INFO
NABCD模型
NEED——需求
- 用户可给定论文列表
- 通过论文列表,爬取论文的题目、摘要、原文链接
- 可对论文列表进行增删改操作(今年、近两年、近三年)
- 对爬取的信息进行结构化处理,分析top10个热门领域或热门研究方向
- 可对论文属性(oral、spotlight、poster)进行筛选及分析
- 形成如热词图谱之类直观的查看方式
- 可进行论文检索,当用户输入论文编号、题目、作者等基本信息,分析返回相关的paper、source code、homepage等信息
- 可对多年间、不同顶会的热词呈现热度走势对比(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)
- 可进行数据统计,例如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等
- 附加需求:保存用户的搜索记录并进行相关论文推荐
APPROOACH————做法
-
我们的平台将基于WEB端向用户提供服务,因为随着终端性能的发展,网页应用与APP之间的用户体验差距越来越小,WEB端在保证用户体验的情况下又能兼顾不同终端的兼容性,使得用户在手机、电脑、平板上都能获得一致的使用体验。同时正是基于网页平台可以使我们的产品快速迭代,而不需要用户频繁更新软件。
-
针对整个项目来说:为了确保用户体验的流畅性,网站后台会提前根据三大计算机视觉的论文列表爬取出相应的论文摘要、作者、研究方向等关键信息存储在服务器数据库中,这样当用户查找时可以大大提高检索效率
-
针对需求1:首先读取用户上传的论文列表,并将上传结果显示展示给用户,方便用户进行下一步对论文列表进行增删改操作,操作包括论文年份筛选以及论文增删。之后后端服务器根据用户最终确定的论文列表,从后端数据库中找出对应列表的论文题目、原文链接以及摘要,返回到用户界面
-
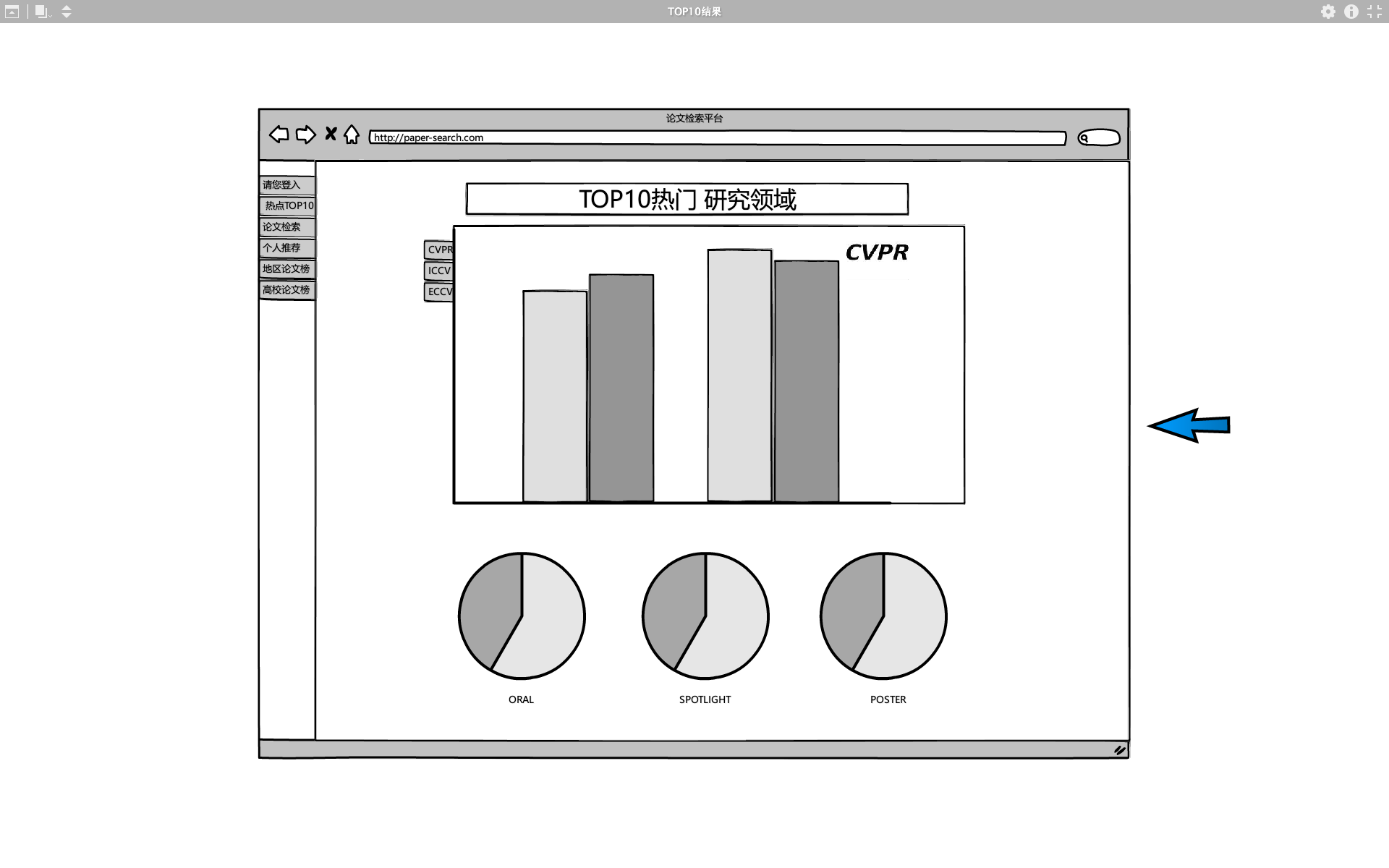
