内核同步
我们可以把内核看做是不断对请求进行响应的服务器,这些请求可能来自CPU上的进程也可能来自发出中断的外部设备。这时我们会发现内核不是按照顺序执行的,而是交错执行的,因此这些请求可能引起竞争条件,而我们就需要引入适当的同步机制对这种情况进行控制。
内核为何为不同的请求提供服务?
内核控制路径(kernel control path)表示内核处理系统调用、异常或中断所执行的指令序列。每个中断或异常都会引起一个内核控制路径,或者说代表当前进程在内核态执行单独的指令序列。
中断和异常处理程序的嵌套执行:一个中断处理程序可以被另一个中断处理程序“中断”,因此引起内核控制路径的嵌套执行。另外嵌套的内核控制进程路径恢复执行时,需要的所有数据都存放在内核态堆栈中,这个栈毫无疑问是属于当前进程的。
- 注:对于用户进程,其既有用户地址空间中的栈,也有它自己的内核栈。而内核进程就只有内核栈。
- 参考:https://www.cnblogs.com/dormant/p/5456491.html
我们知道内核请求(CPU处于内核态执行)是“交错”的方式执行,因为内核必须满足两种请求(可以看做是请求响应的服务器):
* 一种来自**用户态**进程发出的系统调用或异常。
* 一种是**中断**。我们知道**用户态请求内核服务**,必须先引起一个**异常**,迫使CPU从用户态切换到内核态(这里默认普通的异常和系统调用都是“异常”)。
* 如果CPU在用户态执行,则优先级低于上述两种,可以认为是“空闲”。

内核抢占
- 定义:如果一个进程在执行内核函数时(在内核态运行),允许发生内核切换,这个内核就是可抢占的。
- 特点:1.一个在内核态运行的进程;2.可能被执行内核函数执行期间被另外一个进程取代。(而不是因为在内核执行过程中需要等待资源而导致的计划性进程切换)
- 抢占内核和非抢占内核的区别:
- 进程A执行异常处理程序时(在内核态),一个具备较高优先级的进程B变为了可执行状态。(比如发生了中断请求并且相应的处理程序唤醒了B),抢占内核会发生强制性进程切换,让B取代A,如果内核是非抢占的,则不会发生这种情况。
- 考虑一个执行异常处理程序的进程已经用完了时间配额的情况,抢占内核会使得进程立即被取代,而非抢占则会让进程执行完毕或者自动放弃CPU。
- 无法内核抢占的情况:
- 内核正在执行中断服务例程。(例程是某个系统对外提供的功能接口或服务的集合)
- 可延迟函数被禁止(当内核正在执行软中断或tasklet时经常如此)
- 通过抢占计数器(preempt_count)设置为正数而显式地禁用内核抢占。
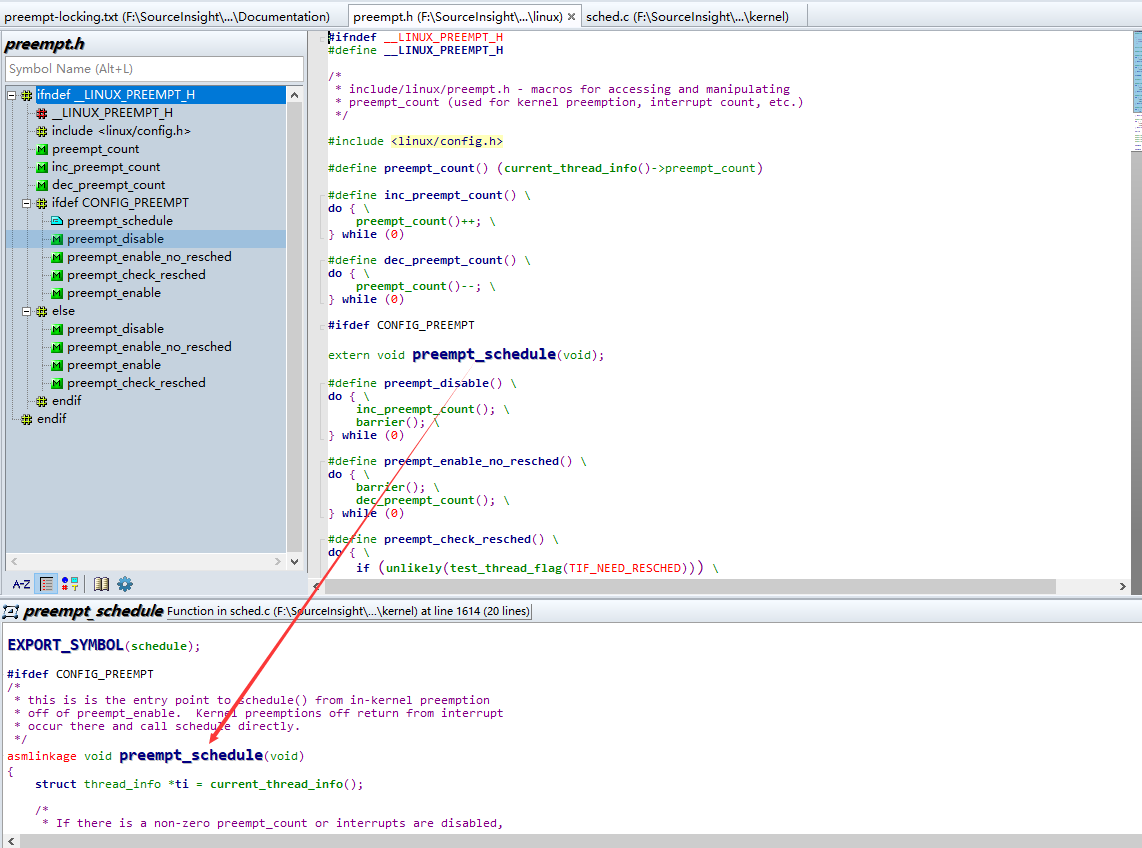
- 可抢占(preemption)内核的头文件位于
./include/linux/preempt.h中,而其中重要的宏函数preempt_schedule()位于./kernel/sched.c中。 preempt_schedule()检查是否允许本地中断,以及当前进程的preempt_count字段是否为0,如果两者都为真,他就调用schedule()选择另外一进程来允许。
什么是时候同步是必需的?
当计算的结果依赖于两个或以上的交错内核控制路径的嵌套方式时就会产生了竞争条件。在其他的内核控制路径能够进入临界区前,进入了临界区的内核控制路径必须全部执行完这段代码。也就是说,一旦进入临界区,就不能再让内核控制路径继续嵌套下去了,否则如果嵌套程序也需要使用相同的资源,则会陷入死锁?
交叉内核控制路径中可能包含异常处理程序、中断处理程序、可延迟函数和内核线程(系统调用)的临界区。一旦临界区被确定,就必须对其采用适当的保护措施,以确保在任意时刻,只有一个内核控制路径处于临界区。
最简单的情况就是单核CPU,当多个中断处理程序要访问同一个包含了几个相关变量的数据结构(比如缓冲区),单核CPU可以采用访问共享数据结构关中断的方式来实现临界区,因为只有在开中断的情况下,才可能发生但是在多处理器系统中,情况要复杂的多,由于许多CPU可能同时执行内核路径,因此
什么时候同步是不必要的?
