Eager essentials
Eager 要领
Tensorflow的eager execution 是一个命令式编程环境(imperative programming environment),他可以运算返回具体值,而不是构建计算图形以便稍后运行。这样可以轻松的使用TensorFlow和调试模型,并且还可以减少样板。
Eager execution是一个灵活的机器学习研究和实验的平台,他提供:
- An intuitive interface(直观的界面)——自然地构建python代码并使用python数据结构。快速地迭代小型模型和小型的数据集。
- Easily debugging(容易调试)——直接调用ops(操作)来检查运行模型或测试更改。使用标准的python调试工具进行及时错误报告。
natural control flow(自然的控制流)——使用python控制流而不是计算图控制流,简化了动态模型的规范。
安装与基本使用
from __future__ import absolute_import, division, print_function, unicode_literals !pip install -q tensorflow-gpu==2.0.0-beta1 import tensorflow as tf import cProfile
而在TensorFlow2.0中,eager是默认开启的。
tf.executing_eagerly() # 改名返回eager mode
如果eager打开,你可以运行TensorFlow操作并且立刻返回结果:
x = [[2.]] m = tf.matmul(x, x) print("hello, {}".format(m)) # hello,[[4.]]
打开eager execution会改变TensorFlow的操作行为——现在他们直接计算并返回他们的值给python。tf.tensor的对象是指的具体的值而非计算图中的符号句柄。由于在会话(session)中没有构建计算图,因此使用print()或调试器检查结果很容易。计算,打印和检查Tensor的值不会破坏计算梯度的flow。
eager execution与numpy很好协作。numpy操作接受tf.tensor参数。TensorFlow数学运算将python对象和numpy数组转换为tf.tensor对象。tf.tensor.numpy方法将对象的值作为numpy ndarray返回。
另外,eagerexecution支持broadcasting。运算符重载:
a = tf.constant([[1,2], [3,4] ]) print(a) # a tensor include(matrix,shape=(2,2),dtype=int32) b = tf.add(a,1) print(b) # broadingcasting-> [[2,3],[4,5]] print(a*b) # operator overloading import numpy as np c = np.multiply(a,b) # use numpy values print(c) print(a.numpy()) # tensor->numpy
动态控制流
使用eager execution的一个好处是在执行模型时可以使用host language的全部功能,例如:
def fizzbuzz(max_num): counter = tf.constant(0) max_num = tf.convert_to_tensor(max_num) for num in range(1, max_num.numpy()+1): num = tf.constant(num) if int(num % 3) == 0 and int(num % 5) == 0: print('FizzBuzz') elif int(num % 3) == 0: print('Fizz') elif int(num % 5) == 0: print('Buzz') else: print(num.numpy()) counter += 1
fizzbuzz(15) # 1 2 Fizz
Eager training
Computing gradients
自动微分(automatic differentiation)在机器学习算法中是非常有用的,比如在神经网络中的反向传播(backpropagation)。在eager execution中,使用tf.GradienTape来跟踪稍后计算梯度的操作。
你可以用tf.GradientTape在eager中训练或计算梯度。这在负载的训练循环中非常有用。
因为在每次发生调用(call)的时候,都可能发生不同的操作,所有的钱向传播都记录到了一个“tape”中, 为了计算梯度,将tape反向“播放”然后丢弃掉。一个特定的tf.GradientTape只能计算一次梯度,后续调用会引发运行时的错误。(没懂)
训练模型train a model
下面这个例子创建了一个多层模型,对于标准的MNIST手写数字进行分类。他演示了在eager执行环境下优化器和卷积池化层之类的API构建可训练计算图。
# Fetch and format the mnist data (mnist_images, mnist_labels), _ = tf.keras.datasets.mnist.load_data() dataset = tf.data.Dataset.from_tensor_slices( (tf.cast(mnist_images[...,tf.newaxis]/255, tf.float32), tf.cast(mnist_labels,tf.int64))) dataset = dataset.shuffle(1000).batch(32) # Build the model mnist_model = tf.keras.Sequential([ tf.keras.layers.Conv2D(16,[3,3], activation='relu', input_shape=(None, None, 1)), tf.keras.layers.Conv2D(16,[3,3], activation='relu'), tf.keras.layers.GlobalAveragePooling2D(), tf.keras.layers.Dense(10) ]) # Even without training, call the model and inspect the output in eager execution: for images,labels in dataset.take(1): print("Logits: ", mnist_model(images[0:1]).numpy())
虽然keras模型具有内置训练循环(使用fit方法),有时候你需要更多自定义,这是一个用eager实现循环的例子:
optimizer = tf.keras.optimizers.Adam() loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) loss_history = [] def train_step(images, labels): with tf.GradientTape() as tape: logits = mnist_model(images, training=True) # Add asserts to check the shape of the output. tf.debugging.assert_equal(logits.shape, (32, 10)) loss_value = loss_object(labels, logits) loss_history.append(loss_value.numpy().mean()) grads = tape.gradient(loss_value, mnist_model.trainable_variables) optimizer.apply_gradients(zip(grads, mnist_model.trainable_variables)) def train(): for epoch in range(3): for (batch, (images, labels)) in enumerate(dataset): train_step(images, labels) print ('Epoch {} finished'.format(epoch)) train() # Epoch 0 finished;Epoch 1 finished ...
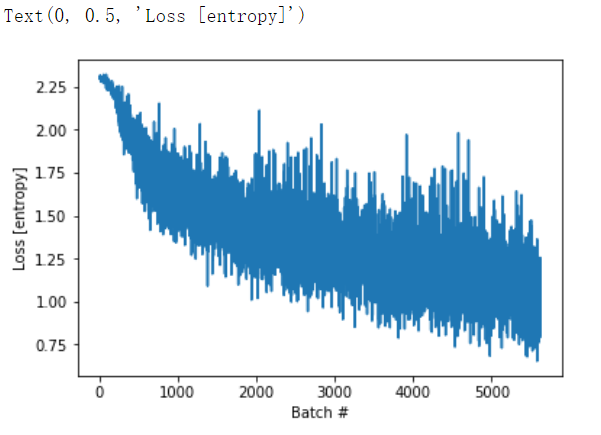
import matplotlib.pyplot as plt plt.plot(loss_history) plt.xlabel('Batch #') plt.ylabel('Loss [entropy]')
Variables and optimizers
在训练期间tf.Variable对象存储mutable(可变的)tf.Tensor的值,可以使得自动微分更加简单,模型的参数可以作为变量封装在类中。
使用tf.Variable和tf.GradientTape更好地封装模型参数。例如,可以在自动微分的例子上进行重写:


class Model(tf.keras.Model): def __init__(self): super(Model, self).__init__() self.W = tf.Variable(5., name='weight') self.B = tf.Variable(10., name='bias') def call(self, inputs): return inputs * self.W + self.B # A toy dataset of points around 3 * x + 2 NUM_EXAMPLES = 2000 training_inputs = tf.random.normal([NUM_EXAMPLES]) noise = tf.random.normal([NUM_EXAMPLES]) training_outputs = training_inputs * 3 + 2 + noise # The loss function to be optimized def loss(model, inputs, targets): error = model(inputs) - targets return tf.reduce_mean(tf.square(error)) def grad(model, inputs, targets): with tf.GradientTape() as tape: loss_value = loss(model, inputs, targets) return tape.gradient(loss_value, [model.W, model.B]) # Define: # 1. A model. # 2. Derivatives of a loss function with respect to model parameters. # 3. A strategy for updating the variables based on the derivatives. model = Model() optimizer = tf.keras.optimizers.SGD(learning_rate=0.01) print("Initial loss: {:.3f}".format(loss(model, training_inputs, training_outputs))) # Training loop for i in range(300): grads = grad(model, training_inputs, training_outputs) optimizer.apply_gradients(zip(grads, [model.W, model.B])) if i % 20 == 0: print("Loss at step {:03d}: {:.3f}".format(i, loss(model, training_inputs, training_outputs))) print("Final loss: {:.3f}".format(loss(model, training_inputs, training_outputs))) print("W = {}, B = {}".format(model.W.numpy(), model.B.numpy()))
Use objects for state during eager execution
在TF1.x的计算图执行的时候,程序状态(例如 variables)是存储在全局集合中的,其生命周期是由tf.Session对象管理的。相反,在eager模式下,程序状态对象的生命周期是由其相应的python对象的生命周期决定的。
Variables are objects
在eager模式期间,variables在对象的最后一个引用被删除之前将一直存在而不被删除。.
