在使用LoadRunner的web_custom_request的时候,有时会遇到BodyBinary需要使用二进制参数,但是LoadRunner本身没有处理二进制参数的函数,
碰到这个问题,那怎么办呢?
一开始遇到这个,纠结出了以下两种方法:
1、使用python第三方语言处理,但是比较麻烦,需要文本复制转换;
2、写个处理二进制参数的接口,直接调用;
3、使用别人写好的程序,复制和粘贴,然后放到参数化文件中;
以上3种方法都用过,使用起来都比较费时间,当需要大量的参数化数据时,又是捉襟见肘。
然后又在思考究竟如何让LoadRunner生成二进制参数,在偶然看到URL编码的例子后,有眉目了;URL编码就是一个字符ascii码的十六进制,需要在前面加上“%”。
比如“”,它的ascii码是92,92的十六进制是5c,所以“”的url编码就是%5c。那么汉字的url编码呢?很简单,看例子:“胡”的ascii码是-17670,十六进制是BAFA,url编码是“%BA%FA”。
在LoadRunner中,有个web_convert_param函数,使用方法如下:

web_convert_param("skey", "SourceEncoding=PLAIN", "TargetEncoding=URL", LAST ); //其中skey是一个lr参数名
该例子把参数skey中的原来的值url编码后,覆盖了原skey参数:lr_output_message("Url编码 = %s",lr_eval_string("{skey}"));
HTML和PLAIN的区别,在http的相应头信息中,Content-Type字段可能有text/html和text/plain两种取值:
如果是html,浏览器在获取到这种文本时会自动调用html的解析器对文件进行相应的处理
如果是plain,意思是纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理
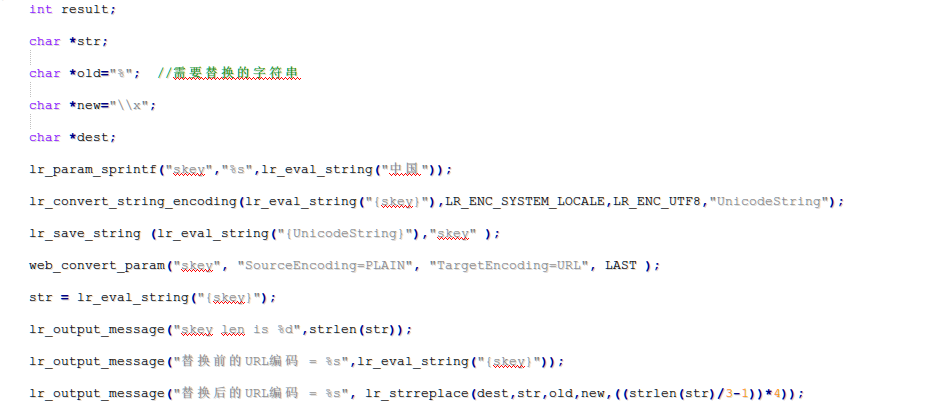
具体实现如下:

执行结果如下:

好了,生成二进制参数已经完成一半了,怎么把编码结果中的“%”替换成“x”呢?!
这里就要用到字符替换的函数了,LoadRunner本身没有字符替换的函数,但着完全可以用C写出来,这个难度不大,下面是实现方法。


再来执行一次,看看结果:

在替换的时候,使用了(strlen(str)/3-1))*4)这个表达式,可以思考下为什么这样用!?
另外,如果需要在BodyBinary中参数化UTF-8编码的中文汉字,需要加上lr_convert_string_encoding函数

实现方法如下:
执行结果:

好了,这些操作已经完成二进制参数化了,既可以参数化ascii字符,也可以参数化UTF-8的中文汉字。