关于中断和异常的设计可以简化内核函数的编码,具体简化的例子如下:
- 中断程序和tasklet不必编写成可重入函数
- 仅被软中断和tasklet访问的每CPU变量不需要同步
- 仅被一种tasklet访问的数据结构不需要同步
同步原语
内核使用的各种同步技术:
| 技术 | 说明 | 使用范围 |
|---|---|---|
| 每CPU变量(per-cpu variable) | 在CPU之间复制数据结构 | 所有CPU |
| 原子操作 | 对一个计数器原子地“读—改写—写"的指令 | 所有CPU |
| 内存屏障 | 避免指令重新排序 | 本地CPU或所有CPU |
| 自旋锁 | 加锁时忙等 | 所有CPU |
| 加锁时阻塞等待(睡眠) | 所有CPU | |
| 顺序锁 | 基于访问计数器的锁 | 所有CPU |
| 本地中断的禁止 | 禁止单个CPU上的中断处理 | 本地CPU |
| 本地软终端的禁止 | 禁止单个CPU上的可延迟函数处理 | 本地CPU |
| 读—拷贝—写(RCU) | 通过指针而不是锁来访问共享数据结构 | 所有CPU |
注:本地CPU表示只有这一个CPU禁止了,系统的其他CPU则不受影响。
进一步在对内核数据结构的同步访问一节会介绍如何把这些同步技术组合在一起来有效地保护内核结构。
每CPU变量(per-cpu variable)
最简单也是最重要的同步技术包括把内核变量声明为每CPU变量(per-cpu variable)。每CPU变量主要是数据结构的数组,系统的每个CPU对应数组的一个元素。一个CPU不应该访问与其他CPU对应的数组元素,另外,它可以随意读或修改自己的元素而不用担心出现竞争条件,因为他是唯一有资格这么做的CPU。
虽然per-cpu variable为来自不同的CPU的并发访问提供了保护,但对来自异步函数(中断处理程序或可延迟函数)的访问不提供保护,在这种情况下需要另外的同步原语。
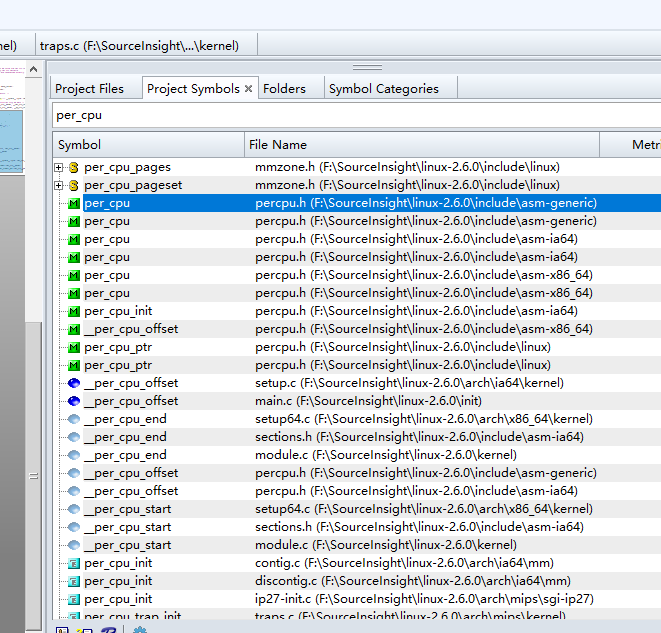
此外,在单核处理器和多核处理器系统中,内核抢占都可能使per-cpu variable产生竞争条件。总的原则是内核控制路径应该在禁止抢占的情况下访问per-cpu variable。(我的理解是假设四核CPU处理四路内核控制路径,那么有一个CPU使用了per-cpu variable,则中这个CPU就不可以被抢占)。针对per_cpu有很多相关定义和操作:
原子操作
在你编写C代码程序时,并不能保证编译器为a++这样的操作使用一个原子指令。因此linux内核专门提供了一个的atomic_t类型和一些专门的函数和宏,这些函数和宏专门用于atomic_t类型的变量,并当做单独的、原子的汇编指令来使用。在多处理器系统中,每条这样的指令都有一个lock字节的前缀。
