安装跟卸载
Mysql安装
下载Mysql源安装包
1 wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
yum安装mysql源
2 yum localinstall mysql57-community-release-el7-8.noarch.rpm -y
检查mysql源是否安装成功
3 yum repolist enabled | grep "mysql.*-community.*"
yum安装Mysql
4 yum install mysql-community-server -y
启动Mysql服务
5 systemctl start mysqld
并添加开机启动
systemctl enable mysqld systemctl daemon-reload
查看Mysql状态
6 systemctl status mysqld
查看默认的mysql密码
此时Mysql安装完成!!!
接下来修改密码
查看默认的mysql密码
7 vi /var/log/mysqld.log
修改mysql的密码
登录mysql: mysql -uroot -p 回车
密码: =>g6hj.Nx4e (上面查看的原始密码)
8 set password for 'root'@'localhost'=password(soy@3975');
9 添加远程登陆的用户权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'Jamie@3975' WITH GRANT OPTION;
FLUSH PRIVILEGES;
10 修改mysql字符编码
vi /etc/my.cnf
添加
character_set_server=utf8
init_connect='SET NAMES utf8'
11 重启Mysql
systemctl stop mysqld
systemctl start mysqld
12 查看Mysql字符集
show variables like '%character%'
Mysql卸载
rpm -qa|grep -i mysql
yum remove mysql-community-server -y
rpm -ev mysql-community-libs-5.7.24-1.el7.x86_64 --nodeps
删除文件
find / -name mysql
rm -rf /var/lib/mysql
rm -rf /etc/my.cnf
Mysql docker安装
docker run --name mysql3307 -p 3307:3306 --privileged=true -ti -e MYSQL_ROOT_PASSWORD=123456 -e MYSQL_DATABASE=enjoy -e MYSQL_USER=user -e MYSQL_PASSWORD=pass -v /home/mysql/docker-data/3307/conf:/etc/mysql/conf.d -v /home/mysql/docker-data/3307/data/:/var/lib/mysql -v /home/mysql/docker-data/3307/logs/:/var/log/mysql -d mysql:5.7
为什么要做数据库扩展
数据库扩展解决了什么问题?
热备份,多活,故障切换
负载均衡、读写分离
Replication常用架构
常规复制架构(Master --- Slaves)
在实际应用场景中,MySQL 复制 90% 以上都是一个 Master 复制到一个或者多个Slave 的架构模式
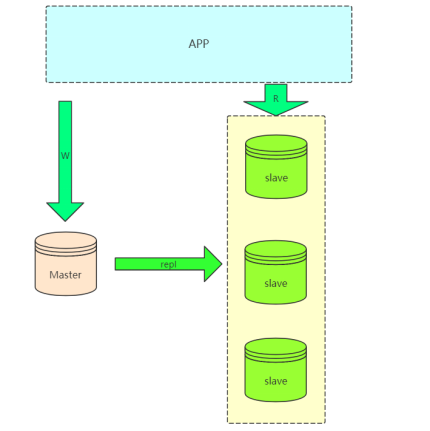
缺点:
1、master不能停机,停机就不能接收写请求
2、slave过多会出现延迟
由于master需要进行常规维护停机了,那么必须要把一个slave提成master,选哪一个是一个问题?
某一个slave提成master了,就存在当前master和之前的master数据不一致的情况,并且之前master并没有保存当前
master节点的binlog文件和pos位置。
Dual Master 复制架构(Master --- Master) Master)
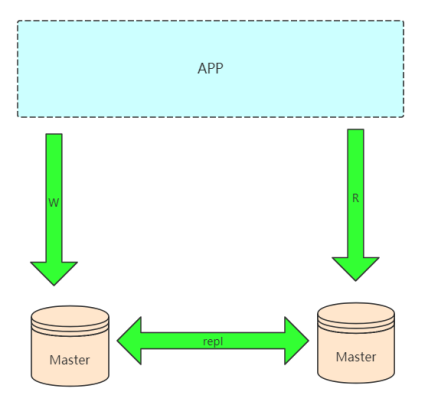
可以配合一个第三方的工具,比如keepalived轻松做到IP的漂移,停机维护也不会影响写操作。
级联复制架构(Master --- Slaves --- Slaves ...) ...)
