准备工作:一个安装了Java的linux系统,和hadoop-1.2.1-bin.tar.gz安装包
1.将hadoop-1.2.1-bin.tar.gz文件解压到/usr/local/src文件中
2.cd /hadoop-1.2.1中,创建一个临时文件:mkdir tmp
3.进入hadoop的配置文件目录中:cd /conf

4.修改core-site.xml文件:vim core-site.xml
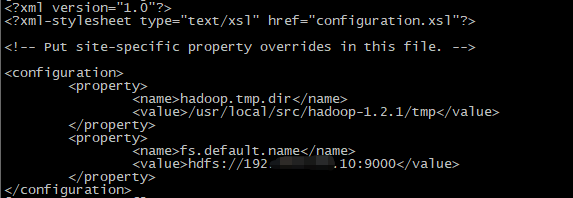
5.修改mapred-site.xml文件:vim mapred-site.xml
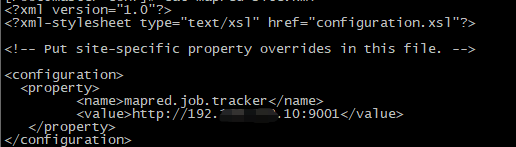
6.修改hadoop-env.sh文件:vim hadoop-env.sh,把java环境配置进去
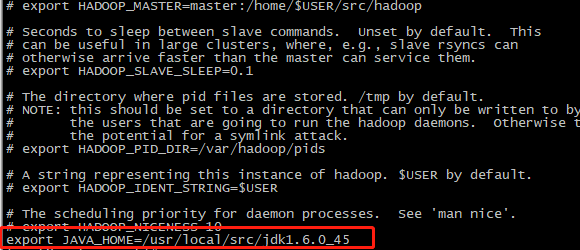
7.然后修改hosts文件,vim /etc/hosts,其中ip为主机master的ip,slave1的ip,slave2的ip,然后hostname master

8.长久修改名称的方法,还要修改/etc/sysconfig/network:vim /etc/sysconfig/network
9.关掉防火墙:/etc/init.d/iptables stop
10.将机器复制两份,并将hostname中的节点ip配置进ifcfg-etch0的文件中,配置完后先看能否联网
11.配置matser与从节点之间的无秘访问,首先在三台机器上都生成密钥:ssh-keygen,然后进入~/.ssh中

12.再在master上的~/.ssh文件中创建文件,authorized_keys,并将三个文件的公钥文件,id_rsa.pub,里面的内容复制到authorized_keys中
13.将authorized_keys文件通过scp -rp authorized_keys slave1:~/.ssh,将文件拷贝进从节点中
14.然后使用ssh slave1,进行验证
15.所有操作完成后开始启动hadoop,进入hadoop文件的bin文件中,首先使用./hadoop namebode -format格式化名称节点,然后使用./start-all.sh启动所有节点,如果启动成功,使用jps可以看到:

这些节点处于运行状态。如果启动失败,或者namenode没有启动,就要仔细排查,core-site.xml,mapred-site.xml等文件有没有问题,如果没有,就使用./stop-all.sh停掉所有节点,并再次使用./hadoop namebode -format命令进行格式化,再启动