在汇编语言这一等级上,为了避免由于“读——修改——写”指令引起的竞争条件,最简单的方法就是确保这样的操作是芯片级是原子的。任何一个这样的操作都必须以单个指令执行,中间不能中断,且避免其他的CPU访问同一个存器单元。
在80x86中指令中的原子操作:
- 进行零次或一次对齐内存访问的汇编指令是原子的。
- 在读操作之后,写操作之前没有其他处理器占用内存总线,则“读修改写”操作是原子的,也就是说单核情况下永远不会发生内存总线窃取的情况。
- 在操作码前面添加前缀lock字节(0xf0)来保证多核处理系统中的原子性。这样可以提前“锁定”内存总线。
- 操作码前缀是一个rep字节(0xf2,0xf3)的汇编语言指令不是原子的。
优化屏障(volatile)和内存屏障
总所周知,当使用优化的编译器时,指令可能会改变源码中的出现顺序来执行。因为编译器可能重新安排汇编语言以寄存器以最优的使用方式使用。然而,当处理同步时,必须避免指令重新排序。实际上,所有的同步原语起优化和内存屏障的作用。优化屏障就是防止编译器对内存方法的优化, 内存屏障是为了防止硬件上的指令重排。
优化屏障(optimization barrier)原语保证编译程序不会混淆放在原语操作之前的汇编指令和放在原语操作之后的汇编指令操作。在linux中,优化屏障就是barrier()宏,它展开为asm volatile("":::"memory")。指令asm告诉编译程序要插入汇编语言片段(这种情况下为空的)。即先使用asm指令对这个代码段进行内联汇编,同时使用volatile表示进行对这段内联汇编进行优化。
内存屏障(memory barrier)原语确保,在原语之后的操作开始执行之前,原语之前的操作已经完成。可以防止硬件上的指令重排。因此,内存屏障类似于防火墙,让任何汇编语言指令都不能通过。
自旋锁
当内核控制路径必须访问共享数据资源结构或进入临界区时,就需要为自己获取一把”锁“。由锁机制保护资源非常类似于限制房间内的资源,当某人进入房间时,就把门锁上。
下面一共存在5个内核控制路径(就是5个代码块,不知道PID的代码块指令序列)。执行内核控制路径的时候,可以交错执行,前提是,没有临界区或共享资源。
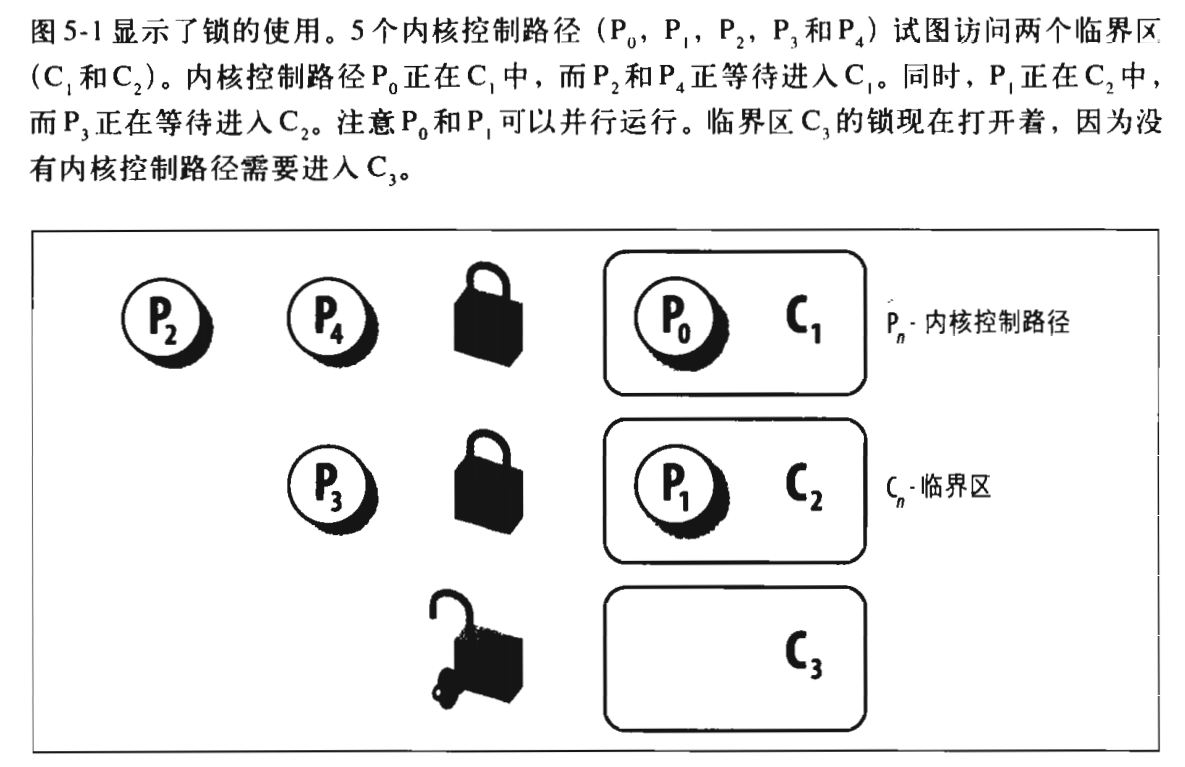
自旋锁(spin lock)是用来在多处理器环境中工作的一种特殊的锁。如果内核控制路径发现自旋锁“开着”,就获取锁并继续自己的执行。相反,如果内核控制路径发现锁由另外一个CPU上的内核控制路径“锁着”,就在周围“旋转”,反复执行一条紧凑的循环指令,直到锁被释放。
自旋锁的循环指令小时“忙等”。即使等待的内核控制路径除了浪费时间无事可做,它也在CPU一直运行。一般来说,由自旋锁所保护的每个临界区是禁止内核抢占的, 在单核系统没有用,主要用于多核系统。请注意,在自旋锁忙等期间,内核抢占还是有效的,因此,等待自旋锁释放的进程有可能被更高优先级的进程代替。
