之前写了一个存储过程
目标: 根据时间,获取指定范围的数据集A, 再从数据集A 中,取出每行数据中的两个时间,卡另外一个B表里面的某列时间范围的值集。得到均值进行配置值比对。
这里有个问题,就是取得B 表的值集是取得不同列,B 表有11列,那么就有11组值集。这里涉及到了行列转换。
最开始的办法: ----》取数据集A -------》循环----------》取数据集B --------》运算+传入列名得到均值----------》 与配置表进行比对
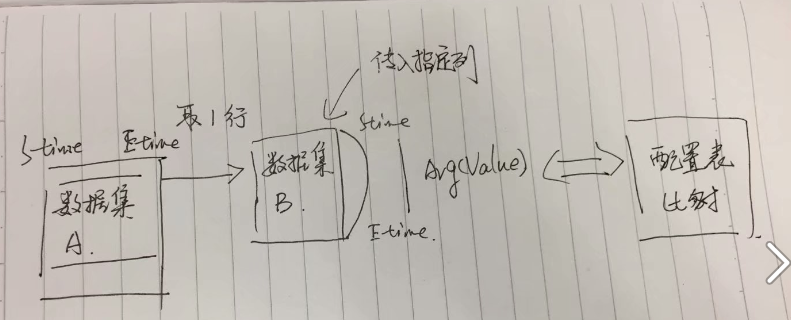
问题在于:1.A 表数据量很大,取2个小时的数据,数据量也在万笔。2. B 表时间段卡的数据量也大,而且列是不指定的,每次执行就需要把所有的列单独导入,很好时间,初步的存储过程写好后,执行时间在10分钟以上。
上面的想法会有一个问题,就是B 表同一个时间段,会根据A表的数据导入多次,这是无意义的动作,因为A表在取数据的时候,已经设置了最小时间。
那么就可以优化,把A 表大于最小时间的数据倒叙,取第一行数据就是最大时间, 再根据最大和最小时间,把B 表里面的数据先通过游标进行11列的行列数据转换,放入一个临时表中,循环A表,再进行Group by 得到11列的所有的avg值,和配置表进行比对。
时间可控制在00:00:02
用游标进行循环时,可以取多个值使用:这里方便了限制配置表的条件,和时间范围
FETCH NEXT FROM teCursor into @STime,@ETime,@Resoa;
还有一个就是B 表的行列转换
没有采用标准的方式,而是用了把列作为变量的形式传入,但是在sql 中select @变量 from表,是不成立的。
只能把语句进行拼接,set 给一个变量@sql,然后使用exec @sql
''InP - BFC_''+'''+@parameterName+''' as ParameterName
这里就要注意单引号这部分了。
有些小的东西
1. 判断表里面是否有数据,有数据再去处理,没有就继续循环
if exists( select * from #EndData)
2.执行前对临时表进行清理判断,回收
IF OBJECT_ID('TEMPDB.DBO.#EndData') IS NOT NULL BEGIN DROP TABLE #EndData END
如下为游标的片段,并不能直接使用(切记)因为并没有对所有的变量进行定义
DECLARE teCursor CURSOR FOR(SELECT TrackInTime,TrackOutTime,Recipe FROM #Datatable) OPEN teCursor; FETCH NEXT FROM teCursor into @STime,@ETime,@Resoa; WHILE @@FETCH_STATUS = 0 BEGIN IF OBJECT_ID('TEMPDB.DBO.#EndData') IS NOT NULL BEGIN DROP TABLE #EndData END SELECT Dat.* INTO #EndData FROM (SELECT * FROM #TEST) Dat if exists( select * from #EndData) begin print 1 end else begin print 2 end FETCH NEXT FROM teCursor into @STime,@ETime,@Resoa; END CLOSE teCursor; DEALLOCATE teCursor