收集完图片记得逐个审查一遍把垃圾图片删掉,后续画框时候尽量给每幅图都至少画上一个框。
一.安装labelImg
1.下载
https://github.com/tzutalin/labelImg
去github下载zip,解压之后根据下边的不同系统使用方法安装相应的依赖
比如我的是安装了anaconda的windows系统,我可以按照如下图片进行操作

2.运行方法
在cmd中切换到labelImg的安装目录下,我的是
f: #切换到f盘 cd F:softwarelabelImg-master #切换到下载目录
python labelImg.py #运行labelImg
二、labelImg标注使用方法
https://blog.csdn.net/gaoyu1253401563/article/details/89512098
1、软件图标的使用
(1)打开需要标记的图片文件夹

(2)修改保存路径(XML文件夹)
(3)标注ROI区域,填写标签
(4)保存XML文件,有弹框提醒
(5)点击下一张图进行标记
2、软件快捷键的使用
Ctrl +u : 打开图片文件夹
Ctrl +r : 更改结果保存位置
w: 开始画框
Ctrl +s : 保存
d: 下一张
a: 上一张
del: 删除画的框
Ctrl++: 图片放大
Ctrl–: 图片缩小
↑→↓←: 对框进行移动
Ctrl+d: 复制当前框的标签和框
3.具体标注步骤
①运行labelImg(见步骤2)
②修改默认的XML文件保存路径,使用快捷键“Ctrl+R”,改为自己想存储的位置,一般是新建个Annotations文件来存储XML文件。
如果是yolo的模型可以直接点击下图位置,生成文件由xml变成txt,yolo模型可以直接使用
xml模型转换成yolo模型方法见最后
注:路径一定不能包含中文,否则无法保存
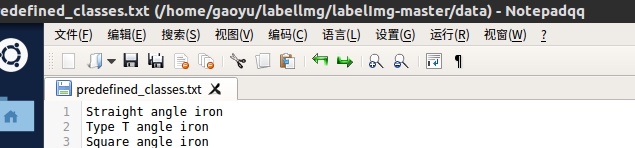
③在labelImg文件中,修改源码文件data/predefined_classes.txt,来修改类别,将默认类别换成我们需要的类别信息,例如person、dog、cat等
使用python规范化图片名称
import os class BatchRename(): #定义函数执行图片的路径 def __init__(self): self.path = '/home/darknet/scripts/VOCdevkit/VOC2019/JPEGImages'#修改为自己的图片路径 #定义函数实现重命名操作 def rename(self): filelist = os.listdir(self.path) total_num = len(filelist) i = 0 for item in filelist: if item.endswith('.jpg'): src = os.path.join(os.path.abspath(self.path), item) dst = os.path.join(os.path.abspath(self.path), str(i).zfill(6) + '.jpg') try: os.rename(src, dst) print('converting %s to %s ...' % (src, dst)) i = i + 1 except: continue print ('total %d to rename & converted %d jpgs' % (total_num, i)) #主函数调用 if __name__ == '__main__': demo = BatchRename() demo.rename()
使用Open Dir按钮来打开我们索要标注的图片文件夹JPEGImages,选择choose,然后打开了第一张需要标注的图片。
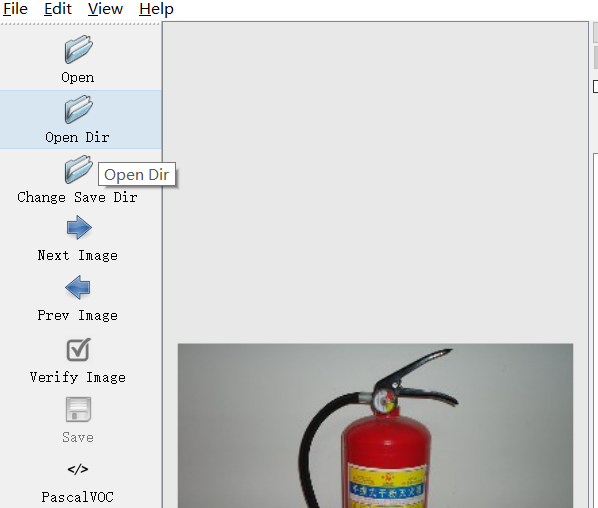
接下来使用Create RectBox按钮或者“Ctrl+N”来对图片中需要标注的软件进行画框,画完框,松掉鼠标左键,会弹出选择类别信息的框,选着我们所有标注的类别,然后点击ok
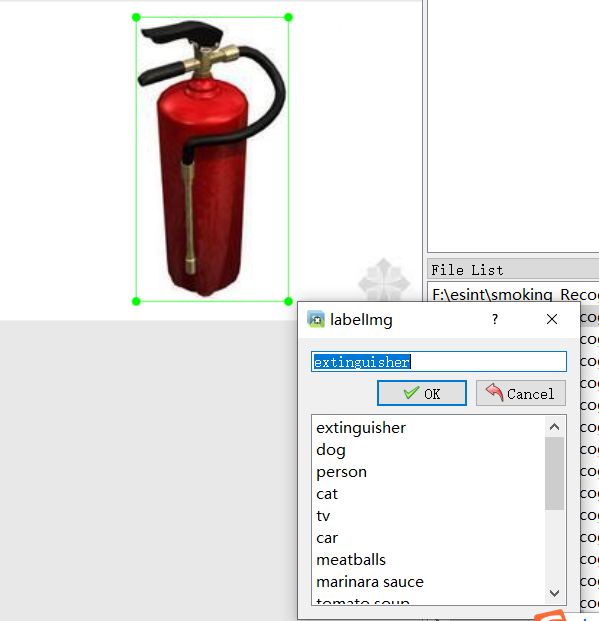
以上标注成功,然后等一张图片的所有目标都标注成功以后,点击Save保存按钮,此时就在Annotations文件下生成了一个对应图片名的XML文件,里面保存了标注信息
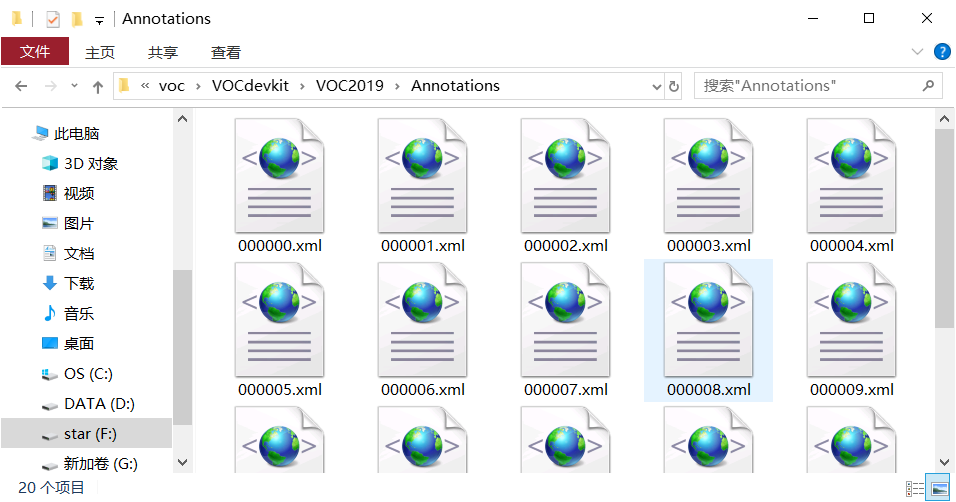
注:以上是标记过很多张之后生成的XML文件的结果
对于单张标记好的图片,打开XML文件,可看到标记信息如下

