声明:源码版本为Tomcat 6.0.35
前面的文章中介绍了Tomcat初始化的过程,本文将会介绍Tomcat对HTTP请求的处理的整体流程,更细节的。
在上一篇文章中,介绍到JIoEndpoint 中的内部类Acceptor用来接受Socket请求,并调用processSocket方法来进行请求的处理,所以会从本文这个方法开始进行讲解。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
protected boolean processSocket(Socket socket) { try { if (executor == null) { getWorkerThread().assign(socket); } else { executor.execute(new SocketProcessor(socket)); } } catch (Throwable t) { //……此处略去若干代码 } return true; } |
在以上的代码中,首先会判断是否在server.xml配置了进程池,如果配置了的话,将会使用该线程池进行请求的处理,如果没有配置的话将会使用JIoEndpoint中自己实现的线程池WorkerStack来进行请求的处理,我们将会介绍WorkerStack的请求处理方式。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
protected Worker getWorkerThread() { // Allocate a new worker thread synchronized (workers) { Worker workerThread; while ((workerThread = createWorkerThread()) == null) { try { workers.wait(); } catch (InterruptedException e) { // Ignore } } return workerThread; } } |
在以上的代码中,最终返回了一个Worker的实例,有其来进行请求的处理,在这里,我们再看一下createWorkerThread方法,该方法会生成或者在线程池中取到一个线程。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
protected Worker createWorkerThread() { synchronized (workers) { if (workers.size() > 0) { //如果线程池中有空闲的线程,取一个 curThreadsBusy++; return workers.pop(); } if ((maxThreads > 0) && (curThreads < maxThreads)) { //如果还没有超过最大线程数,会新建一个线程 curThreadsBusy++; return (newWorkerThread()); } else { if (maxThreads < 0) { curThreadsBusy++; return (newWorkerThread()); } else { return (null); } } } } |
到此,线程已经获取了,接下来,最关键的是调用线程实现Worker的run方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public void run() { // Process requests until we receive a shutdown signal while (running) { // Wait for the next socket to be assigned Socket socket = await(); if (socket == null) continue; if (!setSocketOptions(socket) || !handler.process(socket)) { try { socket.close(); } catch (IOException e) { } } socket = null; recycleWorkerThread(this); } } |
这里跟请求处理密切相关的是handler.process(socket)这一句代码,此处handle对应的类是Http11Protocol中的内部类Http11ConnectionHandler,在此后的处理中,会有一些请求的预处理,我们用一个时序图来表示一下:

在这个过程中,会对原始的socket进行一些处理,到CoyoteAdapter时,接受的参数已经是org.apache.coyote.Request和org.apache.coyote.Response了,但是要注意的是,此时这两个类并不是我们常用的HttpServletRequest和HttpServletResponse的实现类,而是Tomcat内部的数据结构,存储了和输入、输出相关的信息。值得注意的是,在CoyoteAdapter的service方法中,会调用名为postParseRequest的方法,在这个方法中,会解析请求,调用Mapper的Map方法来确定该请求该由哪个Engine、Host和Context来处理。
在以上的信息处理完毕后,在CoyoteAdapter的service方法中,会调用这样一个方法:
|
1
|
connector.getContainer().getPipeline().getFirst().invoke(request, response); |
这个方法会涉及到Tomcat组件中的Container实现类的重要组成结构,即每个容器类组件都有一个pipeline属性,这个属性控制请求的处理过程,在pipeline上可以添加Valve,进而可以控制请求的处理流程。可以用下面的图来表示,请求是如何流动的:

可以将请求想象成水的流动,请求需要在各个组件之间流动,中间经过若干的水管和水阀,等所有的水阀走完,请求也就处理完了,而每个组件都会有一个默认的水阀(以Standard作为类的前缀)来进行请求的处理,如果业务需要的话,可以自定义Valve,将其安装到容器中。
后面的处理过程就比较类似了,会按照解析出来的Engine、Host、Context的顺序来进行处理。这里用了两张算不上标准的时序图来描述这一过程:

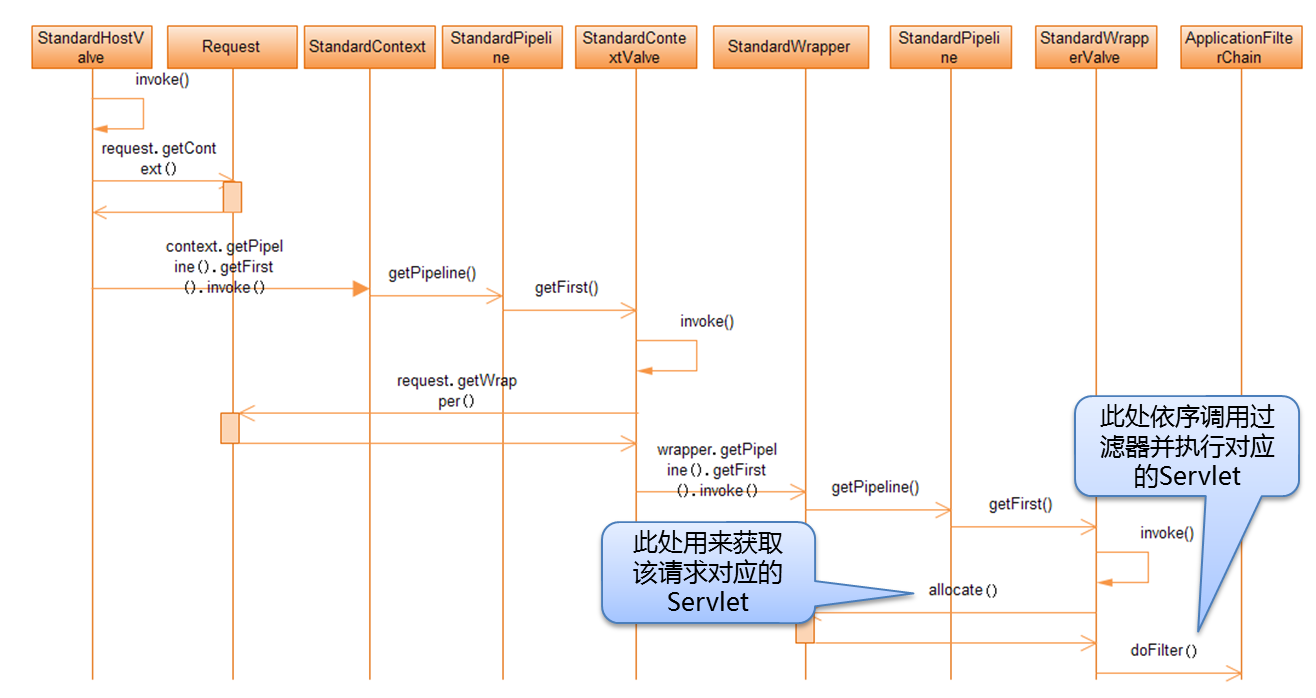
在以上的流程中,会一层层地调用各个容器组件的Valve的invoke方法,其中StandardWrapperValve这个标准阀门将会调用StandardWrapper的allocate方法来获取真正要执行的Servlet(在Tomcat中所有的请求最终都会映射到一个Servlet,静态资源和JSP也是如此),并按照请求的地址来构建过滤器链,按照顺序执行各个过滤器并最终调用目标Servlet的service方法,来完成业务的真正处理。
以上的处理过程中,涉及到很多重要的代码,后续的文章会择期要者进行解析,如:
-
Mapper中的internalMapWrapper方法(用来匹配对应的Servlet)
-
ApplicationFilterFactory的createFilterChain方法(用来创建该请求的过滤器链)
-
ApplicationFilterChain的internalDoFilter方法(用来执行过滤器方法以及最后的Servlet)
-
Http11Processor中的process方法、prepareRequest方法以及prepareResponse方法(用来处理HTTP请求相关的协议、参数等信息)
至此,我们简单了解一个请求的处理流程。