如果读压力加大,就需要更多的slave来解决,但是如果slave的复制全部从master复制,势必会加大master的复制IO的压力,所以就出现了级联复制,减轻master压力。
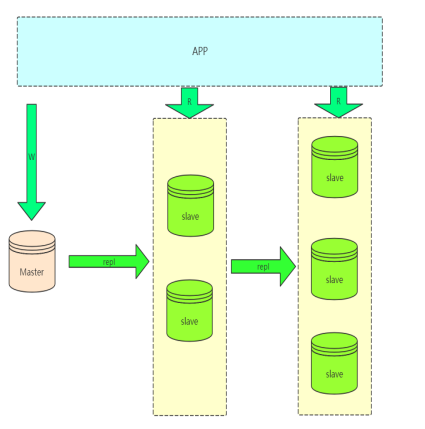
缺点:
slave延迟更加大了
Dual Master 与级联复制结合架构(Master - Master - Slaves)
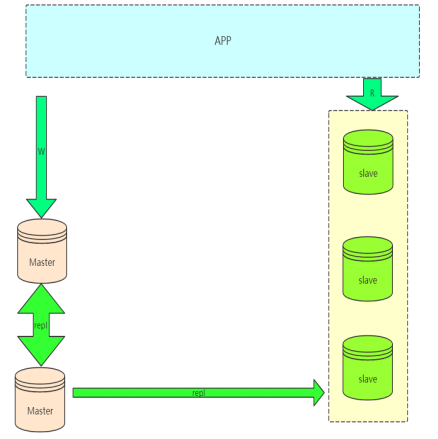
这样解决了单点master的问题,解决了slave级联延迟的问题.
Replication机制的实现原理
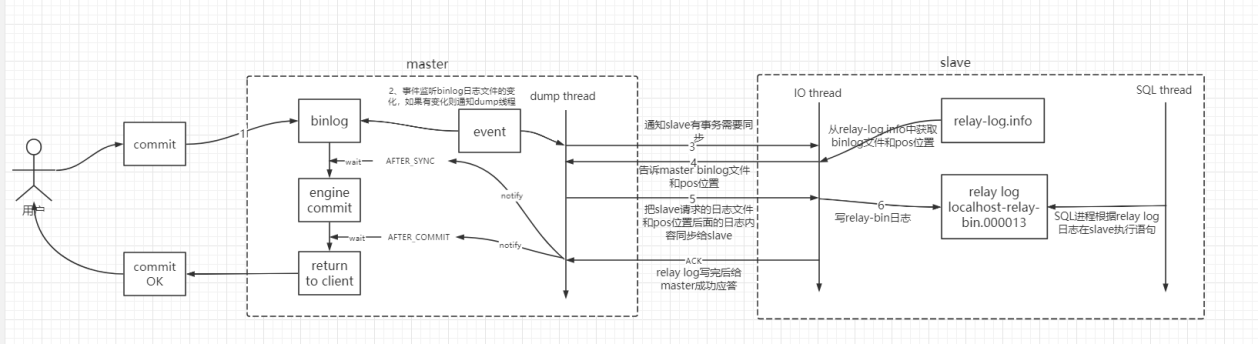
mysql数据热备份
1、进入mysql查看数据库
mysql -uroot -p123456;
show databases;
2、备份相应数据库
mysqldump -uroot -p123456 --databases consult mall > back.sql
这里需要注意,如果是热备份,这里需要在dump数据之前进行锁表操作,避免dump数据的时候出现插入操作导致数据不一致的情况。
3、master锁表
锁表:flush table with read lock;
4、slave导入数据
mysql -uroot -p123456 < back.sql
5、master解锁
解锁:unlock tables;
Mysql主从复制
master配置
server-id=135
#开启复制功能
log-bin=mysql-bin
auto_increment_increment=2
auto_increment_offset=1
lower_case_table_names=1
#binlog-do-db=mstest //要同步的mstest数据库,要同步多个数据库
#binlog-ignore-db=mysql //要忽略的数据库
slave配置
server-id=133
log-bin=mysql-bin
auto-increment-increment=2
auto-increment-offset=2
lower_case_table_names=1
#replicate-do-db = wang #需要同步的数据库
#binlog-ignore-db = mysql
#binlog-ignore-db = information_schema
1 在master mysql添加权限
GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456';
FLUSH PRIVILEGES;
2 在master上查看master的二进制日志
show master status;

3 在slave中设置master的信息
change master to master_host='192.168.88.135',master_port=3307,master_user='repluser',master_password='Jack@123456',master_log_file='mysql-bin.000001',master_log_pos=154;
4 开启slave,启动SQL和IO线程
start slave;
5 查看slave的状态
show slave statusG
6 查看二进制日志是否开启
show global variables like "%log%";
7 查看进程信息
SHOW PROCESSLIST;
8 允许root远程连接
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'youpassword' WITH GRANT OPTION;
FLUSH PRIVILEGES;
Mysql主从半同步复制
加载lib,所有主从节点都要配置
