Selenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操作,方便各种 Web 应用的自动化测试。它的取名很有意思,因为当时最流行的一款自动化测试工具叫做QTP,是由 Mercury 公司开发的商业应用。Mercury 是化学元素汞,而 Selenium 是化学元素硒,汞有剧毒,而硒可以解汞毒,它对汞有拮抗作用。
Selenium 的核心组件叫做 Selenium-RC(Remote Control),简单来说它是一个代理服务器,浏览器启动时通过将它设置为代理,它可以修改请求响应报文并向其中注入 Javascript,通过注入的 JS 可以模拟浏览器操作,从而实现自动化测试。但是注入 JS 的方法存在很多限制,譬如无法模拟键盘和鼠标事件,处理不了对话框,不能绕过 JavaScript 沙箱等等。就在这个时候,于 2006 年左右,Google 的工程师 Simon Stewart 发起了 WebDriver 项目,WebDriver 通过调用浏览器提供的原生自动化 API 来驱动浏览器,解决了 Selenium 的很多疑难杂症。不过 WebDriver 也有它不足的地方,它不能支持所有的浏览器,需要针对不同的浏览器来开发不同的 WebDriver,因为不同的浏览器提供的 API 也不尽相同,好在经过不断的发展,各种主流浏览器都已经有相应的 WebDriver 了。最终 Selenium 和 WebDriver 合并在一起,这就是 Selenium 2.0,有的地方也直接把它称作 WebDriver。Selenium 目前最新的版本已经是 3.9 了,WebDriver 仍然是 Selenium 的核心。
一、Selenium 爬虫入门
Selenium 的初衷是打造一款优秀的自动化测试工具,但是慢慢的人们就发现,Selenium 的自动化用来做爬虫正合适。我们知道,传统的爬虫通过直接模拟 HTTP 请求来爬取站点信息,由于这种方式和浏览器访问差异比较明显,很多站点都采取了一些反爬的手段,而 Selenium 是通过模拟浏览器来爬取信息,其行为和用户几乎一样,反爬策略也很难区分出请求到底是来自 Selenium 还是真实用户。而且通过 Selenium 来做爬虫,不用去分析每个请求的具体参数,比起传统的爬虫开发起来更容易。Selenium 爬虫唯一的不足是慢,如果你对爬虫的速度没有要求,那使用 Selenium 是个非常不错的选择。Selenium 提供了多种语言的支持(Java、.NET、Python、Ruby 等),不论你是用哪种语言开发爬虫,Selenium 都适合你。
我们第一节先通过 Python 学习 Selenium 的基础知识,后面几节再介绍我在使用 Selenium 开发浏览器爬虫时遇到的一些问题和解决方法。
1.1 Hello World
一个最简单的 Selenium 程序像下面这样:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
这段代码理论上会打开 Chrome 浏览器,并访问百度首页。但事实上,如果你第一次使用 Selenium,很可能会遇到下面这样的报错:
selenium.common.exceptions.WebDriverException:
Message: 'chromedriver' executable needs to be in PATH.
