消息发布时的权衡
在 RabbitMQ在设计的时候,特意让生产者和消费者“脱钩”,也就是消息的发布和消息的消费之间是解耦的。
在 RabbitMQ中,有不同的投递机制(生产者),但是每一种机制都对性能有一定的影响。一般来讲速度快的可靠性低,可靠性好的性能差,具体怎么使用需要根据你的应用程序来定,所以说没有最好的方式,只有最合适的方式。只有把你的项目和技术相结合,才能找到适合你的平衡。


在 RabbitMQ 中实际项目中,生产者和消费者都是客户端,它们都可以完成申明交换器、申明队列和绑定关系,但是在我们的实战过程中,我们在生产者代码中申明交换器,在消费者代码中申明队列和绑定关系。
另外还要申明的就是,生产者发布消息时不一定非得需要消费者,对于 RabbitMQ来说,如果是单纯的生产者你只需要生产者客户端、申明交换器、申明队列、确定绑定关系,数据就能从生产者发送至 RabbitMQ。只是为了演示的方便,我们在例子中使用消费者消费队列中的数据来方便展示结果。
无保障
在演示各种交换器中使用的就是无保障的方式,通过 basicPublish发布你的消息并使用正确的交换器和路由信息,你的消息会被接收并发送到合适的队列中。但是如果有网络问题,或者消息不可路由,或者 RabbitMQ 自身有问题的话,这种方式就有风险。所以无保证的消息发送一般情况下不推荐。
失败确认
在发送消息时设置mandatory标志,告诉 RabbitMQ,如果消息不可路由,应该将消息返回给发送者,并通知失败。可以这样认为,开启mandatory是开启故障检测模式。
注意:它只会让 RabbitMQ向你通知失败,而不会通知成功。如果消息正确路由到队列,则发布者不会受到任何通知。带来的问题是无法确保发布消息一定是成功的,因为通知失败的消息可能会丢失。

channel.addConfirmListener则用来监听 RabbitMQ发回的信息。
监听器的小甜点
在信道关闭和连接关闭时,还有两个监听器可以使用

事务
事务的实现主要是对信道(Channel)的设置,主要的方法有三个:
1. channel.txSelect()声明启动事务模式;
2. channel.txComment()提交事务;
3. channel.txRollback()回滚事务;
在发送消息之前,需要声明 channel为事务模式,提交或者回滚事务即可。
开启事务后,客户端和 RabbitMQ之间的通讯交互流程:
- 客户端发送给服务器 Tx.Select(开启事务模式)
- ·服务器端返回 Tx.Select-Ok(开启事务模式 ok)
- ·推送消息
- ·客户端发送给事务提交 Tx.Commit
- ·服务器端返回 Tx.Commit-Ok
以上就完成了事务的交互流程,如果其中任意一个环节出现问题,就会抛出 IoException移除,这样用户就可以拦截异常进行事务回滚,或决定要不要重复消息。

那么,既然已经有事务了,为何还要使用发送方确认模式呢,原因是因为事务的性能是非常差的。根据相关资料,事务会降低 2~10倍的性能。
发送方确认模式
基于事务的性能问题,RabbitMQ团队为我们拿出了更好的方案,即采用发送方确认模式,该模式比事务更轻量,性能影响几乎可以忽略不计。
原理:生产者将信道设置成 confirm模式,一旦信道进入 confirm模式,所有在该信道上面发布的消息都将会被指派一个唯一的 ID(从 1开始),由这个 id在生产者和 RabbitMQ之间进行消息的确认。
不可路由的消息,当交换器发现,消息不能路由到任何队列,会进行确认操作,表示收到了消息。如果发送方设置了mandatory模式,则会先调用addReturnListener监听器。
可路由的消息,要等到消息被投递到所有匹配的队列之后,broker会发送一个确认给生产者(包含消息的唯一 ID),这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会在将消息写入磁盘之后发出,broker回传给生产者的确认消息中 delivery-tag 域包含了确认消息的序列号。
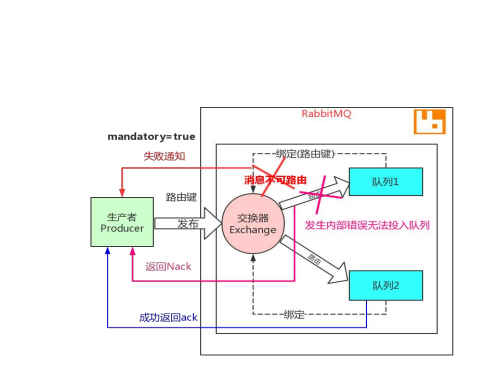
confirm模式最大的好处在于他可以是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果 RabbitMQ因为自身内部错误导致消息丢失,就会发送一条 nack消息,生产者应用程序同样可以在回调方法中处理该 nack消息决定下一步的处理。
Confirm的三种实现方式:
方式一:channel.waitForConfirms()普通发送方确认模式;消息到达交换器,就会返回 true。
方式二:channel.waitForConfirmsOrDie()批量确认模式;使用同步方式等所有的消息发送之后才会执行后面代码,只要有一个消息未到达交换器就会抛出 IOException异常。
方式三:channel.addConfirmListener()异步监听发送方确认模式;
备用交换器
在第一次声明交换器时被指定,用来提供一种预先存在的交换器,如果主交换器无法路由消息,那么消息将被路由到这个新的备用交换器。
如果发布消息时同时设置了mandatory会发生什么?如果主交换器无法路由消息,RabbitMQ并不会通知发布者,因为,向备用交换器发送消息,表示消息已经被路由了。注意,新的备用交换器就是普通的交换器,没有任何特殊的地方。
使用备用交换器,向往常一样,声明 Queue和备用交换器,把 Queue绑定到备用交换器上。然后在声明主交换器时,通过交换器的参数,
alternate-exchange,,将备用交换器设置给主交换器。
建议备用交换器设置为 faout类型,Queue绑定时的路由键设置为“#”
消息的消费
可靠性和性能的权衡