主库:install plugin rpl_semi_sync_master soname 'semisync_master.so';
从库:install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
可以一起装。建议一起装,因为会有主从切换的情景。
查看,确保所有节点都成功加载。
show plugins;
启用半同步
先启用从库上的参数,最后启用主库的参数。
从库:set global rpl_semi_sync_slave_enabled = {0|1}; # 1:启用,0:禁止
主库:
set global rpl_semi_sync_master_enabled = {0|1}; # 1:启用,0:禁止
set global rpl_semi_sync_master_timeout = 10000; # 单位为ms
风险:endbled写入配置文件的话,会使实例启动后立即进入半同步模式,如果发生长时间断连的实例重新运行启动,有可能导致主库被拖垮。
建议:长时间断开的从库,重新连接后,要等待追完全部事务后,手动开启半同步模式,而不是启动后直接切换,防止冲击主库。
master的my.cnf配置
[mysqld]
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
slave的my.cnf配置
[mysqld]
rpl_semi_sync_slave_enabled=1
从库重启io_thread
stop slave io_thread;
start slave io_thread;
查询主库状态信息
show global status like "%sync%";
重要参数
Rpl_semi_sync_master_clients 支持和注册半同步复制的已连Slave数
Rpl_semi_sync_master_no_times master关闭半同步复制的次数
Rpl_semi_sync_master_no_tx master没有收到slave的回复而提交的次数,可以理解为master等待超时的次数,即半同步模式不成功提交数量
Rpl_semi_sync_master_status ON是活动状态(半同步),OFF是非活动状态(异步),用于表示主服务器使用的是异步复制模式,还是半同步复制模式
Rpl_semi_sync_master_tx_avg_wait_time master花在每个事务上的平均等待时间
Rpl_semi_sync_master_tx_waits master等待成功的次数,即master没有等待超时的次数,也就是成功提交的次数
Rpl_semi_sync_master_yes_tx master成功接收到slave的回复的次数,即半同步模式成功提交数量。
查询主库参数信息
show global variables like '%sync%';
重要参数
rpl_semi_sync_master_enabled (主库)是否启动半同步
rpl_semi_sync_master_timeout 等待多时毫秒后变成异步复制,默认是10000ms
rpl_semi_sync_master_wait_point 5.7默认AFTER_SYNC(增强版半同步复制,无损复制模式),在得到slave的应答后再commit,可选值AFTER_COMMIT,在master提交后同步数据给slave,然后master等待slave应答,应答成功返回客户端。
after_commit缺点
缺点1: 幻读
当用户发起一个事务,该事务已经写入redo日志和binlog日志,但该事务还没写入从库,此时处在waiting slave dump处,此时另一个用户可以读取到这条数据,而他自己却不能;
缺点2:数据丢失
一个事务在waiting slave dump处crash后,主库将比从库多一条数据