Please see https://sites.google.com/a/chromium.org/chromedriver/home
报错提示很明确,要使用 Chrome 浏览器,必须得有 chromedriver,而且 chromedriver 文件位置必须得配置到 PATH 环境变量中。chromedriver 文件可以通过错误提示中的地址下载。不过在生产环境,我并不推荐这样的做法,使用下面的方法可以手动指定 chromedriver 文件的位置:
from selenium import webdriver
browser = webdriver.Chrome(executable_path="./drivers/chromedriver.exe")
browser.get('http://www.baidu.com/')
这里给出的例子是 Chrome 浏览器,Selenium 同样可以驱动 Firefox、IE、Safari 等。这里列出了几个流行浏览器webdriver的下载地址。Selenium 的官网也提供了大多数浏览器驱动的下载信息,你可以参考 Third Party Drivers, Bindings, and Plugins 一节。
1.2 输入和输出
通过上面的一节,我们已经可以自动的通过浏览器打开某个页面了,作为爬虫,我们还需要和页面进行更多的交互,归结起来可以分为两大类:输入和输出。
输入指的是用户对浏览器的所有操作,譬如上面的直接访问某个页面也是一种输入,或者在输入框填写,下拉列表选择,点击某个按钮等等;
输出指的是根据输入操作,对浏览器所产生的数据进行解析,得到我们需要的数据;这里 浏览器所产生的数据 不仅包括可见的内容,如页面上显示的信息,也还包括不可见的内容,如 HTML 源码,甚至浏览器所发生的所有 HTTP 请求报文。
下面还是以百度为例,介绍几种常见的输入输出方式。
1.2.1 输入
我们打开百度进行搜索,如果是人工操作,一般有两种方式:第一种,在输入框中输入搜索文字,然后回车;第二种,在输入框中输入搜索文字,然后点击搜索按钮。Selenium 和人工操作完全一样,可以模拟这两种方式:
方式一 send keys with return
from selenium.webdriver.common.keys import Keys
kw = browser.find_element_by_id("kw")
kw.send_keys("Selenium", Keys.RETURN)
其中 find_element_by_id 方法经常用到,它根据元素的 ID 来查找页面某个元素。类似的方法还有 find_element_by_name、find_element_by_class_name、find_element_by_css_selector、find_element_by_xpath 等,都是用于定位页面元素的。另外,也可以同时定位多个元素,例如 find_elements_by_name、find_elements_by_class_name 等,就是把 find_element 换成 find_elements,具体的 API 可以参考 Selenium 中文翻译文档中的 查找元素 一节。
通过 find_element_by_id 方法拿到元素之后,就可以对这个元素进行操作,也可以获取元素的属性或者它的文本。kw 这个元素是一个 input 输入框,可以通过 send_keys 来模拟按键输入。不仅可以模拟输入可见字符,也可以模拟一些特殊按键,譬如回车 Keys.RETURN,可模拟的所有特殊键可以参考 这里。
针对不同的元素,有不同的操作,譬如按钮,可以通过 click 方法来模拟点击,如下。
方式二 send keys then click submit button
kw = browser.find_element_by_id("kw")
su = browser.find_element_by_id("su")
kw.send_keys("Selenium")
su.click()
如果这个元素是在一个表单(form)中,还可以通过 submit 方法来模拟提交表单。
方式三 send keys then submit form
kw = browser.find_element_by_id("kw")
kw.send_keys("Selenium")
kw.submit()
submit 方法不仅可以直接应用在 form 元素上,也可以应用在 form 元素里的所有子元素上,submit 会自动查找离该元素最近的父 form 元素然后提交。这种方式是程序特有的,有点类似于直接在 Console 里执行 $('form').submit() JavaScript 代码。由此,我们引出第四种输入方法,也是最最强大的输入方法,可以说几乎是无所不能,直接在浏览器里执行 JavaScript 代码:
方式四 execute javascript
browser.execute_script(
'''
var kw = document.getElementById('kw');
var su = document.getElementById('su');
kw.value = 'Selenium';
su.click();
'''
)
这和方式二非常相似,但是要注意的是,方式四是完全通过 JavaScript 来操作页面,所以灵活性是无限大的,几乎可以做任何操作。除了这些输入方式,当然还有其他方式,譬如,先在输入框输入搜索文字,然后按 Tab 键将焦点切换到提交按钮,然后按回车,原理都是大同小异,此处不再赘述,你可以自己写程序试一试。
另外,对于 select 元素,Selenium 单独提供了一个类 selenium.webdriver.support.select.Select 可以方便元素的选取。其他类型的元素,都可以通过上述四种方式来处理。
1.2.2 输出
有输入就有输出,当点击搜索按钮之后,如果我们要爬取页面上的搜索结果,我们有几种不同的方法。
方式一 parse page_source
html = browser.page_source
results = parse_html(html)
第一种方式最原始,和传统爬虫几无二致,直接拿到页面源码,然后通过源码解析出我们需要的数据。但是这种方式存在缺陷,如果页面数据是通过 Ajax 动态加载的,browser.page_source 获取到的是最初返回的 HTML 页面,这个 HTML 页面可能啥都没有。这种情况,我们可以通过遍历页面元素来获取数据,如下:
方式二 find & parse elements
results = browser.find_elements_by_css_selector("#content_left .c-container")
for result in results:
link = result.find_element_by_xpath(".//h3/a")
print(link.text)
这种方式需要充分利用上面介绍的 查找元素 技巧,譬如这里如果要解析百度的搜索页面,我们可以根据 #content_left .c-container 这个 CSS 选择器定位出每一条搜索结果的元素节点。然后在每个元素下,通过 XPath .//h3/a 来取到搜索结果的标题的文本。XPath 在定位一些没有特殊标志的元素时特别有用。
方式三 intercept & parse ajax
方式二在大多数情况下都没问题,但是有时候还是有局限的。譬如页面通过 Ajax 请求动态加载,某些数据在 Ajax 请求的响应中有,但在页面上并没有体现,而我们恰恰想要爬取 Ajax 响应中的那些数据,这种情况上面两种方式都无法实现。我们能不能拦截这些 Ajax 请求,并对其响应进行解析呢?这个问题我们放在后面一节再讲。
1.3 处理 Ajax 页面
上面也提到过,如果页面上有 Ajax 请求,使用 browser.page_source 得到的是页面最原始的源码,无法爬到百度搜索的结果。事实上,不仅如此,如果你试过上面 方式二 find & parse elements 的例子,你会发现用这个方式程序也爬不到搜索结果。这是因为 browser.get() 方法并不会等待页面完全加载完毕,而是等到浏览器的 onload 方法执行完就返回了,这个时候页面上的 Ajax 可能还没加载完。如果你想确保页面完全加载完毕,当然可以用 time.sleep() 来强制程序等待一段时间再处理页面元素,但是这种方法显然不够优雅。或者自己写一个 while 循环定时检测某个元素是否已加载完,这个做法也没什么问题,但是我们最推荐的还是使用 Selenium 提供的 WebDriverWait 类。
WebDriverWait 类经常和 expected_conditions 搭配使用,注意 expected_conditions 并不是一个类,而是一个文件,它下面有很多类,都是小写字母,看起来可能有点奇怪,但是这些类代表了各种各样的等待条件。譬如下面这个例子:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
WebDriverWait(browser, 10).until(
expected_conditions.presence_of_element_located((By.ID, "kw"))
)
代码的可读性很好,基本上能看明白这是在等待一个 id 为 kw 的元素出现,超时时间为 10s。不过代码看起来还是怪怪的,往往我们会给 expected_conditions 取个别名,譬如 Expect,这样代码看起来更精简了:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait as Wait
from selenium.webdriver.support import expected_conditions as Expect
Wait(browser, 10).until(
Expect.presence_of_element_located((By.ID, "kw"))
)
我们再以一个实际的例子来看看 expected_conditions 的强大之处,譬如在 途牛网上搜索上海到首尔的航班,这个页面的航班结果都是以 Ajax 请求动态加载的,我们如何等待航班全部加载完毕之后再开始爬取我们想要的航班结果呢?通过观察可以发现,在 “开始搜索”、“搜索中” 以及 “搜索结束” 这几个阶段,页面显示的内容存在比较明显的差异,如下图所示:

我们就可以通过这些差异来写等待条件。要想等到航班加载完毕,页面上应该会显示 “共搜索xx个航班” 这样的文本,而这个文本在 id 为 loadingStatus 的元素中。expected_conditions 提供的类 text_to_be_present_in_element 正满足我们的要求,可以像下面这样:
Wait(browser, 60).until(
Expect.text_to_be_present_in_element((By.ID, "loadingStatus"), u"共搜索")
)
下面是完整的代码,可见一个浏览器爬虫跟传统爬虫比起来还是有些差异的,浏览器爬虫关注点更多的在页面元素的处理上。
|
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait as Wait
from selenium.webdriver.support import expected_conditions as Expect
browser = webdriver.Chrome(executable_path="./drivers/chromedriver.exe")
browser.get('http://www.tuniu.com/flight/intel/sha-sel')
Wait(browser, 60).until(
Expect.text_to_be_present_in_element((By.ID, "loadingStatus"), u"共搜索")
)
flight_items = browser.find_elements_by_class_name("flight-item")
for flight_item in flight_items:
flight_price_row = flight_item.find_element_by_class_name("flight-price-row")
print(flight_price_row.get_attribute("data-no"))
|
除了上面提到的 presence_of_element_located 和 text_to_be_present_in_element 这两个等待条件,Selenium 还提供了很多有用的条件类,参见 Selenium 的 WebDriver API。
二、Selenium 如何使用代理服务器?
通过上一节的介绍,相信你也可以用 Selenium 写一个简单的爬虫了。虽然 Selenium 完全模拟了人工操作,给反爬增加了点困难,但是如果网站对请求频率做限制的话,Selenium 爬虫爬快了一样会遭遇被封杀,所以还得有代理。
代理是爬虫开发人员永恒的话题。所以接下来的问题就是怎么在 Selelium 里使用代理,防止被封杀?我在很久之前写过几篇关于传统爬虫的博客,其中也讲到了代理的话题,有兴趣的同学可以参考一下 Java 和 HTTP 的那些事(二) 使用代理。
在写代码之前,我们要了解一点,Selenium 本身是和代理没关系的,我们是要给浏览器设置代理而不是给 Selenium 设置,所以我们首先要知道浏览器是怎么设置代理的。浏览器大抵有五种代理设置方式,第一种是直接使用系统代理,第二种是使用浏览器自己的代理配置,第三种通过自动检测网络的代理配置,这种方式利用的是 WPAD 协议,让浏览器自动发现代理服务器,第四种是使用插件控制代理配置,譬如 Chrome 浏览器的 Proxy SwitchyOmega 插件,最后一种比较少见,是通过命令行参数指定代理。这五种方式并不是每一种浏览器都支持,而且设置方式可能也不止这五种,如果还有其他的方式,欢迎讨论。
直接使用系统代理无需多讲,这在生产环境也是行不通的,除非写个脚本不断的切换系统代理,或者使用自动拨号的机器,也未尝不可,但这种方式不够 programmatically。而浏览器自己的配置一般来说基本上都会对应命令行的某个参数开关,譬如 Chrome 浏览器可以通过 --proxy-server 参数来指定代理:
chrome.exe http://www.ip138.com --proxy-server=127.0.0.1:8118
注:执行这个命令之前,要先将现有的 Chrome 浏览器窗口全部关闭,如果你的 Chrome 安装了代理配置的插件如 SwitchyOmega,还需要再加一个参数 --disable-extensions 将插件禁用掉,要不然命令行参数不会生效。
2.1 通过命令行参数指定代理
使用 Selenium 启动浏览器时,也可以指定浏览器的启动参数。像下面这样即可:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=127.0.0.1:8118')
browser = webdriver.Chrome(
executable_path="./drivers/chromedriver.exe",
chrome_options=chrome_options
)
browser.get('http://ip138.com')
这里的 --proxy-server 参数格式为 ip:port,注意它不支持这种带用户名密码的格式 username:password@ip:port,所以如果代理服务器需要认证,访问网页时就会弹出一个认证对话框来。虽然使用 Selenium 也可以在对话框中填入用户名和密码,不过这种方式略显麻烦,而且每次 Selenium 启动浏览器时,都会弹出代理认证的对话框。更好的做法是,把代理的用户名和密码都提前设置好,对于 Chrome 浏览器来说,我们可以通过它的插件来实现。
2.2 使用插件控制代理
Chrome 浏览器下最流行的代理配置插件是 Proxy SwitchyOmega,我们可以先配置好 SwitchyOmega,然后 Selenium 启动时指定加载插件,Chrome 提供了下面的命令行参数用于加载一个或多个插件:
chrome.exe http://www.ip138.com --load-extension=SwitchyOmega
不过要注意的是,--load-extension 参数只能加载插件目录,而不能加载打包好的插件 *.crx 文件,我们可以把它当成 zip 文件直接解压缩到 SwitchyOmega 目录即可。代码如下:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--load-extension=SwitchyOmega')
browser = webdriver.Chrome(
executable_path="./drivers/chromedriver.exe",
chrome_options=chrome_options
)
browser.get('http://ip138.com')
另外,Selenium 的 ChromeOptions 类还提供了一个方法 add_extension 用于直接加载未解压的插件文件,如下:
chrome_options.add_extension('SwitchyOmega.crx')
这种做法应该是可行的,不过我没有具体去尝试,因为这种做法依赖于 SwitchyOmega 的配置,如何在加载插件之前先把代理都配好?如何运行时动态的切换代理?这对爬虫来说至关重要,以后有时候再去研究吧。不过很显然,直接使用 SwitchyOmega 插件有点重了,我们能不能自己写一个简单的插件来实现代理控制呢?