在linux中,每个自旋锁都用spinlock_t结构表示,包括相关方法,其头文件代码位于./include/linux/spinlock.h中:

- 自旋锁和reentrance的关系?
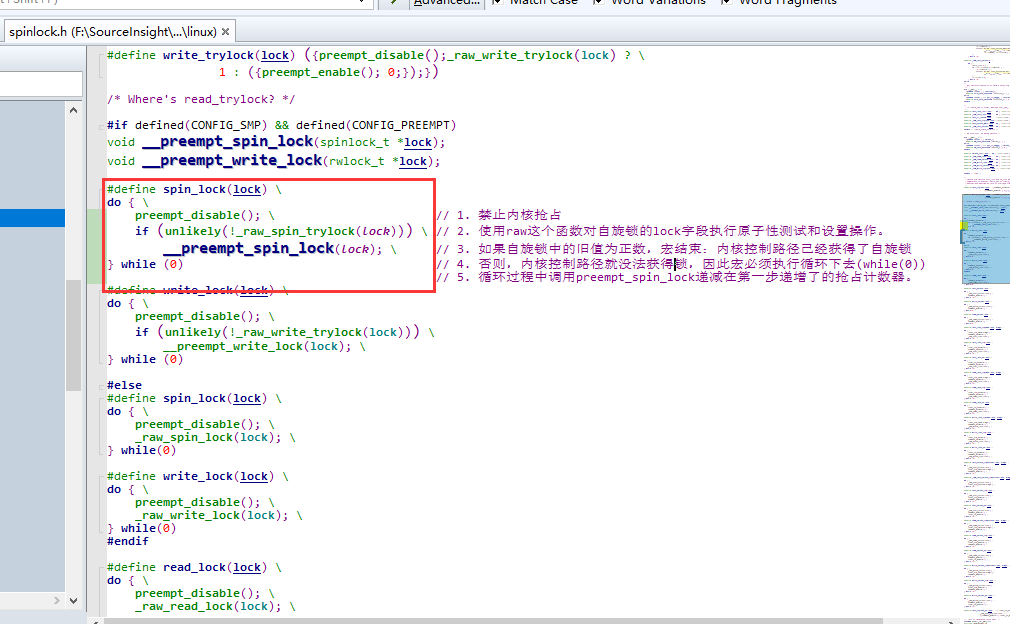
具有内核抢占的spin_lock宏
针对SMP系统的抢占式内核,spin_lock宏获取自旋锁的地址slp作为他的参数,并执行以下操作:
非抢占式内核中的spin_lock宏
略
读/写自旋锁
读/写自旋锁是为了增加内核的并发能力。只要没有内核控制路径对数据进行修改,读/写自旋锁就允许多个内核控制路径同时读同一个数据结构。如果一个内核控制相对这个结构进行写操作, 那么它必须先获取读/写锁的写锁,写锁独占访问这个资源。

顺序锁
当使用读/写自旋锁时,内核控制路径发出的执行read_lock或write_lock操作的请求具有相同的优先权:读者必须等待,直到写操作完成。同样地,写者必须等待读操作完成。
Linux2.6引入了顺序锁(seqlock),它和读写锁相似,只是它赋予写者了较高的优先级。
CRU
信号量
从本质上说,信号量就是对临界区实现了一个加锁原语,即让等待着睡眠,直到等待的资源变为空闲。
实际上,Linux提供两种信号量:
- 内核信号量,由内核控制路径使用
- System V IPC 信号量,由用户态进程使用
内核信号量
内核信号量类似于自旋锁,因为当锁关闭着时,它不允许内核控制路径继续进行(阻塞)。然而,当内核控制路径试图获取内核信号量的锁保护的资源时,相应的进程被挂起。只有在资源被释放时,进程才再次变为可运行。因此,只有可以睡眠的函数才能获取内核信号量,中断处理程序和延迟函数都不能使用内核信号量。
内核信号量是struct semaphore类型的对象,包括count,wait和sleepers三个字段分别表示资源是否空闲,等待队列地址和是否有进程在信号量上睡眠(标志位)。
另外可以使用int_MUTEX()和init_MUTEX_LOCKED()函数来初始化互斥访问所需要的信号量,这两个宏分别把count字段设置为1(互斥访问的资源空闲)和0(对信号量初始化的进程当前互斥访问的资源忙)。如果把信号量中的count初始化为任意正整数n则表示最多可以有n个进程并发地访问这个资源。
注意:count字段存放的值是一个atomic_t类型。
释放信号量:主要就是当进程希望释放内核信号量锁时,调用up()函数。up函数增加*sem信号量的count字段的值,然后检测它是否大于0,如果大于0,说明没有进程在等待队列上睡眠,因为什么也不做。否则,调用__up()函数以唤醒一个睡眠进程。以下是__up()函数:
__attribute__((regparm(3))) void __up(struct semaphore *sem){
wake_up(&sem->wait);
