@
前言
前期贴了很多代码,后期我会全部push到我的码云仓库以及github上,随时更新。有需要的可以fork到你们本地。仓库地址https://gitee.com/libo-sober/learn-python
GitHub地址 https://github.com/libo-sober/LearnPython
Day 01
一、python的历史和种类
今日内容大纲:
-
cpu 内存 硬盘 操作系统
cpu: 计算机的运算和计算中心,相当于人类的大脑。飞机。
内存:暂时存储数据,临时加载数据以及应用程序,8G,16G, 32G。速度快,高铁。断电即消失。造价很高。
硬盘: 磁盘,长期存储数据。D盘,E盘,文件,片儿,音频等等。500G, 1T。汽车。造价相对低。
操作系统:一个软件,连接计算机的硬件与所有软件之间的一个软件。

-
python的发展与应用
参考老男孩教育讲师太白金星的博客。
传送门 -
python的历史
python崇尚优美、清晰、简单。
python2x, python3x源码区别:
python2x:C、Java大牛贡献,重复代码多;代码不规范。
python3x:源码规范,清晰,简单。 -
python的编程语言分类(重点)
编译型:
将代码一次性全部编译成二进制,然后再执行。
优点:执行效率高。
缺点:开发效率低,不能跨平台。
代表语言:C。
解释型:
逐行解释成二进制,逐行运行。
优点:开发效率高,可以跨平台。
缺点:执行效率低。
代表语言:python。 -
python的优缺点
见上部分。 -
python的种类
Cpython:官方推荐解释器。可以转换成C语言能识别的字节码。
Jpython:可以转换成Java语言能识别的字节码。
Ironpython:可以转换成.net语言能识别的字节码。
PyPy:动态编译。
二、安装python解释器以及配置环境变量
安装python解释器流程
- 官网查找版本
https://www.python.org
- 选择版本
选择你的版本
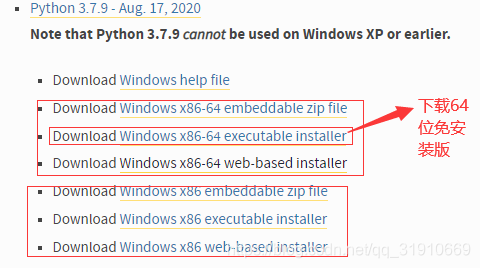
- 安装
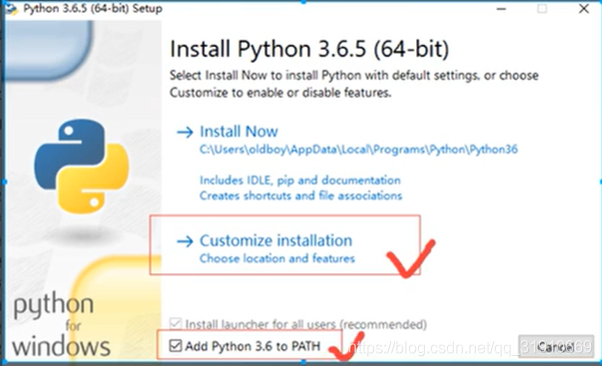
- 默认
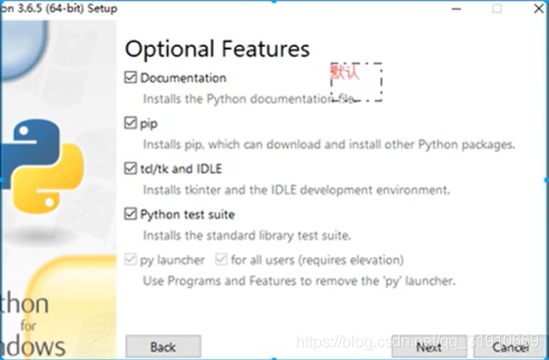
- 改路径
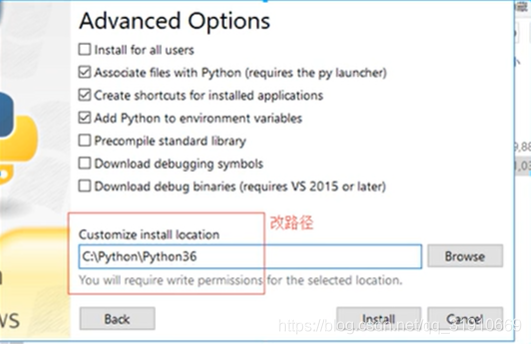
- 点击 install
- 测试
win + R 键入cmd
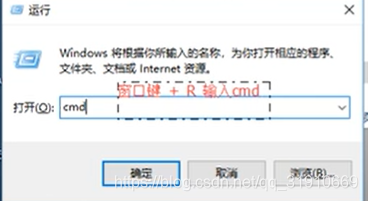
在命令行中输入 python
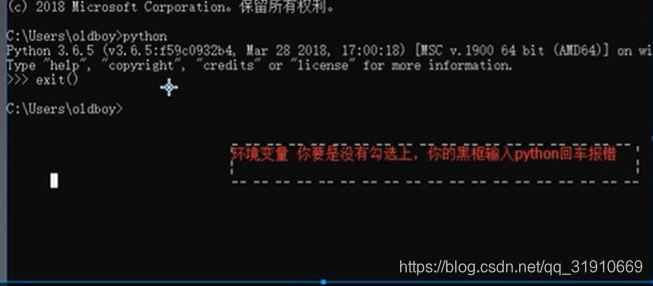
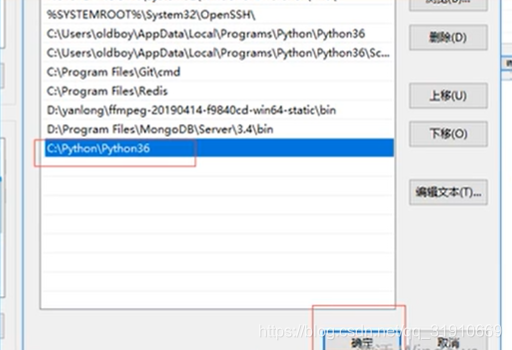
- 手动添加环境变量


点击环境变量后双击path
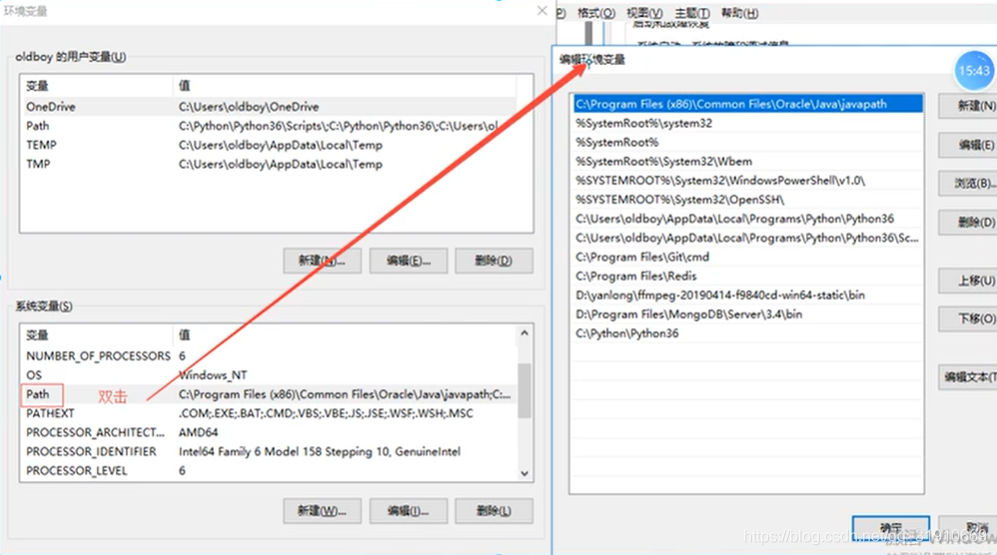
把你安装的路径加上,然后点击所有打开的窗口的确定键。
三、变量、常量和注释
- 运行第一个python代码
print('Hello world!') 保存为.py文件

- 变量
这一节全是基础 就不再重复了,可以去B站观看。
python基础变量传送门
Day 02
主要讲了 pycharm 的安装和使用
运算符、while循环和格式化输出等。
原视频传送门
也可以去python菜鸟教程参考学习
python基础菜鸟教程传送门
Day 03
主要为基础数据类型学习
- int
- bool
- str
- for循环
这里可以重点学习一下str字符串的操作
菜鸟教程字符串操作
Day 04
python的三大数据类型
Day 05
- 文件操作的初识
利用python代码写一个很low的软件去操作文件。
需求:
文件路径:path。 打开方式:读,写,追加,读写.....。 编码方式:utf-8,gbk......。
f1 = open('d:你想看的都在这.txt', encoding='utf-8', mode='r')
content = f1.read()
print(content)
f1.close()
"""
open 内置函数,open底层调用的是操作系统的接口。
f1 变量 f 文件句柄。 对文件进行的任何操作,都要通过文件句柄.操作函数()的方式。
encoding:参数可以默认不写,默认编码本为操作系统默认的编码。
widows:gbk。
Linux:utf-8。
mac:utf-8。
f1.close() 关闭文件
"""
"""
文件操作三部曲:
1.打开文件
2.对文件句柄进行相应的操作
3.关闭文件
C:UsersliboAppDataLocalProgramsPythonPython36python.exe D:/WorkSpace/Pycharm/fullstack/day05/文件的操作.py
详情请查看:
https://me.csdn.net/blog/qq_31910669
Process finished with exit code 0
"""
报错原因:
UnicodeDecodeError:文件存储时与文件打开时编码本运用不一致。
路径分隔符产生的问题:r'd:你想看的都在这.txt',加r后不会产生。
- 文件操作的读
r, rb, r+,.....
r: read(), read(n), readline(), readlines().
rb:操作的是非文本文件。图片、视频、音频。
f1 = open('d:你想看的都在这.txt', encoding='utf-8', mode='r')
content = f1.read()
print(content)
f1.close()
"""
open 内置函数,open底层调用的是操作系统的接口。
f1 变量 f 文件句柄。 对文件进行的任何操作,都要通过文件句柄.操作函数()的方式。
encoding:参数可以默认不写,默认编码本为操作系统默认的编码。
widows:gbk。
Linux:utf-8。
mac:utf-8。
f1.close() 关闭文件
"""
"""
文件操作三部曲:
1.打开文件
2.对文件句柄进行相应的操作
3.关闭文件
"""
- 文件的写
w, wb,w+, w+b
# f = open('文件的写', encoding='utf-8', mode='w')
# f.write('随便写一点')
# f.close()
# 如果文件存在,先清空原文件内容,再写入新内容
# f = open('文件的写', encoding='utf-8', mode='w')
# f.write('木子李呢')
# f.close()
# wb
f = open('头像.png', mode='rb')
content = f.read()
# b'xffxd8xffxe0x00x10JFIFx00x01x01x00x00Hx00Hx00.......
# print(content)
f.close()
f1 = open('头像2.png', mode='wb')
f1.write(content)
f1.close()
- 文件的追加
a, ab, a+ , a+b
# 没有文件创建,追加内容
# f = open('文件的追加', encoding='utf-8', mode='a')
# f.write('nihao')
# f.close()
# 有文件时,在原文件的最后边追加
f = open('文件的追加', encoding='utf-8', mode='a')
f.write('李波')
f.close()
- 文件操作的其他模式
# 先读后写 若无文件不会创建新文件
# 读并追加,顺序不能反
f = open('文件的读写', encoding='utf-8', mode='r+')
content = f.read()
print(content)
f.write('人的一切痛苦,都是对自己无能的愤怒!')
f.close()
- 打开文件的另一种方式
with ... as ...
# 优点1:不用手动关闭文件句柄
# with open('文件的读', encoding='utf-8') as f1:
# print(f1.read())
# 优点2: 一个with可以打开多个open
with open('文件的读', encoding='utf-8') as f1,
open('文件的写', encoding='utf-8', mode='w') as f2:
print(f1.read())
f2.write('dasdasd a')
# 缺点:待续.
- 文件的修改
"""
1.以读的模式打开原文件.
2.以写的模式创建一个新文件.
3.将原文件的内容读出来修改成新内容,写入新文件.
4.将原文案金删除.
5.将新文件重命名成原文件.
"""
# low版
import os
with open('alex自述', encoding='utf-8') as f1,
open('alex自述.bak', encoding='utf-8', mode='w') as f2:
old_content = f1.read()
new_content = old_content.replace('分手', '恋爱')
f2.write(new_content)
os.remove('alex自述')
os.rename('alex自述.bak', 'alex自述')
分手第1次,第21天后,你找到我说还是喜欢我。我相信了,继续牵着你的手走过校园的每一个角落。
分手第2次,第32天后,你还是回来了,我还笑着跟朋友说“不是我忘不掉,而是人家忘不掉”。
分手第3次,第5天,我们终于不再联系,我拉黑你的QQ,删掉你的号码和相片,丢掉你送的礼物,从此陌路。
分手第3次,第10天,我整理日记,丢掉专门为你写的那本,想着以前我送你的那些日记,现在你还留着吗?
恋爱第1次,第21天后,你找到我说还是喜欢我。我相信了,继续牵着你的手走过校园的每一个角落。
恋爱第2次,第32天后,你还是回来了,我还笑着跟朋友说“不是我忘不掉,而是人家忘不掉”。
恋爱第3次,第5天,我们终于不再联系,我拉黑你的QQ,删掉你的号码和相片,丢掉你送的礼物,从此陌路。
恋爱第3次,第10天,我整理日记,丢掉专门为你写的那本,想着以前我送你的那些日记,现在你还留着吗?
"""
1.以读的模式打开原文件.
2.以写的模式创建一个新文件.
3.将原文件的内容读出来修改成新内容,写入新文件.
4.将原文案金删除.
5.将新文件重命名成原文件.
"""
# 进阶版
import os
with open('alex自述', encoding='utf-8') as f1,
open('alex自述.bak', encoding='utf-8', mode='w') as f2:
for line in f1:
# 第一次循环 恋爱第1次,第21天后,你找到我说还是喜欢我。我相信了,继续牵着你的手走过校园的每一个角落。
# old_line = line.strip() # 去除两边空格
new_line = line.replace('恋爱', 'alex')
f2.write(new_line)
os.remove('alex自述')
os.rename('alex自述.bak', 'alex自述')
# 有关清空问题:
# 不关闭文件句柄的情况下多次写入是不会清空之前的内容的
alex第1次,第21天后,你找到我说还是喜欢我。我相信了,继续牵着你的手走过校园的每一个角落。
alex第2次,第32天后,你还是回来了,我还笑着跟朋友说“不是我忘不掉,而是人家忘不掉”。
alex第3次,第5天,我们终于不再联系,我拉黑你的QQ,删掉你的号码和相片,丢掉你送的礼物,从此陌路。
alex第3次,第10天,我整理日记,丢掉专门为你写的那本,想着以前我送你的那些日记,现在你还留着吗?
Day 06
一、初识函数
# s1 = 'dsadasdasdasdasasd'
# # pyhton没有len()的话
# count = 0
# for i in s1:
# count += 1
# print(count)
#
# count = 0
# l1 = [1, 2, 3, 4, 5, 6]
#
# for i in l1:
# count += 1
# print(count)
# 代码重复太多
# 代码可读性差
# 函数式编程
def my_len(s):
count = 0
for i in s:
count += 1
print(count)
s1 = 'dsadasdasdasdasasd'
l1 = [1, 2, 3, 4, 5, 6]
my_len(s1)
my_len(l1)
# 函数:以功能(完成一件事)为导向,登录,注册,len。一个函数就是一个功能。随调随用
# 减少代码重复性,增强代码的可读性
二、函数的结构与调用
def meet():
print('打开探探')
print('左滑一下')
print('右滑一下')
print('找美女')
print('悄悄话')
print('约 .... 走起 ...')
"""
结构:def 关键字,定义函数。
meet 函数名:与变量设置相同,具有可描述性。
函数体:缩进。函数中尽量不要出现print。
"""
# 函数什么时候执行?
# 当遇到函数名加括号时执行。
meet()
三、函数的返回值
# 函数的返回值
def meet():
print('打开探探')
print('左滑一下')
print('右滑一下')
print('找美女')
print('悄悄话')
print('约 .... 走起 ...')
# return '妹纸'
return '妹子', 123, [22, 33]
# return :在函数中遇到return直接结束函数。
# return:将数据返回给函数的执行者,调用者meet()。
# return饭hi多个元素是以元组的形式返回给函数的执行者。
# ret = meet()
# print(ret)
print(type(meet())) # <class 'tuple'>
"""
retuen 总结:
1.在函数中,终止函数。
2.return 可以给函数的执行者返回值。
1)return 单个值 单个值
2)return 多个值 (多个值,)
"""
四、函数的参数
# 函数的参数
# def meet(sex): # 函数的定义:接受的参数是形式参数。
# print('打开探探')
# print('进行筛选:性别:%s' % sex)
# print('左滑一下')
# print('右滑一下')
# print('找美女')
# print('悄悄话')
# print('约 .... 走起 ...')
# 函数的传参:让函数的封装的这个功能,盘活。
# 实参,形参。
# meet('男')
# meet('女') # 函数的执行传的参数:实际参数。
# 函数的传参:实参,形参。
# 实参角度:
# 1.位置参数。从左到右一一对应。
# def meet(sex, age, skill, voice): # 函数的定义:接受的参数是形式参数。
# print('打开探探')
# print('进行筛选:性别:%s,年龄:%s,python: %s, 声音:%s' % (sex, age, skill, voice))
# print('左滑一下')
# print('右滑一下')
# print('找美女')
# print('悄悄话')
# print('约 .... 走起 ...')
# meet('女', '18~40', 'python技术好的', '萝莉音') # 函数的执行传的参数:实际参数。
# 写一个函数,只接受两个int的函数,函数的功能是将较大的数返回。
# def max_num(a, b):
# # if a > b:
# # return a
# # else:
# # return b
# return a if a > b else b # 三元运算符
# c = max_num(100, 1000)
# print(c)
# 2. 关键字参数
# 一一对应,顺序可以不打乱
# def meet(sex, age, skill, hight, weight): # 函数的定义:接受的参数是形式参数。
# print('打开探探')
# print('进行筛选:性别:%s,年龄:%s,技术: %s, 身高:%s, 体重: %s' % (sex, age, skill, hight, weight))
# print('左滑一下')
# print('右滑一下')
# print('找美女')
# print('悄悄话')
# print('约 .... 走起 ...')
# meet('女', '25', 'python技术好的', 174, 130) # 函数的执行传的参数:实际参数。
# meet(sex='女', age='25', weight=100, hight=174, skill='python技术好的')
# # 函数:传入两个字符串参数,将两个参数拼接完成后形成的结果返回
# def func(s1, s2):
# return s1 + s2
# print(func(s1='Hello', s2='libo!'))
# 混合参数
# 位置参数一定要在关键字参数前边
# def meet(sex, age, skill, hight, weight): # 函数的定义:接受的参数是形式参数。
# print('打开探探')
# print('进行筛选:性别:%s,年龄:%s,技术: %s, 身高:%s, 体重: %s' % (sex, age, skill, hight, weight))
# print('左滑一下')
# print('右滑一下')
# print('找美女')
# print('悄悄话')
# print('约 .... 走起 ...')
# return '筛选结果:性别:%s, 体重: %s' % (sex, weight)
# # print(meet(25, weight=100, '女', hight=174, skill='python技术好的')) 位置参数未在关键字参数前边 报错
# print(meet('女', 25, weight=100, hight=174, skill='python技术好的'))
"""
实参角度:
1.位置参数 按照顺序,一一对应
2.关键字参数,一一对应
3.混合参数:位置参数一定要在关键字参数的前边
"""
# 形参角度
# 1.位置参数 与实参角度的位置参数是一种
# 写一个函数,检测传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
# def func(l1):
# # l2 = l1
# # if len(l1) > 2:
# # l2 = l1[0:2]
# # return l2
# # return l1[0:2] if len(l1) > 2 else l1
# return l1[0:2]
# print(func([1,2,3,4,5]))
# print(func([1,]))
# 默认参数
# 默认参数一定得在最后。
# 默认参数设置的意义:普遍经常用的。
# def meet(age, skill='python技术好的', sex='女'): # 函数的定义:接受的参数是形式参数。
# # print('打开探探')
# # print('进行筛选:性别:%s,年龄:%s,技术: %s' % (sex, age, skill))
# # print('左滑一下')
# # print('右滑一下')
# # print('找美女')
# # print('悄悄话')
# # print('约 .... 走起 ...')
# # # print(meet(25, 'pytohn技术好的'))
# # # print(meet(25,'pytohn技术好的', sex='男'))
# # print(meet(25,'运维技术好的', sex='男'))
# 形参角度:
# 1.位置参数
# 2.默认参数 经常用的参数
Day07
今日内容大纲
1.如何在工作中不让别人看出来你是培训出来的?
- 第一天环境安装等等,小白各种问。
- 项目需求不清晰,也不敢问。
- 一定要学会自主学习,有自己解决问题的能力。
2.形参角度 - 万能参数
-
- 的魔性用法
- 仅限关键字参数
- 形参 的最终顺寻
3.名称空间 - 全局名称空间
- 加载顺序,取值顺序。
- 作用域
4.函数的嵌套(高阶函数)
5.内置函数(globals locals)
6.关键字:nonlocal global
昨日内容回顾
1.函数是以功能为导向,减少重复代码,提高代码的可读性。
2.函数结构
def func():
函数体
3.函数的调用:func()
func()
func()
func()
# 写一次执行一次
4.函数的返回值
- 终止函数
- return单个值
- return多个之:(1,2,3,'alex')
5.函数的参数 - 实参角度:位置参数,关键字参数,混合参数。
- 形参角度:位置参数,默认参数。
今日内容学习记录
https://github.com/libo-sober/LearnPython/tree/master/day07
今日总结
- 参数:万能参数,仅限关键字参数,参数的顺序,*的魔性用法:聚合和打散。
- 名称空间,作用域,取值 顺序,加载顺序。
- globals() locals()
- 高阶函数:执行顺序。
- 以上全是重点。
Day08
今日内容大纲
- global nonlocal
- 函数名的运用
- 新特性:格式化输出。
- 迭代器:
- 可迭代对象
字面意思:对象?python中一切皆对象。一个实实在在存在的值,对象。
可迭代?:更新迭代。重复的,循环的一个过程,更新迭代每次都要新的内容。
可以进行循环更新的以恶搞是实实在在的值。
专业角度:可迭代对象?内部含有”iter“方法的对象,可迭代对象。
目前学过的可迭代对象?str list tuple set dict range 文件句柄 - 获取对象的所有方法并且以字符串的形式表现出来
- 可迭代对象
# 获取一个对象的所以方法:dir()
s1 = 'sdsdasasdas'
print(dir(s1))
l1 = [1,2,3]
print(dir(l1))
print('__iter__' in dir(l1)) # True
- 判断一个对象是否是可迭代对象
- 小结
字面意思:对象?python中一切皆对象。一个实实在在存在的值,对象。
专业角度:可迭代对象?内部含有”__iter__“方法的对象,可迭代对象。
优点:1.存储的数据直接能显示,比较直观。2.拥有的方法比较多,操作很方便。
缺点:1.占用内存。2.不能直接通过for循环,不能直接取值。
- 迭代器
- 迭代器的定义
字面意思:更新迭代,器:工具:可更新迭代的工具。
专业角度:内部含有内部含有”__iter__“方法并且含有"__next__"方法的对象就是迭代器。
可以判断是否是迭代器:有”__iter__“ and "__next__"方法在不在dir(对象)
文件句柄`with open('wenjian', encoding='utf-8', mode='w') as f1:
print('__iter__' in dir(f1) and '__next__' in dir(f1))` 输出True。
- 判断一个对象是否是迭代器
- 迭代器的取值
s1 = 'dasdasdas'
obj = iter(s1) # s1.__iter__()
# print(obj) # <str_iterator object at 0x0000022770E5EB70>
print(next(obj)) # d
print(obj.__next__()) # a
l1 = [11,22,33,44,55]
obj = l1.__iter__()
print(obj.__next__())
print(obj.__next__())
print(obj.__next__())
print(obj.__next__())
print(obj.__next__())
- 可迭代对象如何转化成迭代器
- while循环模拟for循环机制
# while循环模拟for循环机制
l1 = [1,2,3,4,5,6,7,8]
# for i in l1: # 先转换成迭代器
# print(i)
# 将可迭代对象转换成迭代器
obj = l1.__iter__()
while True:
try:
print(next(obj))
except StopIteration:
break
- 小结
字面意思:更新迭代,器:工具:可更新迭代的工具。
专业角度:内部含有内部含有”__iter__“方法并且含有"__next__"方法的对象就是迭代器。
可以判断是否是迭代器:有”__iter__“ and "__next__"方法在不在dir(对象)
优点:1.节省内存。2.惰性机制,next一次,去一个值。
缺点:速度慢。以时间换空间。2.不走回头路。
- 可迭代对象与迭代器的对比
可迭代对象是一个操作方法比较多,比较直观,存储数据相对小的一个数据集。对数据灵活处理,内存足够。
迭代器:节省内存,可以记录位置。数据量过大。
昨日内容回顾
- 函数的参数:
- 实参角度:位置参数,关键字参数,混合参数。
- 形参角度:位置参数,默认参数,仅限关键字参数,万能参数。
- 形参角度参数顺序:位置参数-->*args-->默认参数-->仅限关键字参数-->**kwargs
- *的魔性用法:
- 函数定义时:代表聚合。
- 函数调用时:代表打散。
- python中存在三种空间:
- 内置名称空间:存储的时内置函数:print、input.......
- 全局名称空间:py文件存放的时py文件(出去函数,类内部的)变量,函数名与函数的内存地址的关系。
- 局部名称空间:存放的是函数内部的变量与值的对应关系。
- 加载顺序:内置名称空间-->全局名称空间-->局部名称空间(执行函数的时候)
- 取值顺序:就近原则即LEGB原则。
- 局部作用域只能引用全局变量,不能修改。
name = 'alex'
def func():
name = name + 'sb' # 报错
- 作用域:
- 全局作用域:内置名称空间+全局名称空间。
- 局部作用域:局部名称空间。
- 函数的嵌套
- gloabls() (获取全部的变量 ) locals()(获取当前的变量)
今日学习代码记录
https://github.com/libo-sober/LearnPython/tree/master/day08
今日总结
- 默认参数的坑,作用域的坑(重点)
- 格式化输出
- 函数名的应用
- 对比:迭代器是什么?迭代器的优缺点。(重点)可迭代对象如何转化成迭代器。