当然可以。而且这个插件只需要两行代码即可。
关于 Chrome 插件的编写,我之前有过两篇博客:我的第一个Chrome扩展:Search-faster 和 我的第二个Chrome扩展:JSONView增强版,感兴趣的同学可以先看看这两篇了解下如何写一个 Chrome 插件。这里略过不提,我们这个插件需要有两个文件,一个是 manifest.json 文件,为插件的清单文件,每个插件都要有,另一个是 background.js 文件,它是背景脚本,类似于后台驻留进程,它就是代理配置插件的核心。
下面我们就来看看这两行代码,第一行如下:
|
chrome.proxy.settings.set({
value: {
mode: "fixed_servers",
rules: {
singleProxy: {
scheme: "http",
host: "127.0.0.1",
port: 8118
},
bypassList: ["foobar.com"]
}
},
scope: "regular"
}, function() {});
|
chrome.proxy 是用于管理 Chrome 浏览器的代理服务器设置的 API,上面的代码通过其提供的方法 chrome.proxy.settings.set() 设置了一个代理服务器地址,mode 的值为 fixed_servers 表示根据下面的 rules 来指定某个固定的代理服务器,代理类型可以是 HTTP 或 HTTPS,还可以是 SOCKS 代理。mode 的值还可以是 direct(无需代理),auto_detect(通过 WPAD 协议自动检测代理),pac_script(通过 PAC 脚本动态选取代理)和 system(使用系统代理)。关于这个 API 的详细说明可以参看 Chrome 的 官方文档,这里有一份 中文翻译。
通过上面的代码也只是设置了代理服务器的 IP 地址和端口而已,用户名和密码还没有设置,这和使用命令行参数没什么区别。所以还需要下面的第二行代码:
|
chrome.webRequest.onAuthRequired.addListener(
function (details) {
return {
authCredentials: {
username: "username",
password: "password"
}
};
},
{ urls: ["<all_urls>"] },
[ 'blocking' ]
);
|
我们先看看下面这张图,了解下 Chrome 浏览器接受网络请求的整个流程,一个成功的请求会经历一系列的事件(图片来源):
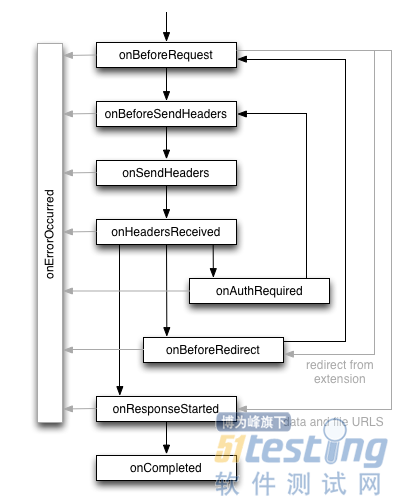
这些事件都是由 chrome.webRequest API 提供,其中的 onAuthRequired 最值得我们注意,它是用于代理身份认证的关键。所有的事件都可以通过 addListener 方法注册一个回调函数作为监听器,当请求需要身份认证时,回调函数返回代理的用户名和密码。除了回调方法,addListener 第二个参数用于指定该代理适用于哪些 url,这里的 <all_urls> 是固定的特殊语法,表示所有的 url,第三个参数字符串 blocking 表示请求将被阻塞,回调函数将以同步的方式执行。这个 API 也可以参考 Chrome 的 官方文档,这里是 中文翻译。
综上,我们就可以写一个简单的代理插件了,甚至将插件做成动态生成的,然后 Selenium 动态的加载生成的插件。完整的源码在 这里。
三、Selenium 如何过滤非必要请求?
Selenium 配合代理,你的爬虫几乎已经无所不能了。上面说过,Selenium 爬虫虽然好用,但有个最大的特点是慢,有时候太慢了也不是办法。由于每次打开一个页面 Selenium 都要等待页面加载完成,包括页面上的图片资源,JS 和 CSS 文件的加载,而且更头疼的是,如果页面上有一些墙外资源,比如来自 Google 或 Facebook 等站点的链接,如果不使用境外代理,浏览器要一直等到这些资源连接超时才算页面加载完成,而这些资源对我们的爬虫没有任何用处。
我们能不能让 Selenium 过滤掉那些我们不需要的请求呢?
Yi Zeng 在他的一篇博客 Exclude Selenium WebDriver traffic from Google Analytics 上总结了很多种方法来过滤 Google Analytics 的请求,虽然他的博客是专门针对 Google Analytics 的请求,但其中有很多思路还是很值得我们借鉴的。其中有下面的几种解决方案:
通过修改 hosts 文件,将 google.com、facebook.com 等重定向到本地,这种方法需要修改系统文件,不方便程序的部署,而且不能动态的添加要过滤的请求;
禁用浏览器的 JavaScript 功能,譬如 Chrome 支持参数 --disable-javascript 来禁用 JavaScript,但这种方法有很大的局限性,图片和 CSS 资源还是没有过滤掉,而且页面上少了 JavaScript,可能站点的很多功能无法使用了;
使用浏览器插件,Yi Zeng 的博客中只提到了 Google-Analytics-Opt-out-Add-on 插件用于禁用 Google Analytics,实际上我们很容易想到 AdBlock 插件,这个插件用来过滤页面上的一些广告,这和我们想要的效果有些类似。我们可以自己写一个插件,拦截不需要的请求,相信通过上一节的介绍,也可以做出来。
使用代理服务器 BrowserMob Proxy,通过代理服务器来拦截不需要的请求,除了 BrowserMob Proxy,还有很多代理软件也具有拦截请求的功能,譬如 Fiddler 的 AutoResponder 或者 通过 whistle 设置 Rules 都可以拦截或修改请求;
这里虽然方法有很多,但我只推荐最后一种:使用代理服务器 BrowserMob Proxy,BrowserMob Proxy 简称 BMP,可以这么说,BMP 绝对是为 Selenium 为生的,Selenium + BMP 的完美搭配,可以实现很多你绝对想象不出来的功能。
我之所以推荐 BMP,是由于 BMP 的理念非常巧妙,和传统的代理服务器不一样,它并不是一个简单的代理,而是一个 RESTful 的代理服务,通过 BMP 提供的一套 RESTful 接口,你可以创建或移除代理,设置黑名单或白名单,设置过滤器规则等等,可以说它是一个可编程式的代理服务器。BMP 是使用 Java 语言编写的,它前后经历了两个大版本的迭代,其核心也是从最初的 Jetty 演变为 LittleProxy,使得它更小巧和稳定,你可以从 这里下载 BMP 的可执行文件,在 Windows 系统上,我们直接双击执行 bin 目录下的 browsermob-proxy.bat 文件。
BMP 启动后,默认在 8080 端口创建代理服务,此时 BMP 还不是一个代理服务器,需要你先创建一个代理:
curl -X POST http://localhost:8080/proxy
向 /proxy 接口发送 POST 请求,可以创建一个代理服务器。此时,我们在浏览器访问 http://localhost:8080/proxy 这个地址,可以看到我们已经有了一个代理服务器,端口号为 8081,现在我们就可以使用 127.0.0.1:8081 这个代理了。
接下来我们要把 Google 的请求拦截掉,BMP 提供了一个 /proxy/[port]/blacklist 接口可以使用,如下:
curl -X PUT -d 'regex=.*google.*&status=404' http://localhost:8080/proxy/8081/blacklist
这样所有匹配到 .*google.* 正则的 url,都将直接返回 404 Not Found。
知道了 BMP 怎么用,再接下来,就是编写代码了。当然我们可以自己写代码来调用 BMP 提供的 RESTful 接口,不过俗话说得好,前人栽树,后人乘凉,早就有人将 BMP 的接口封装好给我们直接使用,譬如 browsermob-proxy-py 是 Python 的实现,我们就来试试它。
|
from selenium import webdriver
from browsermobproxy import Server
server = Server("D:/browsermob-proxy-2.1.4/bin/browsermob-proxy")
server.start()
proxy = server.create_proxy()
proxy.blacklist(".*google.*", 404)
proxy.blacklist(".*yahoo.*", 404)
proxy.blacklist(".*facebook.*", 404)
proxy.blacklist(".*twitter.*", 404)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--proxy-server={0}".format(proxy.proxy))
browser = webdriver.Chrome(
executable_path="./drivers/chromedriver.exe",
chrome_options = chrome_options
)
browser.get('http://www.flypeach.com/pc/hk')
server.stop()
browser.quit()
|
关键代码在前面几句,首先创建代理,再通过 proxy.blacklist() 将 google、yahoo、facebook、twitter 的资源拦截掉。后面的代码和前一节的代理设置完全一样。执行程序,体会一下,现在这个页面的打开速度快了多少?
BMP 不仅可以拦截请求,也可以修改请求,这对爬虫来说可能意义不大,但在自动化测试时,可以通过它伪造测试数据还是很有意义的。它提供了两个接口
|
/proxy/[port]/filter/request 和 /proxy/[port]/filter/response 用于修改 HTTP 的请求和响应,具体的用法可以参考 官网的文档,此处略过。
proxy.request_interceptor(
'''
request.headers().remove('User-Agent');
request.headers().add('User-Agent', 'My-Custom-User-Agent-String 1.0');
'''
)
proxy.response_interceptor(
'''
if (messageInfo.getOriginalUrl().contains("remote/searchFlights")) {
contents.setTextContents('Hello World');
}
'''
)
|
四、Selenium 如何爬取 Ajax 请求?
到这里,问题变得越来越有意思了。而且我们发现,用 Selenium 做爬虫,中途确实会遇到各种各样的问题,但随着问题的发现到解决,我们花在 Selenium 上面的时间越来越少了,更多的是在研究其他的东西,如浏览器的特性,浏览器插件的编写,可编程式的代理服务器,以此来辅助 Selenium 做的更好。
还记得前面提到的一个问题吗?如果要爬取的内容在 Ajax 请求的响应中,而在页面上并没有体现,这种情况该如何爬取呢?我们可以直接爬 Ajax 请求吗?事实上,我们很难做到,但不是做不到。
通过上一节对 BMP 的介绍,我们了解到 BMP 可以拦截并修改请求的报文,我们可以进一步猜想,既然它可以修改报文,那肯定也可以拿到报文,只是这个报文我们的程序该如何得到?上一节我们提到了两个接口 /proxy/[port]/filter/request 和 /proxy/[port]/filter/response,它们可以接受一段 JS 代码来修改 HTTP 的请求和响应,其中我们可以通过 contents.getTextContents() 来访问响应的报文,只是这段代码运行在远程服务器上,和我们的代码在两个完全不同的世界里,如何把它传给我们呢?而且,这段 JS 代码的限制非常严格,我们想通过这个地方拿到这个报文几乎是不可能的。
但,路总是有的。
我们回过头来看 BMP 的文档,发现 BMP 提供了两种模式供我们使用:独立模式(Standalone)和 嵌入模式(Embedded Mode)。独立模式就是像上面那样,BMP 作为一个独立的应用服务,我们的程序通过 RESTful 接口与其交互。而嵌入模式则不需要下载 BMP 可执行文件,直接通过包的形式引入到我们的程序中来。可惜的是,嵌入模式只支持 Java 语言,但这也聊胜于无,于是我使用 Java 写了个测试程序尝试了一把。
首先引入 browsermob-core 包,
<dependency>
<groupId>net.lightbody.bmp</groupId>
<artifactId>browsermob-core</artifactId>
<version>2.1.5</version>
</dependency>
然后参考官网文档写下下面的代码(完整代码见 这里),这里就可以看到嵌入模式的好处了,用于 BMP 拦截处理的代码和我们自己的代码处于同一个环境下,而且 Java 语言具有闭包的特性,我们可以很简单的取到 Ajax 请求的响应报文:
|
BrowserMobProxyproxyServer=newBrowserMobProxyServer();
proxyServer.start(0);
proxyServer.addRequestFilter((request,contents,messageInfo)->{
System.out.println("请求开始:"+messageInfo.getOriginalUrl());
returnnull;
});
StringajaxContent=null;
proxyServer.addResponseFilter((response,contents,messageInfo)->{
System.out.println("请求结束:"+messageInfo.getOriginalUrl());
if(messageInfo.getOriginalUrl().contains("ajax")){
ajaxContent=contents.getTextContents();
}
});
|
如果你是个 .Net guy,可以使用 Fiddler 提供的 FiddlerCore,FiddlerCore 就相当于 BMP 的嵌入模式,和这里的方法类似。这里有一篇很好的文章讲解了如何使用 .Net 和 FiddlerCore 拦截请求。
既然在 Java 环境下解决了这个问题,那么 Python 应该也没问题,但是 BMP 的嵌入模式并不支持 Python 怎么办呢?于是我一直在寻找一款基于 Python 的能替代 BMP 的工具,可惜一直不如愿,未能找到满意的。到最后,我几乎要下结论:Python + Selenium 很难实现 Ajax 请求的爬取。
天无绝人之路,直到我遇到了 har。
有一天我静下心来把 BMP 的文档翻来覆去看了好几遍,之前我看文档的习惯都是用时再查,但这次把 BMP 的文档从头到尾看了几遍,也是希望能从中寻找点蛛丝马迹。而事实上,还真被我发现了点什么。因为 Python 只能通过 RESTful 接口与 BMP 交互,那么每一个接口我都不能放过,有一个接口引起了我的注意:/proxy/[port]/har。
这个接口虽然之前也扫过几眼,但当时并不知道这个 har 是什么意思,所以都是一掠而过。但那天心血来潮,特意去查了一下 har 的资料,才发现这是一种特殊的 JSON 格式的归档文件。HAR 全称 HTTP Archive Format,通常用于记录浏览器访问网站的所有交互请求,绝大多数浏览器和 Web 代理都支持这种格式的归档文件,用于分析 HTTP 请求,因为广泛的应用,W3C 甚至还提出 HAR 的规范,目前还在草稿阶段。
/proxy/[port]/har 接口用于创建一份新的 har 文件,Selenium 启动浏览器后所有的请求都将被记录到这份 har 文件中,然后通过 GET 请求,可以获取到这份 har 文件的内容(JSON 格式)。har 文件的内容类似于下面这样:
{
"log": {
"version" : "1.2",
"creator" : {},
"browser" : {},
"pages": [],
"entries": [],
"comment": ""
}
}
其中 entries 数组包含了所有 HTTP 请求的列表,默认情况下 BMP 创建的 har 文件并不包含请求的响应内容,我们可以通过 captureContent 参数来让 BMP 记录响应内容:
curl -X PUT -d 'captureContent=true' http://localhost:8080/proxy/8081/har
万事俱备,只欠东风。我们开始写代码,首先通过 proxy.new_har() 创建一份 har 文件:
proxy.new_har(options={
'captureContent': True
})
然后启动浏览器,访问要爬取的页面,等待页面加载结束,这时我们就可以通过 proxy.har 来访问 har 文件中的请求报文了(完整代码在 这里):
for entry in proxy.har['log']['entries']:
if 'remote/searchFlights' in entry['request']['url']:
result = json.loads(entry['response']['content']['text'])
for key, item in result['data']['flightInfo'].items():
print(key)
总结
这篇博客总结了 Selenium 的一些基础语法,并尝试使用 Python + Selenium 开发浏览器爬虫。本文还分享了我在实际开发过程中遇到的几个常见问题,并提供了一种或多种解决方案,包括代理的使用,拦截浏览器请求,爬取 Ajax 请求等等。实践出真知,通过一系列问题的提出,到研究,到解决,我学习到了非常多的东西。不仅意识到知识广度的重要性,而且更重要的是知识的聚合和熔炼。我一直认为知识的广度比深度更重要,只有你懂的越多,你才有可能接触更多的东西,你的思路才更放得开;深度固然也重要,但往往会让人局限于自己的漩涡之中。但知识的广度不是天马行空,需要不断的总结提炼,融会贯通,形成自己的知识体系,这样才不至于被繁多的知识点所困扰。
另外,我也意识到阅读项目文档的重要性,心平气和的将项目文档从头到尾阅读一遍,遇到不懂的,就去查找资料,而不是只挑自己知道或感兴趣的,这样会得到意想不到的收获。
本文所有源码都在我的 GitHub 上,你可以从 这里 查看完整源码。本人能力有限,文中如有错误,欢迎斧正,望不吝赐教。如有好的想法和问题,也欢迎留言评论。