在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转化成整数
索引,或是在计算结束后将整数索引还原为相应的标签。
StringIndexer转换器可以把一列类别型的特征(或标签)进行编码,使其数值化,索引的
范围从0开始,该过程可以使得相应的特征索引化,使得某些无法接受类别型特征的算法可
以使用,并提高诸如决策树等机器学习算法的效率。
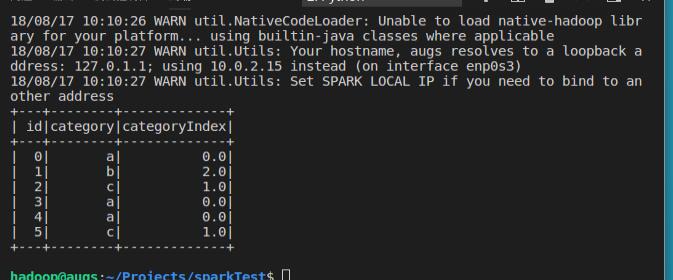
索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0号。
如果输入的是数值型的,我们会把它转化成字符型,然后再对其进行编码。
首先,引入必要的包,并创建一个简单的DataFrame,它只包含一个id列和一个标签列category:
#导入相关的类库
from pyspark.sql import SparkSession
from pyspark.ml.feature import StringIndexer
#配置spark,创建SparkSession对象
spark = SparkSession.builder.master('local').appName('StringIndexerDemo').getOrCreate()
#创建简单的DataFrame
df = spark.createDataFrame([
(0, "a"), (1, "b"),
(2, "c"), (3, "a"),
(4, "a"), (5, "c")],
["id", "category"])
#创建StringIndexer对象,设定输入输出参数
indexer =StringIndexer(inputCol ='category', outputCol= 'categoryIndex')
#对这个DataFrame进行训练
model = indexer.fit(df)
#利用生成的模型对DataFrame进行transform操作
indexed = model.transform(df)
indexed.show()