针对需求2:根据数据库返回的结果,对用户给定列表中的论文研究方向进行归类和排序输出TOP10的热门研究方向,并可让用户根据论文属性自行筛选结果。当后端得出最终结果通过数据可视化将不同论文属性的TOP10热门研究方向展示给用户
-
针对需求3:用户可以输入论文编号、题目、作者等基本信息,由后端代替用户进行论文的爬取,针对爬取结果返回相关论文、源代码以及项目的首页
-
针对需求4:由后端服务器提前爬取三大计算机视觉顶会的论文,并通过论文的标题、摘要提取出论文的研究方向,并进行统计,进而形成每年每届顶会的热点,最后通过数据可视化直观的展示给用户
-
针对需求5:针对每篇文章的第一作者和第二作者在wiki百科上搜索相对应的个人介绍页面,以此来确定作者的国籍以及所在院校或者研究机构。以此统计出每个国家录用文章、每个学校录用文章的情况。之后以学校为单位分析出学校的强势研究方向。
-
针对附加需求:网站提供用户注册与登入系统,方便保存用户的浏览记录,并根据用户习惯描绘出用户画像,为用户推送个性化的推荐阅读论文
BENIFIT————好处
- 使用本平台用户可以:
- 根据指定的论文列表快速且精准地把握三大计算机视觉顶会近年来的热门研究方向
- 基于本平台提供的论文热点汇报、论文查询以及论文来源汇总的功能获得一站式论文检索体验,免去用户在论文统计和查询方面花费大量不必要的时间
- 用户在使用本平台一段时间后,用户将获得其感兴趣的研究领域的相关论文推送,使得用户只需极少的时间花费就能紧跟前沿研究方向进展
COMPETITORS————竞争
-
对于如arXiv这样的论文聚合类网站,它们的设计初衷是为了方便科学家之间的交流,并不是专门针对本科学学生提供服务,这就导致学生在使用这些网站时无法充分表达出自己的需求,而我们的平台以本科大学生对论文的需求出发,一切功能以此为目标构建,所以我们的平台在功能性和易用性上能够超越现有的竞争对手
-