消息的获得方式
拉取 Get
属于一种轮询模型,发送一次 get请求,获得一个消息。如果此时 RabbitMQ 中没有消息,会获得一个表示空的回复。总的来说,这种方式性能比较差,很明显,每获得一条消息,都要和 RabbitMQ进行网络通信发出请求。而且对 RabbitMQ来说,RabbitMQ无法进行任何优化,因为它永远不知道应用程序何时会发出请求。具体使用,参见代码 native模块包 cn.enjoyedu.consumer_balance.GetMessage中。对我们实现者来说,要在一个循环里,不断去服务器 get消息。
推送 Consume
属于一种推送模型。注册一个消费者后,RabbitMQ会在消息可用时,自动将消息进行推送给消费者。这种模式我们已经使用过很多次了,具体使用,参见代码 native模块包 cn.enjoyedu.exchange.direct中。
消息的应答
前面说过,消费者收到的每一条消息都必须进行确认。消息确认后,RabbitMQ才会从队列删除这条消息,RabbitMQ不会为未确认的消息设置超时时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否已经断开。这么设计的原因是 RabbitMQ允许消费者消费一条消息的时间可以很久很久。
自动确认
消费者在声明队列时,可以指定 autoAck参数,当 autoAck=true时,一旦消费者接收到了消息,就视为自动确认了消息。如果消费者在处理消息的过程中,出了错,就没有什么办法重新处理这条消息,所以我们很多时候,需要在消息处理成功后,再确认消息,这就需要手动确认。
手动确认
当 autoAck=false时,RabbitMQ会等待消费者显式发回 ack信号后才从内存(和磁盘,如果是持久化消息的话)中移去消息。否则,RabbitMQ会在队列中消息被消费后立即删除它。
采用消息确认机制后,只要令 autoAck=false,消费者就有足够的时间处理消息(任务),不用担心处理消息过程中消费者进程挂掉后消息丢失的问题,因为 RabbitMQ会一直持有消息直到消费者显式调用 basicAck为止。
当 autoAck=false时,对于 RabbitMQ服务器端而言,队列中的消息分成了两部分:一部分是等待投递给消费者的消息;一部分是已经投递给消费者,但是还没有收到消费者 ack信号的消息。如果服务器端一直没有收到消费者的 ack信号,并且消费此消息的消费者已经断开连接,则服务器端会安排该消息重新进入队列,等待投递给下一个消费者(也可能还是原来的那个消费者)。
通过运行程序,启动两个消费者 A、B,都可以收到消息,但是其中有一个消费者 A不会对消息进行确认,当把这个消费者 A关闭后,消费者 B又会收到本来发送给消费者 A的消息。所以我们一般使用手动确认的方法是,将消息的处理放在 try/catch语句块中,成功处理了,就给 RabbitMQ一个确认应答,如果处理异常了,就在 catch中,进行消息的拒绝。
QoS 预取模式
在确认消息被接收之前,消费者可以预先要求接收一定数量的消息,在处理完一定数量的消息后,批量进行确认。如果消费者应用程序在确认消息之前崩溃,则所有未确认的消息将被重新发送给其他消费者。所以这里存在着一定程度上的可靠性风险。
这种机制一方面可以实现限速(将消息暂存到 RabbitMQ内存中)的作用,一方面可以保证消息确认质量(比如确认了但是处理有异常的情况)。
注意:
消费确认模式必须是非自动 ACK机制(这个是使用 baseQos的前提条件,否则会 Qos不生效),然后设置 basicQos的值;另外,还可以基于 consume和 channel的粒度进行设置(global)。
我们可以进行批量确认,也可以进行单条确认。
basicQos 方法参数详细解释:
prefetchSize:最多传输的内容的大小的限制,0为不限制,但据说 prefetchSize参数,rabbitmq没有实现。
prefetchCount:会告诉 RabbitMQ不要同时给一个消费者推送多于 N个消息,即一旦有 N个消息还没有 ack,则该 consumer将 block掉,直到有消息 ack
global:truefalse 是否将上面设置应用于 channel,简单点说,就是上面限制是 channel级别的还是 consumer级别。
如果同时设置 channel和消费者,会怎么样?AMQP规范没有解释如果使用不同的全局值多次调用 basic.qos会发生什么。 RabbitMQ将此解释为意味着两个预取限制应该彼此独立地强制执行; 消费者只有在未达到未确认消息限制时才会收到新消息。
channel.basicQos(10, false); // Per consumer limit
channel.basicQos(15, true); // Per channel limit
channel.basicConsume("my-queue1", false, consumer1);
channel.basicConsume("my-queue2", false, consumer2);
也就是说,整个通道加起来最多允许 15条未确认的消息,每个消费者则最多有 10条消息。
消费者中的事务
使用方法和生产者一致
假设消费者模式中使用了事务,并且在消息确认之后进行了事务回滚,会是什么样的结果?
结果分为两种情况:
1. autoAck=false手动应对的时候是支持事务的,也就是说即使你已经手动确认了消息已经收到了,但 RabbitMQ对消息的确认会等事务的返回结果,再做最终决定是确认消息还是重新放回队列,如果你手动确认之后,又回滚了事务,那么以事务回滚为准,此条消息会重新放回队列;
2. autoAck=true如果自动确认为 true的情况是不支持事务的,也就是说你即使在收到消息之后在回滚事务也是于事无补的,队列已经把消息移除了。