mysql官网配置信息详解
https://dev.mysql.com/doc/refman/5.6/en/replication-options-reference.html


Mysql高可用
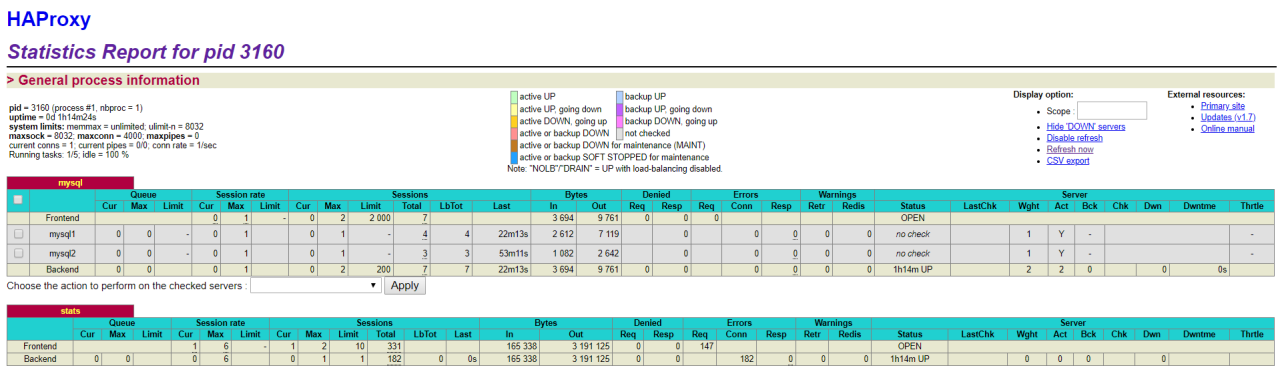
haproxy安装
找到haproxy的包
wget http://pkgs.fedoraproject.org/repo/pkgs/haproxy/haproxy-1.7.9.tar.gz
解压
tar zxf haproxy-1.7.9.tar.gz
编译安装
cd haproxy-1.7.9
make TARGET=linux310 ARCH=x86_64 (查看自己系统是什么 uname -r)
make install SBINDIR=/usr/sbin/ MANDIR=/usr/share/man/ DOCDIR=/usr/share/doc/
配置haproxy
新建目录和用户
mkdir /etc/haproxy
mkdir /var/lib/haproxy
useradd -r haproxy
编辑配置文件
vi /etc/haproxy/haproxy.cfg
配置日志
vim /etc/rsyslog.conf
# Provides TCP syslog reception #去掉下面两行注释,开启TCP监听
$ModLoad imudp
$UDPServerRun 514
local2.* /var/log/haproxy.log #添加日志
vi /etc/sysconfig/rsyslog
SYSLOGD_OPTIONS=""
改为 SYSLOGD_OPTIONS="-r -m 2 -c 2"
创建日志文件
touch /var/log/haproxy.log
启动日志
systemctl restart rsyslog.service
启动haproxy cd /usr/sbin/haproxy
./haproxy -f /etc/haproxy/haproxy.cfg
在两台数据库添加远程访问权限
GRANT ALL ON *.* TO 'root'@'%' IDENTIFIED BY 'Jack@123456';
FLUSH PRIVILEGES;
测试haproxy服务器能否连接到数据库服务器
安装mysql客户端
yum install -y mysql
mysql -uroot -pJack@123456 -h 192.168.88.135
mysql -uroot -pJack@123456 -h 192.168.88.133
在非haproxy服务器测试通过访问haproxy访问到mysql服务
mysql -uroot -pJack@123456 -h 192.168.88.132 -P 3300
访问页面 http://192.168.88.132:1080/stats
keepalived安装
源码安装
wget http://www.keepalived.org/software/keepalived-1.3.5.tar.gz
tar -zxvf keepalived-1.3.5.tar.gz
安装openssl openssl-devel
yum -y install openssl openssl-devel
./configure --prefix=/usr/local/keepalived --sbindir=/usr/sbin/ --sysconfdir=/etc/ -- mandir=/usr/local/share/man/
make && make install
修改配置
vi /etc/keepalived/keepalived.conf

给执行权限
# chmod +x /etc/keepalived/chk.sh
创建检查haproxy脚本

Yum安装
keepalived yum安装