}
获取信号量:当进程希望获取内核信号量锁时,就调用down()函数。down()函数十分复杂,这里简要说明:
* 减少`*sem`信号量的count字段的值
* 检查`count`是否为负,如果大于等于0,则获取资源直接执行,否则当前进程必须挂起。
* 调用`__down()`函数:主要任务是挂起当前进程,直到信号量被释放。具体而言是把当前进程的状态从TASK_RUNNING(运行态)变为TASK_UNINTERRUPTIBLE(不可被中断态?),并把进程放在信号量的等待队列。该函数在访问信号量结构的字段之前,要获得用来保护信号量队列的`sem->wait.lock`自旋锁,并禁止本地中断。
类似于信号量的原语:补充原语
解决up可能访问一个不存在的数据结构的问题(down后释放信号量),具体略。
禁止本地中断
确保一组内核语句被当作一个临界区处理的主要机制之一就是中断禁止。即使当硬件设备产生一组IRQ信号时,中断禁止也让内核控制路径继续执行,这就确保中断处理程序访问的数据结构也受到了保护。
然而,禁止本地中断并不保护运行在另一个CPU上的中断处理程序对数据结构的并发访问,因此在多核系统上,禁止本地中断经常与自旋锁结合使用。
当内核进入临界区时,通过把eflags寄存器的IF标志清0关闭中断。但是,内核经常不能在临界区的末尾简单地再次设置这个标志。中断可以以嵌套的方式执行,所以内核不必知道当前控制路径被执行之前IF标志的值究竟意味着是什么。在这种情况下,控制路径必须保存先前赋给该标志位的值,并在执行结束时恢复他。
禁止和激活可延迟函数(TODO:软中断还没有看完)
”软中断“是在硬件中断处理程序结束时执行可延迟函数的,这个时间点可能是不可预知的。因为,必须保护可延迟函数访问的数据结构使其避免竞争条件。
禁止可延迟函数在一个CPU上执行的一种简单方式就是禁止在那个CPU上的中断。
对内核数据结构的同步访问
同步原语保护共享数据结构避免竞争条件,选择不同的同步原语系统性能会有很大变化,通常情况下,内核开发者采用下述由经验可得到的法则:把系统中的并发度保持在尽可能高的程度。
系统中的并发度又取决于两个主要因素,这要是:
- 同时运转的IO设备数(IO密集型)
- 进行有效工作的CPU数(CPU密集型) --->java线程池的最大线程个数也应该根据这两个原因选择个数。
为了使I/O吞吐量最大化,应该使中断禁止保持在很短的时间。
为了有效地利用CPU,应该尽可能避免使用基于自旋锁的同步原语。当一个CPU执行紧指令循环等待自旋锁打开时,是在浪费宝贵的机器周期。由于自旋锁对硬件高速缓存的影响而使其对系统的整体性能产生不利影响。
维持较高并发度的同时也可以达到同步的方法主要是通过使用内存屏障+原子操作实现的。这应该属于lock free吧?