此外,现有竞争产品往往只提供单一的论文检索功能,而我们在提供论文检索的基础上,还对论文的属性、摘要、关键词进行统计,通过大量论文样本发掘出行业趋势、热点等无法从论文检索得出的重要信息,并以此产生分析数据直观展示给用户这是我们远远领先同类产品的方面
DELIVERYU————推广
-
产品刚刚发布时,将以福州大学内的各个实验室为基本推广对象,根据初期获得的用户评价与建议进行进一步的产品迭代与功能增替
-
当产品功能稳定时,逐步向各大高校推广,积极寻求与校方的合作,当用户数量稳定之后,可以反过来吸引论文作者直接将论文向我们的平台投稿,以此形成良性循环
设计说明
用户登入界面
登入后来到默认页面,可以快速上传论文列表
让用户对上传的列表进行进一步的筛选和增删
根据后台数据库返回的数据进行科研热点可视化
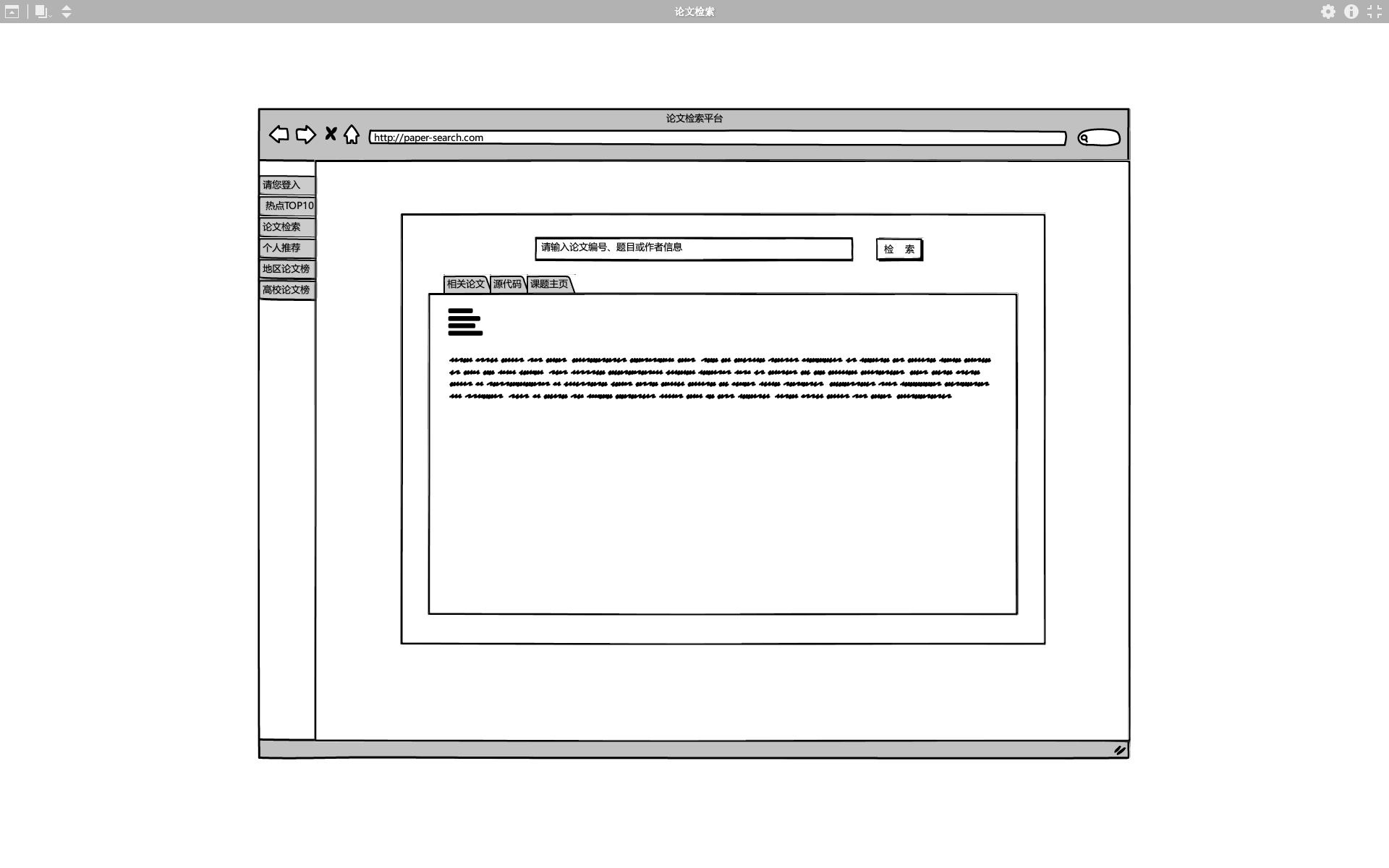
论文检索功能:用户可以输入指定论文查询相关源代码及课题主页
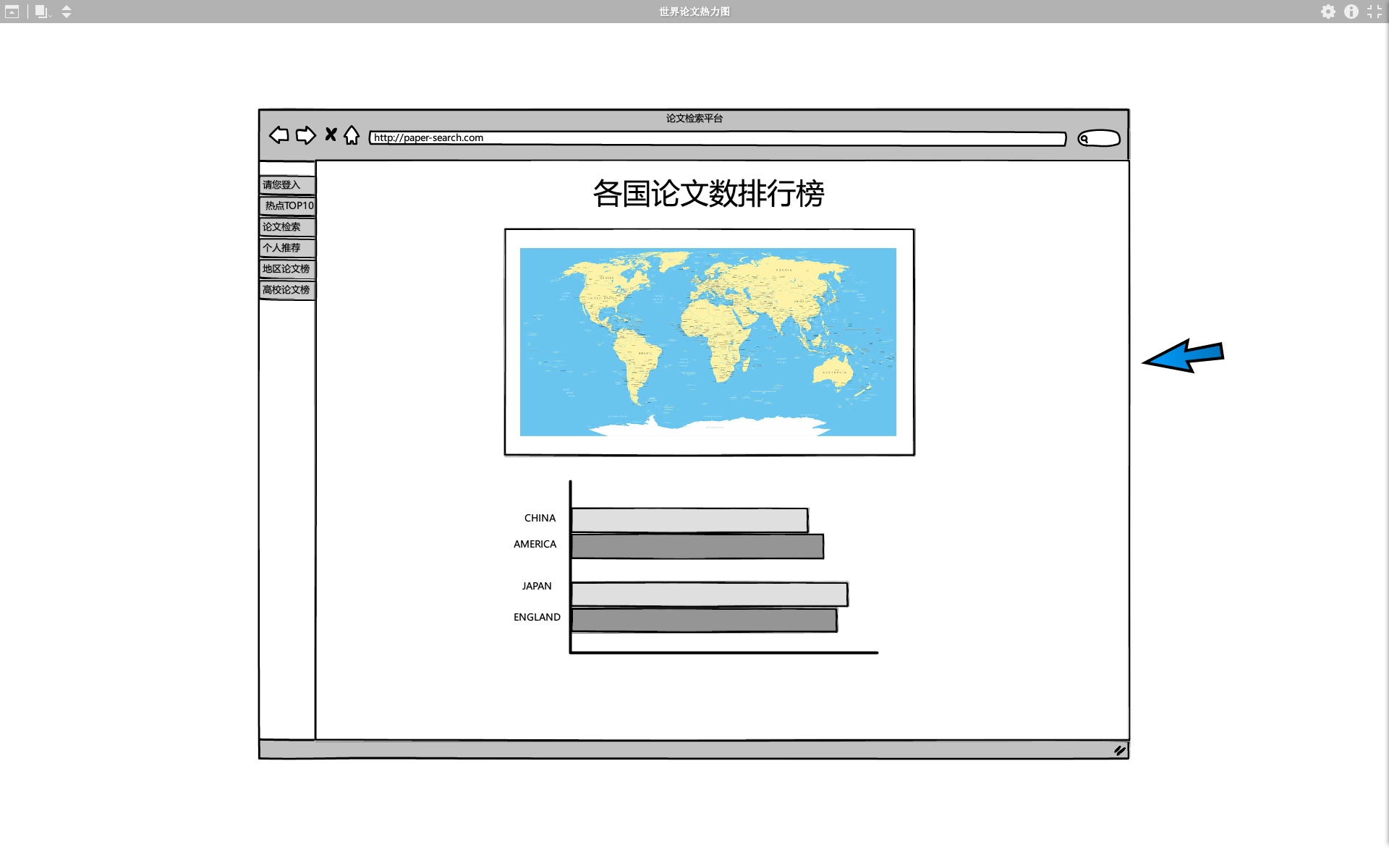
后台根据爬取的论文进行国籍统计展示出各国论文数
- [
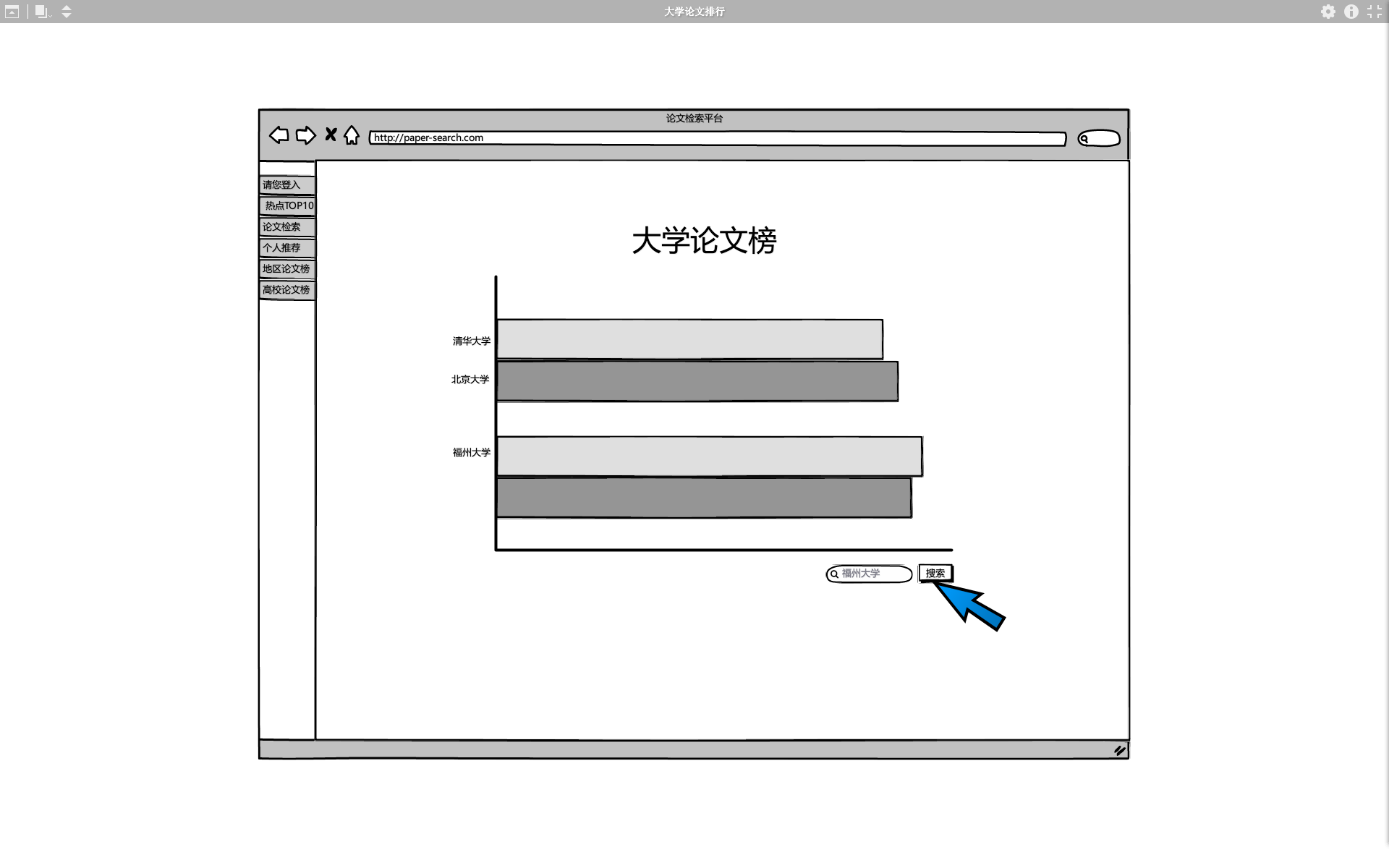
后台根据论文所属院校进行统计,展示出院校论文榜
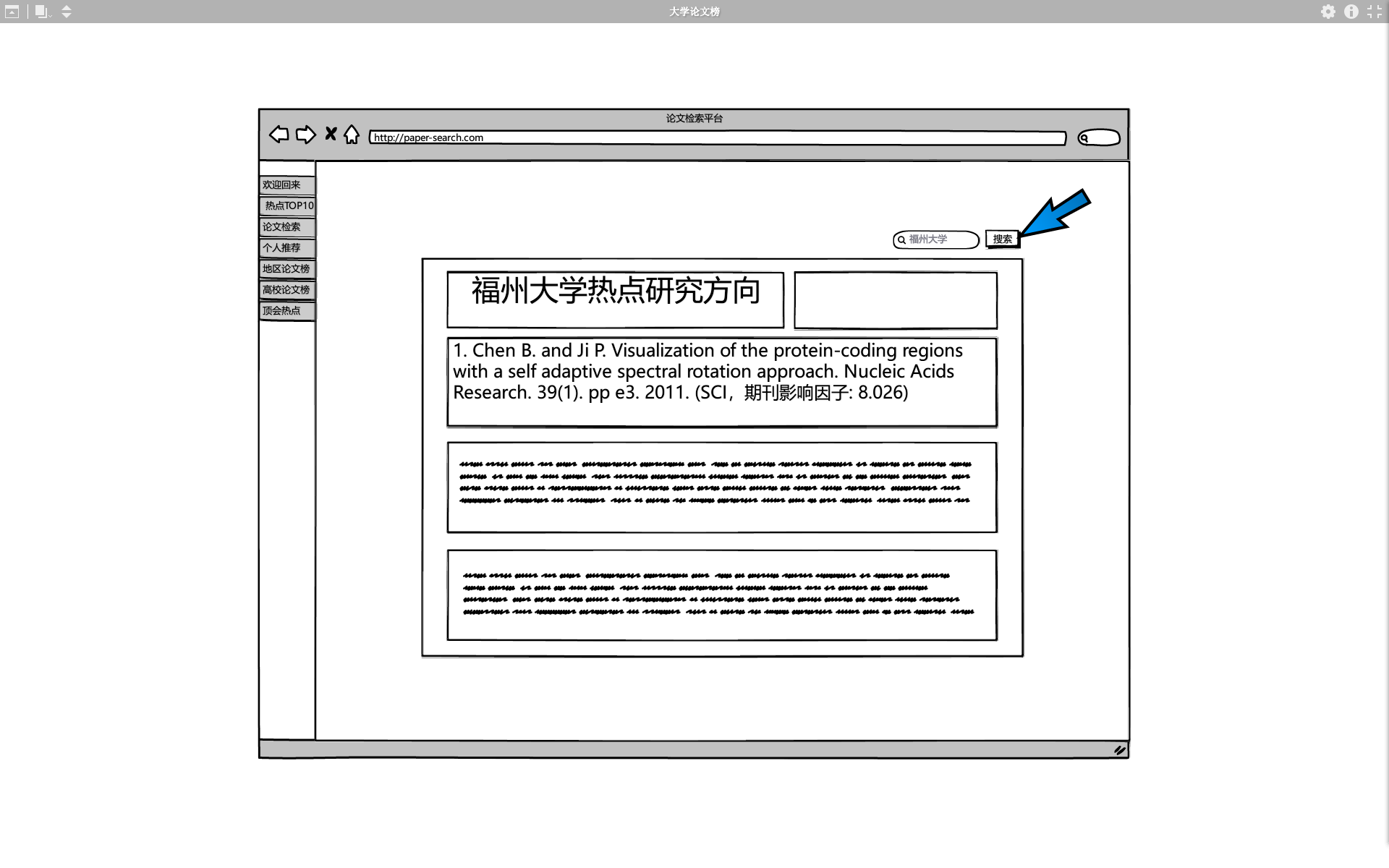
用户可以搜索指定院校,后台据此返回该院校的论文发布情况和强势研究方向
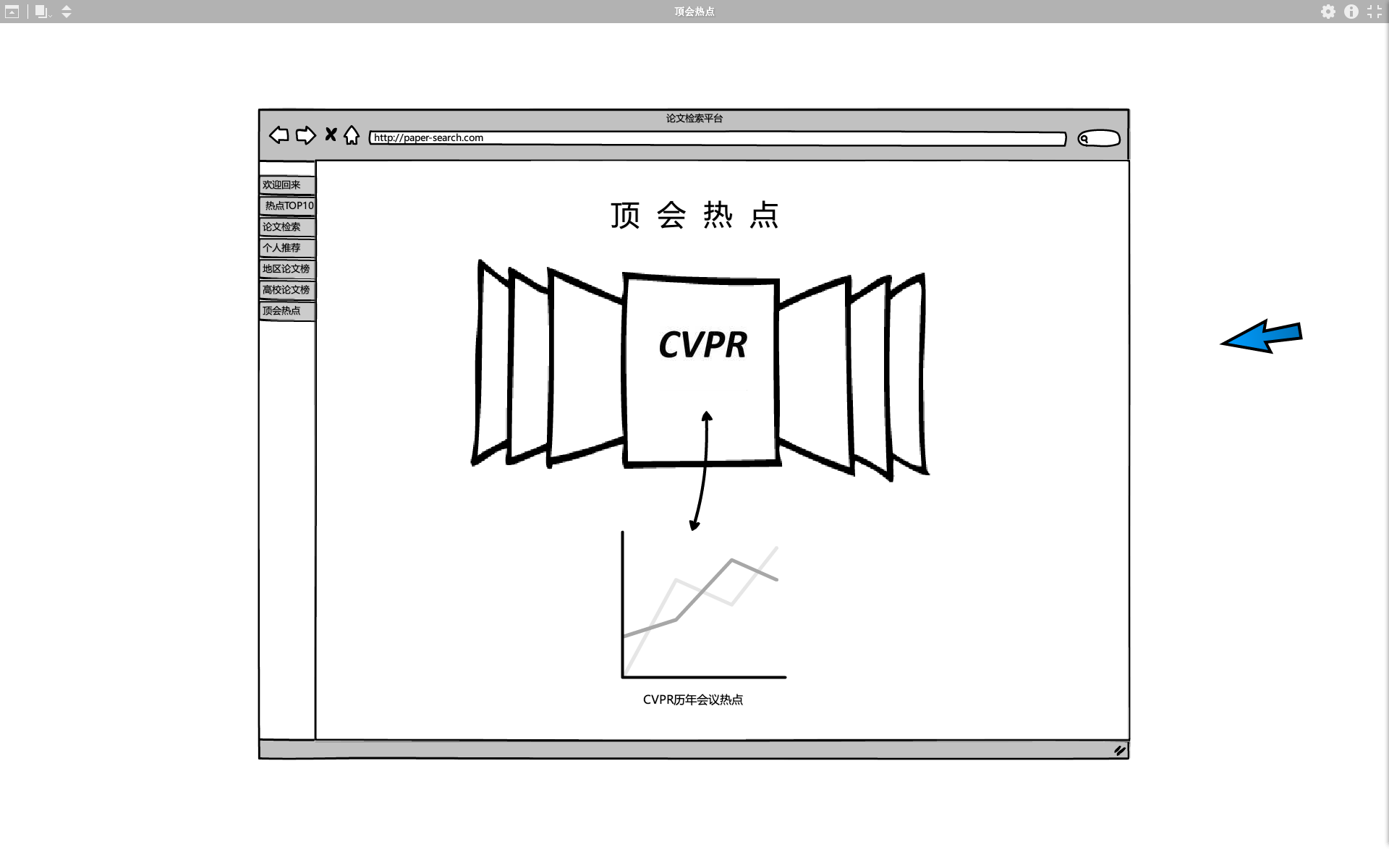
根据服务器爬取到历届顶会的数据,分析出每届顶会热点的变化趋势
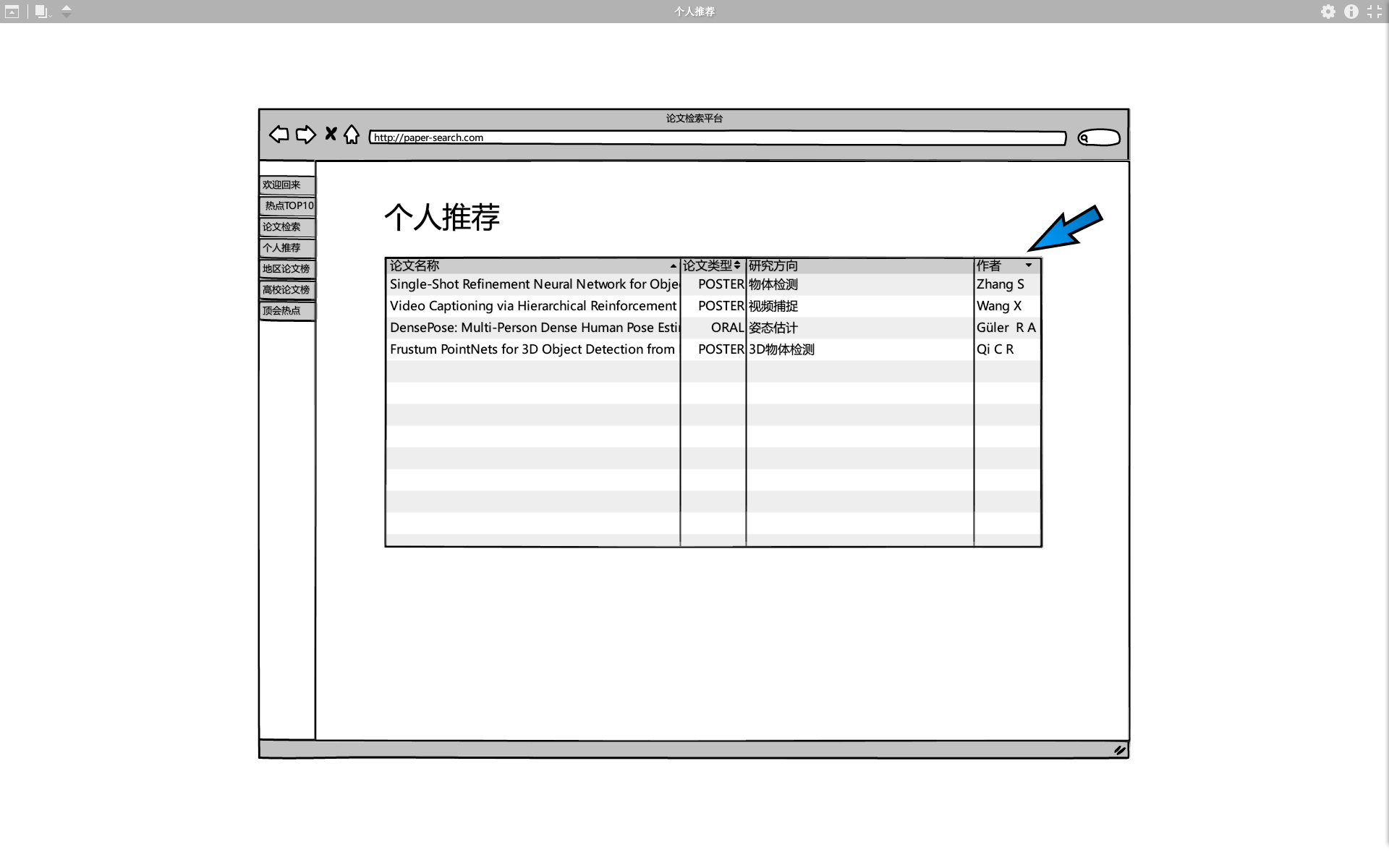
平台会根据用户记录建立用户画像,并依此向用户精准推送用户关注领域的最新动向
结对过程
-
缘,妙不可言。同一楼道的哥们终于因软工实践结缘,北京爷们就是爽快,从《构建之法》NABCD模型的学习,到原型软件的学习与使用,每天晚上8点准时为软工实践的结对作业添砖加瓦
-

-

遇到的困难及解决方法
设计风格问题
- 在这次实践的过程中,我们两都更倾向于简洁大方的设计,不过AXURE和Mockup-plus之类的软件虽然本身功能强大,但要实现我们心目中的效果却需要对应模板库的支撑,这让我们在设计之初拿不定主意在将助教推荐的原型设计工具挨个试了一遍之后我们终于找到了最适合我们的——Balsamiq Mockup
题意理解问题
- 这次实践的题目是偏向于开放性的命题,这让我和葛亮在对题意的理解上出现分歧,比如在论文列表上传环节上,我们两就对用户应该使用怎样的上传形式进行讨论。最后,我们通过从用户体验优先的角度来看待分歧,我们一致同意尽量减少用户的决策,让用户用最少的成本使用我们的平台是我们平台的核心竞争力,并以此构建了原型
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 30 |
| Development | 开发 | 730 | 420 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 70 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 10 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 600 | 300 |
| · Coding | · 具体编码 | 0 | 0 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 0 | 0 |
| Reporting | 报告 | 80 | 130 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 60 |
| 合计 | 740 | 580 |
学习进度条
| - 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 5 | 5 | 初步了解基于python的网页爬虫原理,阅读urllib和beatufsoup官方文档 |