预先安装好epel-release源
yum list installed|grep epel-release
查找可用安装的keepalived源
yum search keepalived
命令进行安装
yum install keepalived -y
启动keepalived服务
systemctl start keepalived
使用yum安装的会有一个默认配置文件模板
路径为/etc/keepalived/keepalived.conf
yum install ipvsadm -y
mysql -h 192.168.67.140 -u root -p123456 -P 3307 -e "show status;" >/dev/null 2>&1
>/dev/null 2>&1 输出”黑洞”
$? 上一个指令是否执行成功
0 成功 1 失败
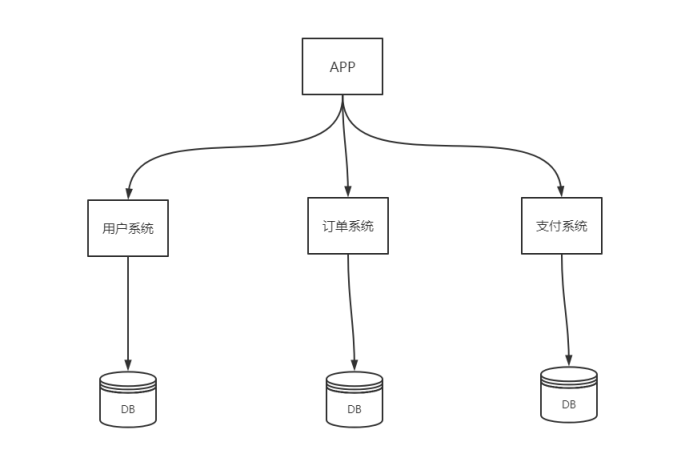
何为数据切分
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
数据切分分为两种:
垂直切分
水平切分
垂直切分:
垂直切分的优点
◆ 数据库的拆分简单明了,拆分规则明确;
◆ 应用程序模块清晰明确,整合容易;
◆ 数据维护方便易行,容易定位;
垂直切分的缺点
◆ 部分表关联无法在数据库级别完成,需要在程序中完成,存在跨库join的问题,对于这类的表,就需要去做平衡,是数据库让步业务,共用一个数据源,还是分成多个库,业务之间通过接口来做调用;在系统初期,数据量比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到了一定的规模,负载很大的情况,就需要必须去做分割。
◆ 对于访问极其频繁且数据量超大的表仍然存在性能瓶颈,不一定能满足要求;
◆ 事务处理相对更为复杂;
◆ 切分达到一定程度之后,扩展性会遇到限制;
◆ 过多切分可能会带来系统过渡复杂而难以维护。
水平切分:
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中.

水平切分的优点
◆ 表关联基本能够在数据库端全部完成;
◆ 不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
◆ 应用程序端整体架构改动相对较少;
◆ 事务处理相对简单;
◆ 只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点
切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
后期数据的维护难度有所增加,人为手工定位数据更困难;
应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
跨节点合并排序分页问题
多数据源管理问题
几种典型的分片规则
1、按照用户ID求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中。
2、按照日期,将不同月甚至日的数据分散到不同的库中。
3、按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中。
由于数据切分后数据Join的难度在此也分享一下数据切分的经验
第一原则:能不切分尽量不要切分。
第二原则:如果要切分一定要选择合适的切分规则,提前规划好。
第三原则:数据切分尽量通过数据冗余或表分组(Table Group)来降低跨库Join的可能。
第四原则:由于数据库中间件对数据Join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表Join。
综上描述,数据切分带来的核心问题主要有三个:
◆ 引入分布式事务的问题;
◆ 跨节点 Join 的问题;
◆ 跨节点合并排序分页问题;