在自旋锁、信号量及中断禁止之间的选择
一般来说,同步原语的选择取决于访问数据结构的内核控制路径的种类。记住:只要内核控制路径获取了自旋锁(还有读写锁,顺序锁或RCU“读锁”),就禁止本地中断或本地软中断,自动禁止内核抢占。
保护由各种同步原语访问的数据结构
略
避免竞争条件的实例
为了直观地认识内核内部到底是什么样子,需要提及本章所定义同步原语的几种典型用法。
引用计数器
引用计数器广泛地用在内核中以避免由于资源的并发分配和释放而产生的竞争条件。引用计数器(reference counter)只不过是一个atomic_t计数器,与特定的资源(内存页,模块或文件)相关。当内核控制路径开始使用资源时就原子地减少计数器的值。如果用完就放回。如果变为0这说明没人用,如果必要就释放掉。
大内核锁(big kernel block.,BKL )
在2.0版本中,大内核锁是一个相对粗粒度的自旋锁,确保每次只能有一个进程能运行在内核态。
从2.6.11开始,用一个叫做kernel_sem的信号量来实现大内核锁。但是大内核锁比简单的信号量要复杂一些。
每个进程描述符都含有一个lock_depth字段用来防止试图获得大内核锁的异步函数产生死锁。
但是,允许一个持有大内核锁的进程调用schedule(),从而放弃CPU
内核描述符读/写信号量
mm_struct 类型的每个内存描述符在mmap_sem字段中都包含了自己的信号量。由于几个轻量级进程之间可以共享一个内存描述符,因此,信号量保护这个描述符可以避免可能产生的竞争条件。
假设内核必须为了某个进程创建而扩展一个内存区。为了做到这点,内核调用do_mmap()函数分配一个新的vm_area_struct数据结构。在分配过程中,如果没有可用的空闲内存,而共享同一内存描述符的另外一个进程可能正在运行,那么当前进程可能被挂起。如果没有信号量,那么需要访问内存描述符 第二个进程的任何操作(比如由于COW而产生的缺页)都可能会导致严重的数据崩溃。
对于只需要扫描内存描述符的程序(如缺页异常处理程序),其信号量可以使用读/写信号量来实现。
slab高速缓存链表信号量
slab高速缓存描述符链表是通过cache_chain_sem信号量保护的,这个信号量允许互斥地访问和修改该链表。(省略)
索引节点的信号量
linux把磁盘文件的信息存放在inode的内存对象中(内存中为活动inode,磁盘中的是icommon)。响应的数据结构也有包括自己的信号量,存放在i_sem字段中。
在文件系统的处理过程中会出现很多竞争条件。磁盘上的每个文件都是所有用户共有的一种资源,因为所有进程都(可能)会存取文件的内容、修改文件名或者文件位置、删除或复制文件等等。而这些竞争条件都可以通过用索引节点信号量保护目录文件来避免。
只要一个程序使用两个或多个信号量,就存在死锁的可能。因为两个不同的控制路径可能互相死等着释放信号量。例如rename()系统调用的服务历程,其操作就会涉及两个不同的索引节点,因此必须采用两个信号量。为了避免这样的死锁,信号量的请求按预先确地的地址顺序进行。
个人总结
- 内核同步具体问题就是如何保证异常处理程序,中断处理程序,可延迟函数和系统调用的同步。
- 内核同步的起因——内核抢占
- 分为单核同步和多核同步
- 什么时候同步是必须的?什么时候是不必要的?
