#导入相关的库
from pyspark.ml.feature import Word2Vec
from pyspark.sql import SparkSession
#配置spark
spark = SparkSession.builder.master("local").appName("Word2VecDemo").getOrCreate()
#创建三个词语序列,每个代表一个文档
documentDF = spark.createDataFrame([
("Hi I heard about Spark".split(" "), ),
("I wish Java could use case classes".split(" "), ),
("Logistic regression models are neat".split(" "), )
], ["text"])
#新建一个Word2Vec ,他是一个Estimator
word2Vec = Word2Vec(vectorSize =3, minCount=0, inputCol="text", outputCol="result")
#读入训练集,用fit() 方法生成Word2VecModel
model = word2Vec.fit(documentDF)
#利用生成的Word2VecModel转成特征向量
result =model.transform(documentDF)
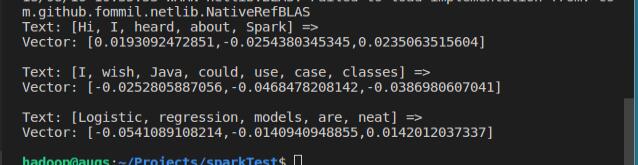
for row in result.collect():
text, vector = row
print("Text: [%s] =>
Vector: %s
" % (", ".join(text), str(vector)))
关于超参数的设置:
