息,因此从friends[1]开始 15 for i in friends[1:]: 16 sex = i['Sex'] 17 if sex == 1: 18 male += 1 19 elif sex == 2: 20 female += 1 21 else: 22 other += 1 23 # 计算朋友总数 24 total = len(friends[1:]) 25 # 打印输出好友性别比例 26 print( 27 "男性好友: %.2f%%" % (float(male)/total * 100) + " " + 28 "女性好友: %.2f%%" % (float(female)/total * 100) + " " + 29 "不明性别好友: %.2f%%" % (float(other)/total * 100) 30 ) 31 32 33 # 进行绘图 34 label_name = ["Boy", "Girl", "Unknown"] 35 gender_list = [male, female, other] 36 plt.figure() 37 plt.bar(range(len(gender_list)), gender_list, tick_label=label_name) 38 39 # 绘图中文显示设置 40 plt.rcParams['font.sans-serif']=['SimHei'] 41 plt.rcParams['axes.unicode_minus']=False 42 43 plt.xlabel(u'性别') 44 plt.ylabel(u'人数') 45 plt.title(u'好友性别比例') 46 47 # 在柱状图上显示数字 48 x=np.arange(3) 49 y=np.array(gender_list) 50 for a,b in zip(x,y): 51 plt.text(a, b+0.1, '%.2f' % b, ha='center', va= 'bottom',fontsize=12) 52 53 54 # ***-----获取各类信息-----*** 55 # 定义函数,爬取所有好友的指定信息 56 def get_var(var): 57 variable = [] 58 for i in friends[1:]: 59 value = i[var] 60 variable.append(value) 61 return variable 62 63 # 调用函数,得到对应信息,并存入csv文件,保存到桌面 64 NickName = get_var("NickName") 65 Sex = get_var("Sex") 66 Province = get_var("Province") 67 City = get_var("City") 68 Signature = get_var("Signature") 69 70 # Excel 打开中文乱码问题 未解决 71 # 不过可以通过Excel->数据->文本导入的形式,将csv文件导入,就可以避免乱码问题 72 from pandas import DataFrame 73 74 data = {"NickName": NickName, "Sex": Sex, "Province": Province, 75 "City": City, "Signature": Signature} 76 frame = DataFrame(data) 77 frame.to_csv('data.csv', encoding='utf_8_sig', index=True) 78 79 # ***-----统计好友城市分布-----*** 80 city_dict = {} 81 x_city = [] 82 y_city = [] 83 for city_name in City: 84 if city_name in city_dict: 85 city_dict[city_name] += 1 86 else: 87 city_dict[city_name] = 1 88 city_list = sorted(city_dict.items(), key=lambda item:item[1], reverse=True) 89 # 将前14个城市排序显示,去除排名第一的未知城市(城市信息为空的好友) 90 for i in city_list[1:15]: 91 x_city.append(i[0]) 92 y_city.append(i[1]) 93 plt.figure() 94 plt.bar(range(len(x_city)), y_city, tick_label=x_city) 95 plt.xlabel(u'城市') 96 plt.ylabel(u'人数') 97 plt.title(u'好友城市分布') 98 # 在柱状图上显示数字 99 x=np.arange(len(x_city)) 100 y=np.array(y_city) 101 for a,b in zip(x,y): 102 plt.text(a, b+0.06, '%.2f' % b, ha='center', va='bottom', fontsize=9) 103 104 # ***-----根据个性签名绘制词云图-----*** 105 # 通过正则匹配清洗数据 106 import re 107 Signature_list = [] 108 for i in friends: 109 signature = i["Signature"].strip().replace("span", "").replace("class", "").replace("emoji", "") 110 rep = re.compile("lfd+w*|[<>/=]") 111 signature = rep.sub("", signature) 112 Signature_list.append(signature) 113 text = "".join(Signature_list) 114 # 调包进行分词 115 import jieba 116 wordlist = jieba.cut(text, cut_all=False) 117 word_space_split = " ".join(wordlist) 118 # 调包进行词云图绘制 119 from wordcloud import WordCloud, ImageColorGenerator 120 import PIL.Image as Image 121 coloring = np.array(Image.open("czc.jpg")) 122 my_wordcloud = WordCloud(background_color="white", max_words=200, 123 mask=coloring, max_font_size=70, random_state=42, scale=2, 124 font_path="C:WindowsFontsSimHei.ttf").generate(word_space_split) 125 image_colors = ImageColorGenerator(coloring) 126 plt.figure() 127 plt.imshow(my_wordcloud.recolor(color_func=image_colors)) 128 plt.imshow(my_wordcloud) 129 plt.axis("off") 130 plt.show()
还可以使用获取到的微信好友头像进行拼接(参考https://blog.csdn.net/zrp220807/article/details/80455651)
核心模块
- itchat(爬取头像)
- pillow(拼接头像)
内置模块
- os(文件夹操作)
- math(数学计算)