if tf.test.is_gpu_available(): with tf.device("gpu:0"): print("GPU enabled") v = tf.Variable(tf.random.normal([1000, 1000])) v = None # v no longer takes up GPU memory
object-based saving 基于对象的保存检查点
这一节是培训检查点指南的缩写版本。
tf.train.Checkpoint 可以用来save和restore tf.Variables to/from checkpoint:
(变量保存和恢复)
# 首先创建一变量,并常见保存点变量 x = tf.Variable(10.) checkpoint = tf.train.Checkpoint(x=x) x.assign(2.) #赋给x一个新的值,并保存 checkpoint_path = './ckpt/' checkpoint.save('./ckpt/') # 这个地方是./ckpt/而不是./ckpt。 # 所以保存在./ckpt/ 目录下的 -1文件中。 # 如果是./ckpt,则直接保存在当前目录的ckpt-1的文件中 x.assign(11.) # Change the variable after saving. # Restore values from the checkpoint checkpoint.restore(tf.train.latest_checkpoint(checkpoint_path)) print(x) # =><tf.Variable 'Variable:0' shape=() dtype=float32, numpy=2.0>
为了保存和恢复模型,tf.train.Checkpoint存储对象的内部状态,而不需要隐藏变量。要记录一个模型的状态,优化器,以及全局步骤,也需要通过tf.train.Checkpoint来保存:
(模型的保存和恢复)
# save and restore model import os model = tf.keras.Sequential([ tf.keras.layers.Conv2D(16,[3,3],activation='relu'), tf.keras.layers.GlobalAveragePooling2D(), tf.keras.layers.Dense(10) ]) optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) checkpoint_dir = 'path/to/model_dir' if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) checkpoint_prefix = os.path.join(checkpoint_dir,'ckpt') # print(checkpoint_prefix) # path/to/model_dir/ckpt root = tf.train.Checkpoint(optimizer=optimizer,model=model) root.save(checkpoint_prefix) # ./path/to/ckpt-1.xxxx root.restore(tf.train.latest_checkpoint(checkpoint_dir)) # 恢复变量
注意:在许多训练循环中,在调用tf.train.Checkpoint.restore之后创建变量。 这些变量将在创建后立即恢复,并且可以使用断言来确保检查点已完全加载。 有关详细信息,请参阅培训检查点指南。
高级自动微分主题
相关推荐阅读:https://www.cnblogs.com/richqian/p/4549590.html
https://www.cnblogs.com/richqian/p/4534356.html
https://www.jianshu.com/p/fe2e7f0e89e5
Dynamic models
tf.GradientTape也可用于动态模型。 这是回溯线搜索算法(backtracking line search alg)的示例,尽管控制流很复杂,但它看起来像普通的NumPy代码,除了有自动微分是可区分的:(不会)
def line_search_step(fn, init_x, rate=1.0): with tf.GradientTape() as tape: # Variables are automatically recorded, but manually watch a tensor tape.watch(init_x) value = fn(init_x) grad = tape.gradient(value, init_x) grad_norm = tf.reduce_sum(grad * grad) init_value = value while value > init_value - rate * grad_norm: x = init_x - rate * grad value = fn(x) rate /= 2.0 return x, value
Custom gradients(自定义梯度)
自定义梯度是一种重写梯度的简单方法。根据输入,输出或结果定义梯度。例如这有一种在后向传递中剪切渐变范数的简单方法:
@tf.custom_gradient def clip_gradient_by_norm(x, norm): y = tf.identity(x) def grad_fn(dresult): return [tf.clip_by_norm(dresult, norm), None] return y, grad_fn # 自定义梯度通常用于为一系列操作提供数值稳定的梯度: def log1pexp(x): return tf.math.log(1 + tf.exp(x)) def grad_log1pexp(x): with tf.GradientTape() as tape: tape.watch(x) value = log1pexp(x) return tape.gradient(value, x) # The gradient computation works fine at x = 0. grad_log1pexp(tf.constant(0.)).numpy()
Performance
在eager模式下,计算会自动卸载(offload)到GPU,如果要控制 计算运行的设备,你可以使用tf.device(/gpu:0)快(或等效的CPU设备)中把他包含进去。
import time def measure(x, steps): # TensorFlow initializes a GPU the first time it's used, exclude from timing. tf.matmul(x, x) start = time.time() for i in range(steps): x = tf.matmul(x, x) # tf.matmul can return before completing the matrix multiplication # (e.g., can return after enqueing the operation on a CUDA stream). # The x.numpy() call below will ensure that all enqueued operations # have completed (and will also copy the result to host memory, # so we're including a little more than just the matmul operation # time). _ = x.numpy() end = time.time() return end - start # shape = (1000, 1000)
shape = (50, 50) # 我的电脑貌似只能跑50的,超过100jupyter notebook就会挂掉,另外 我依然不会查看GPU使用率 steps = 200 print("Time to multiply a {} matrix by itself {} times:".format(shape, steps)) # Run on CPU: with tf.device("/cpu:0"): print("CPU: {} secs".format(measure(tf.random.normal(shape), steps))) # Run on GPU, if available: if tf.test.is_gpu_available(): with tf.device("/gpu:0"): print("GPU: {} secs".format(measure(tf.random.normal(shape), steps))) else: print("GPU: not found")
一个tf.tensor对象可以复制到不同的设备上去执行操作:
if tf.test.is_gpu_available(): x = tf.random.normal([10, 10]) x_gpu0 = x.gpu() x_cpu = x.cpu() _ = tf.matmul(x_cpu, x_cpu) # Runs on CPU _ = tf.matmul(x_gpu0, x_gpu0) # Runs on GPU:0