- 同步原语包括很多,per-cpu variable, 原子操作, 内存屏蔽, 自旋锁, 顺序锁, CRU, 信号量, 补充原语, 禁止本地中断, 禁止和激活可延迟函数。但是面试常考的是以下几种:
- 原子操作
- 内存屏蔽
- 自旋锁
- 顺序锁
- 之所以会有内存屏障,是因为SMP CPU架构下的所有的内存对所有的处理器都是可以访问的,因此会出现内存总线窃取的情况。另外并行架构下,每个CPU都有自己唯一可访问内存(per-cpu variable),处理器间通过消息传递进行通信。
- 内核同步中为互斥锁(mutex)单独开一小章,他属于内核信号量的一种特殊情况,即将内核信号量中的
count字段上线设置为1即可。
补充
- Reentrant:所有的Unix内核都是可重入的,就是说几个进程可能同时在内核模式下执行。在单CPU模式下,系统只能执行一个进程,但是其他在等待的IO操作可以在内核模式下被阻塞。
- 什么是内核控制路径(kernel control path)?与per-cpu variable的关系是什么?
- 内核控制路径是指由内核执行的指令序列(是指令序列不是内核线程,内核线程是invoke的!),包括系统调用代码(一种异常处理程序),异常处理程序代码,中断处理程序代码和内核线程代码。注意:内核控制线程不属于任何进程,没有PID,如果不开启内核抢占,内核控制进程将一直执行到任务完成自动让出CPU。
- 只要进入了内核空间,便是处于以上四种内核控制路径的某一个。
- CPU三大架构:SMP,MPP,NUMA。
- SMP(Symmetric Multiprocessing) , 对称多处理器. 顾名思义, 在SMP中所有的处理器都是对等的, 它们通过总线连接共享同一块物理内存,这也就导致了系统中所有资源(CPU、内存、I/O等)都是共享的,当我们打开服务器的背板盖,如果发现有多个cpu的槽位,但是却连接到同一个内存插槽的位置,那一般就是smp架构的服务器,日常中常见的pc啊,笔记本啊,手机还有一些老的服务器都是这个架构,其架构简单,但是拓展性能非常差,从linux 上也能看到:
- NUMA ( Non-Uniform Memory Access),非均匀访问存储模型,这种模型的是为了解决smp扩容性很差而提出的技术方案,如果说smp 相当于多个cpu 连接一个内存池导致请求经常发生冲突的话,numa 就是将cpu的资源分开,以node 为单位进行切割,每个node 里有着独有的core ,memory 等资源,这也就导致了cpu在性能使用上的提升,但是同样存在问题就是2个node 之间的资源交互非常慢,当cpu增多的情况下,性能提升的幅度并不是很高。所以可以看到很多明明有很多core的服务器却只有2个node区。
- MPP (Massive Parallel Processing) ,这个其实可以理解为刀片服务器,每个刀扇里的都是一台独立的smp架构服务器,且每个刀扇之间均有高性能的网络设备进行交互,保证了smp服务器之间的数据传输性能。相比numa 来说更适合大规模的计算,唯一不足的是,当其中的smp 节点增多的情况下,与之对应的计算管理系统也需要相对应的提高。
- 参考:https://www.jianshu.com/p/81233f3c2c14
- SMP(Symmetric Multiprocessing) , 对称多处理器. 顾名思义, 在SMP中所有的处理器都是对等的, 它们通过总线连接共享同一块物理内存,这也就导致了系统中所有资源(CPU、内存、I/O等)都是共享的,当我们打开服务器的背板盖,如果发现有多个cpu的槽位,但是却连接到同一个内存插槽的位置,那一般就是smp架构的服务器,日常中常见的pc啊,笔记本啊,手机还有一些老的服务器都是这个架构,其架构简单,但是拓展性能非常差,从linux 上也能看到: