iceberg 0.11 发布的时候稍微尝试了一下,发现实际并没有说的那么厉害,很多功能其实还在开发中(比如: upsert)
贴段之前写的 flink sql:
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# Start the flink standalone cluster
./bin/start-cluster.sh
./sql-client.sh embedded -j ../lib/iceberg-flink-runtime-0.11.1.jar shell
CREATE CATALOG t_iceberg_hadoop_catalog_1 WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://thinkpad:8020/tmp/iceberg/flink/t_iceberg_hadoop_catalog_1',
'property-version'='1'
);
# 这样也可以
CREATE CATALOG t_iceberg_hadoop_catalog_2 WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='file:///tmp/hadoop_catelog/t_iceberg_hadoop_catalog_2',
'property-version'='1'
);
CREATE DATABASE iceberg_db;
USE iceberg_db;
CREATE TABLE iceberg_db.t_iceberg_sample_1 (
id BIGINT COMMENT 'unique id',
data STRING
)WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://thinkpad:8020/tmp/iceberg/flink/hadoop_catalog/iceberg_db/t_iceberg_sample_1',
'property-version'='1'
);
# insert into iceberg_db.t_iceberg_sample_1(id, data) values(10, '2021-04-29 17:38:00'); # 失败
SELECT * FROM iceberg_db.t_iceberg_sample_1 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
注: 貌似没有 hive catalog,只能放在 hadoop 上面,不支持 upsert
iceberg master
github 下载 iceberg master 代码,编译了 Flink 1.14、1.13 版本(1.14 遇到包冲突,本次使用 1.13 版本)
iceberg 的包管理工具是 gradle,编译后 iceberg 的包在 : iceberg/flink/v1.13/flink-runtime/build/libs/iceberg-flink-runtime-1.13-0.13.0-SNAPSHOT.jar
把包放到 flink lib 目录:
/opt/flink-1.13.2$ ls lib/
flink-connector-hbase-2.2_2.11-1.13.2.jar flink-json-1.13.2.jar hbase-client-2.1.1.jar hbase-shaded-protobuf-2.1.0.jar log4j-api-2.12.1.jar
flink-connector-hbase-base_2.11-1.13.2.jar flink-shaded-hadoop-2-uber-2.8.3-10.0.jar hbase-common-2.1.1.jar htrace-core4-4.2.0-incubating.jar log4j-core-2.12.1.jar
flink-connector-kafka_2.11-1.13.2.jar flink-shaded-zookeeper-3.4.14.jar hbase-protocol-2.1.1.jar hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar log4j-slf4j-impl-2.12.1.jar
flink-connector-mysql-cdc-1.4.0.jar flink-sql-connector-hive-2.3.6_2.11-1.13.2.jar hbase-protocol-shaded-2.1.1.jar iceberg-flink-runtime-1.13-0.13.0-SNAPSHOT.jar metrics-core-3.2.1.jar
flink-csv-1.13.2.jar flink-table_2.11-1.13.2.jar hbase-shaded-miscellaneous-2.1.0.jar kafka-clients-2.2.0.jar
flink-dist_2.11-1.13.2.jar flink-table-blink_2.11-1.13.2.jar hbase-shaded-netty-2.1.0.jar log4j-1.2-api-2.12.1.jar
注意:如果要使用 hive catalog 需要 flink-sql-connector-hive 对应版本的 jar 包
启动 hive server2 & matestore
hive --service metastore
hive --service hiveserver2
启动前别忘了先把 hive 的数据库启动起来
flink sql-client 启动 iceberg 任务
建表语句:
CREATE CATALOG ice WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://thinkpad:9083',
'clients'='5',
'property-version'='2',
'warehouse'='hdfs://thinkpad:8020/user/hive/datalake/ice'
);
-- use catalog
use catalog ice;
-- create database
create database ice;
-- use database;
use ice;
-- create iceberg table
CREATE TABLE ice1.ice.user_log_sink (
user_id STRING
,item_id STRING
,category_id STRING
,behavior STRING
,ts timestamp(3)
,PRIMARY KEY (user_id) NOT ENFORCED
);
写 iceberg
启动 yarn-session
@thinkpad:/opt/flink-1.13.2$ ./bin/yarn-session.sh -d -nm ice
# 使用启动 yarn application 启动 sql-client
@thinkpad:/opt/flink-1.13.2$ ./bin/sql-client.sh embedded -s application_1640912648992_0001
执行 sql,读取 kafka 数据,写入 iceberg
## 创建 catalog
Flink SQL> CREATE CATALOG ice WITH (
> 'type'='iceberg',
> 'catalog-type'='hive',
> 'uri'='thrift://thinkpad:9083',
> 'clients'='5',
> 'property-version'='2',
> 'warehouse'='hdfs://thinkpad:8020/user/hive/datalake/ice'
> );
[INFO] Execute statement succeed.
Flink SQL> use catalog ice;
[INFO] Execute statement succeed.
Flink SQL> show databases;
+------------------+
| database name |
+------------------+
| default |
| default_database |
| dl_ods |
| flink |
| ice |
+------------------+
5 rows in set
Flink SQL> use ice;
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE ice.ice.user_log_sink (
> user_id STRING
> ,item_id STRING
> ,category_id STRING
> ,behavior STRING
> ,ts timestamp(3)
> ,PRIMARY KEY (user_id) NOT ENFORCED
> );
[INFO] Execute statement succeed.
# 切换到 default catalog,创建 kakfa 表
Flink SQL> use catalog default_catalog;
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE user_log (
> user_id VARCHAR
> ,item_id VARCHAR
> ,category_id VARCHAR
> ,behavior VARCHAR
> ,ts TIMESTAMP(3)
> ,WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
> ) WITH (
> 'connector' = 'kafka'
> ,'topic' = 'user_log'
> ,'properties.bootstrap.servers' = 'localhost:9092'
> ,'properties.group.id' = 'user_log'
> ,'scan.startup.mode' = 'latest-offset'
> ,'format' = 'json'
> );
[INFO] Execute statement succeed.
## 执行 insert 语句
Flink SQL> insert into ice.ice.user_log_sink
> SELECT user_id, item_id, category_id, behavior, ts
> FROM user_log;
[INFO] Submitting SQL update statement to the cluster...
2021-12-31 09:41:17,315 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/flink-1.13.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-12-31 09:41:17,361 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at thinkpad/127.0.0.1:8032
2021-12-31 09:41:17,427 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-12-31 09:41:17,428 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2021-12-31 09:41:17,444 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface localhost:41255 of application 'application_1640912648992_0001'.
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: e2da288cd6e2c7919420c74d555e6ad7
查看 flink web ui:
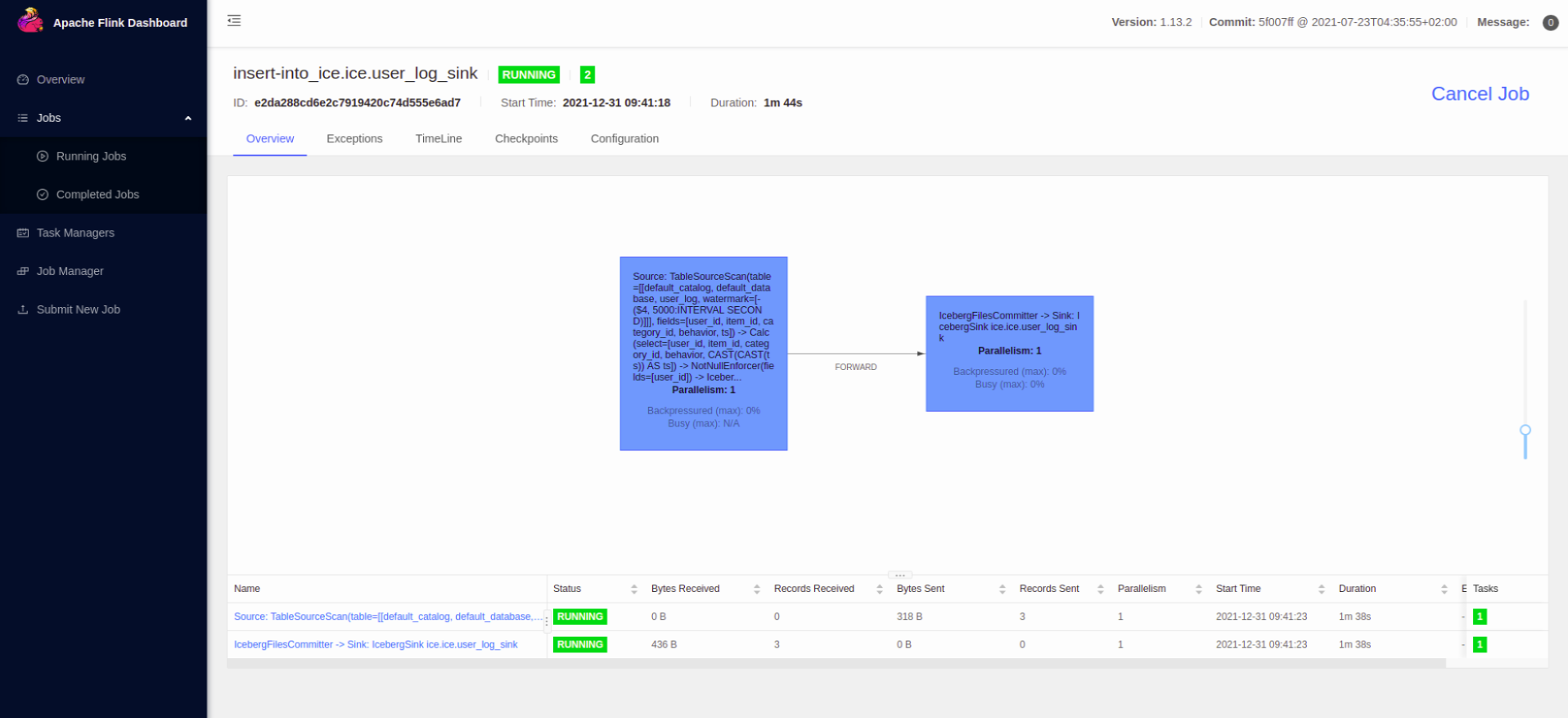
注意: Checkpoint: flink 任务 checkpoint 的时候才真正往 iceberg 写数据
直接在 sql-client 写入数据:
Flink SQL> insert into ice.ice.user_log_sink values('1','item','catagroy','behavior',now());
[INFO] Submitting SQL update statement to the cluster...
2021-12-31 09:49:03,336 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at thinkpad/127.0.0.1:8032
2021-12-31 09:49:03,336 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-12-31 09:49:03,337 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2021-12-31 09:49:03,339 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface localhost:41255 of application 'application_1640912648992_0001'.
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 372572a67492c0f5fcef827309c0d4ff
kafka 写入数据样例:
{"category_id":52,"user_id":"1","item_id":"52","behavior":"pv","ts":"2021-12-31 09:54:42.617"}
{"category_id":14,"user_id":"2","item_id":"114","behavior":"pv","ts":"2021-12-31 09:54:43.849"}
{"category_id":61,"user_id":"3","item_id":"61","behavior":"buy","ts":"2021-12-31 09:54:44.852"}
{"category_id":41,"user_id":"4","item_id":"341","behavior":"pv","ts":"2021-12-31 09:54:45.853"}
{"category_id":71,"user_id":"5","item_id":"471","behavior":"buy","ts":"2021-12-31 09:54:46.855"}
读 iceberg
再开一个 sql-client 查看写入 iceberg 的数据
Flink SQL> CREATE CATALOG ice WITH (
> 'type'='iceberg',
> 'catalog-type'='hive',
> 'uri'='thrift://thinkpad:9083',
> 'clients'='5',
> 'property-version'='1',
> 'warehouse'='hdfs://thinkpad:8020/user/hive/datalake/ice'
> );
[INFO] Execute statement succeed.
Flink SQL> use catalog ice;
[INFO] Execute statement succeed.
Flink SQL> show databases;
+------------------+
| database name |
+------------------+
| default |
| default_database |
| dl_ods |
| flink |
| ice |
+------------------+
5 rows in set
Flink SQL> use ice;
[INFO] Execute statement succeed.
Flink SQL> show tables;
+---------------+
| table name |
+---------------+
| flink_table |
| sample |
| user_log_sink |
+---------------+
3 rows in set
Flink SQL> SET table.dynamic-table-options.enabled=true;
[INFO] Session property has been set.
Flink SQL> SELECT * FROM user_log_sink /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
2021-12-31 09:48:02,948 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/flink-1.13.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-12-31 09:48:02,995 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at thinkpad/127.0.0.1:8032
2021-12-31 09:48:03,066 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-12-31 09:48:03,067 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2021-12-31 09:48:03,081 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface localhost:41255 of application 'application_1640912648992_0001'.
[INFO] Result retrieval cancelled.

iceberg upsert 功能
比较遗憾的是 iceberg 最新 release 版本 0.12.1 flink 还不支持 upsert 功能
master 版本 flink sql 已经支持流式写入的 upsert(表设置主键,添加表属性: 'format-version' = '2' 和 'write.upsert.enabled' = 'true') 功能,但是比较遗憾的是,还没有支持流式的读取 upsert 的表,只能 batch 读
upsert 建表语句:
CREATE CATALOG ice WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://thinkpad:9083',
'clients'='5',
'property-version'='2',
'warehouse'='hdfs://thinkpad:8020/user/hive/datalake/ice.db'
);
CREATE TABLE ice.ice.user_log_sink (
user_id STRING
,item_id STRING
,category_id STRING
,behavior STRING
,ts timestamp(3)
,PRIMARY KEY (user_id) NOT ENFORCED
)WITH (
'format-version' = '2'
,'write.upsert.enabled' = 'true'
);
-- streaming sql, insert into mysql table
insert into ice.ice.user_log_sink
SELECT user_id, item_id, category_id, behavior, ts
FROM user_log
写入数据:
{"category_id":97,"user_id":"2","item_id":"97","behavior":"pv","ts":"2022-01-05 10:18:50.445"}
{"category_id":11,"user_id":"3","item_id":"911","behavior":"cart","ts":"2022-01-05 10:18:51.447"}
{"category_id":7,"user_id":"4","item_id":"607","behavior":"pv","ts":"2022-01-05 10:18:52.450"}
{"category_id":31,"user_id":"5","item_id":"131","behavior":"pv","ts":"2022-01-05 10:18:53.453"}
{"category_id":79,"user_id":"6","item_id":"579","behavior":"buy","ts":"2022-01-05 10:18:54.455"}
{"category_id":79,"user_id":"7","item_id":"79","behavior":"cart","ts":"2022-01-05 10:18:55.459"}
{"category_id":85,"user_id":"8","item_id":"185","behavior":"buy","ts":"2022-01-05 10:18:56.463"}
{"category_id":74,"user_id":"9","item_id":"174","behavior":"pv","ts":"2022-01-05 10:18:57.464"}
{"category_id":50,"user_id":"10","item_id":"950","behavior":"pv","ts":"2022-01-05 10:18:58.466"}
批模式查询:
# 开启动态参数
SET table.dynamic-table-options.enabled=true;
# 设置 批 模式,需要关闭 checkpoint
SET execution.runtime-mode = batch;
# 查询表
select * from ice.ice.user_log_sink;
sql 查询结果:

继续写数据,看upsert 结果(看数据时间)

异常
iceberg v1 表设置主键,有重复数据报错:
2021-12-29 17:15:59
java.lang.IllegalArgumentException: Cannot write delete files in a v1 table
at org.apache.iceberg.ManifestFiles.writeDeleteManifest(ManifestFiles.java:154)
at org.apache.iceberg.SnapshotProducer.newDeleteManifestWriter(SnapshotProducer.java:374)
