#导入库
from operator import add
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
#配置创建StreamingContext对象
conf = SparkConf()
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 20)
#指定输入流文件夹
lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile')
#按空格切分
words = lines.flatMap(lambda line: line.split(' '))
#对单词进行词频统计
wordCounts = words.map(lambda x : (x,1)).reduceByKey(add)
#美观打印数据
wordCounts.pprint()
#开始循环监听
ssc.start()
#等待处理结束(手动结束或因为错误而结束)
ssc.awaitTermination()

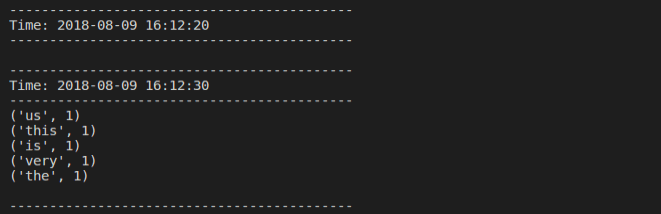
当logfile文件夹下的内容发生改变时,数据会相应的显示在上面