等待一张图片标注完毕后点击Next Image或者快捷键"d"进入下一张图片进行标注
注意文件放到voc的子目录下
参考:https://blog.csdn.net/qq_21578849/article/details/84980298
划分训练数据和测试数据
import os from os import listdir, getcwd from os.path import join if __name__ == '__main__': source_folder='F:/esint/smoking_Recognition/darknet-master/voc/VOCdevkit/VOC2019/JPEGImages'#地址是所有图片的保存地点 dest='F:/esint/smoking_Recognition/darknet-master/voc/VOCdevkit/VOC2019/ImageSets/Main/train.txt' #保存train.txt的地址,对于train.txt(在ImageSets/Main/下)和2019_train.txt(在VOCdevkit下)是不同的路径 dest2='F:/esint/smoking_Recognition/darknet-master/voc/VOCdevkit/VOC2019/ImageSets/Main/val.txt' #保存val.txt的地址,对于val.txt(在ImageSets/Main/下)和2019_val.txt(在VOCdevkit下)是不同的路径 file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表 train_file=open(dest,'a') #打开文件 val_file=open(dest2,'a') #打开文件 for file_obj in file_list: #访问文件列表中的每一个文件 file_path=os.path.join(source_folder,file_obj) #file_path保存每一个文件的完整路径 file_name,file_extend=os.path.splitext(file_obj) #file_name 保存文件的名字,file_extend保存文件扩展名 file_num=int(file_name) if(file_num<300): #保留300个文件用于训练 train_file.write(file_name+' ') #用于训练前620个的图片路径保存在train.txt里面,结尾加回车换行/////////生成train.txt是file_name;生成2019_train.txt是file_path else : val_file.write(file_name+' ') #其余的文件保存在val.txt里面/////////生成val.txt是file_name;生成2019_val.txt是file_path train_file.close()#关闭文件 val_file.close()
执行该文件前需要先划分训练数据和测试数据
将xml文件转换成txt文件
执行时可能遇到报错:ZeroDivisionError: float division by zero
原因:部分图片质量问题,图片本身大小不能被识别。
解决方法:去label文件夹下查看最后一个txt文件,他的大小是0kb

该文件对应的图片就是问题图片,直接查看图片属性,将宽高手动写入文件对应的xml文件中。

import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join sets=[('2019', 'train'), ('2019', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] classes = ["extinguisher"] def convert(size, box): dw = 1./size[0] dh = 1./size[1] x = (box[0] + box[1])/2.0 y = (box[2] + box[3])/2.0 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(year, image_id): in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + ' ') wd = getcwd() for year, image_set in sets: if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)): os.makedirs('VOCdevkit/VOC%s/labels/'%(year)) image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() list_file = open('%s_%s.txt'%(year, image_set), 'w') for image_id in image_ids: list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg '%(wd, year, image_id)) convert_annotation(year, image_id) list_file.close()