at org.apache.iceberg.MergingSnapshotProducer.lambda$newDeleteFilesAsManifests$8(MergingSnapshotProducer.java:631)
at java.util.HashMap.forEach(HashMap.java:1289)
at org.apache.iceberg.MergingSnapshotProducer.newDeleteFilesAsManifests(MergingSnapshotProducer.java:628)
at org.apache.iceberg.MergingSnapshotProducer.prepareDeleteManifests(MergingSnapshotProducer.java:614)
at org.apache.iceberg.MergingSnapshotProducer.apply(MergingSnapshotProducer.java:490)
at org.apache.iceberg.SnapshotProducer.apply(SnapshotProducer.java:164)
at org.apache.iceberg.SnapshotProducer.lambda$commit$2(SnapshotProducer.java:283)
at org.apache.iceberg.util.Tasks$Builder.runTaskWithRetry(Tasks.java:405)
at org.apache.iceberg.util.Tasks$Builder.runSingleThreaded(Tasks.java:215)
at org.apache.iceberg.util.Tasks$Builder.run(Tasks.java:199)
at org.apache.iceberg.util.Tasks$Builder.run(Tasks.java:191)
at org.apache.iceberg.SnapshotProducer.commit(SnapshotProducer.java:282)
at org.apache.iceberg.flink.sink.IcebergFilesCommitter.commitOperation(IcebergFilesCommitter.java:312)
at org.apache.iceberg.flink.sink.IcebergFilesCommitter.commitDeltaTxn(IcebergFilesCommitter.java:299)
at org.apache.iceberg.flink.sink.IcebergFilesCommitter.commitUpToCheckpoint(IcebergFilesCommitter.java:218)
at org.apache.iceberg.flink.sink.IcebergFilesCommitter.initializeState(IcebergFilesCommitter.java:153)
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.initializeOperatorState(StreamOperatorStateHandler.java:118)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:290)
at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:441)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:582)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55)
at org.apache.flink.streaming.runtime.tasks.StreamTask.executeRestore(StreamTask.java:562)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:647)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:537)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:759)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)
at java.lang.Thread.run(Thread.java:748)
解决: iceberg v1 表不支持 upsert
flink sql 流式读 iceberg v2 表
2022-01-05 09:11:07
java.lang.UnsupportedOperationException: Found overwrite operation, cannot support incremental data in snapshots (178025383574913414, 6013983871507259597]
at org.apache.iceberg.IncrementalDataTableScan.snapshotsWithin(IncrementalDataTableScan.java:121)
at org.apache.iceberg.IncrementalDataTableScan.planFiles(IncrementalDataTableScan.java:73)
at org.apache.iceberg.BaseTableScan.planTasks(BaseTableScan.java:204)
at org.apache.iceberg.DataTableScan.planTasks(DataTableScan.java:30)
at org.apache.iceberg.flink.source.FlinkSplitGenerator.tasks(FlinkSplitGenerator.java:86)
at org.apache.iceberg.flink.source.FlinkSplitGenerator.createInputSplits(FlinkSplitGenerator.java:38)
at org.apache.iceberg.flink.source.StreamingMonitorFunction.monitorAndForwardSplits(StreamingMonitorFunction.java:143)
at org.apache.iceberg.flink.source.StreamingMonitorFunction.run(StreamingMonitorFunction.java:121)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:66)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:269)
解决: iceberg v2 表现在只支持 batch 模式读,流读的pr 还是 review: https://github.com/apache/iceberg/pull/3095
- 注: v1/v2 表代表 iceberg 表 flink 写入版本,v1 不支持 upsert,v2 是新版本支持 upsert
完整sql 参考: github sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
