字典又可以叫做符号表,关联数组,以及映射(map),是一种键值对的抽象数据结构。
在字典中,每一个key都是独一无二的。Redis属于KV类型的NOSQL,很大一部分原因就是它的KV设计太符合缓存这一概念了。
例如之前的 set msg "111",这种操作,虽然"111"最后是使用SDS进行存储的,但是msg和"111"依然是采用字典进行了保存。
字典的底层是基于哈希表进行的实现,当一个哈希键包含的键值过多,又同时键值对中的元素都是较长字符串的时候,Redis就会使用到字典作为哈希键的底层实现。
在Redis中的哈希表的设计,这些中间件的设计为了极致的运行,一般都会使用一些哨兵的思想,包括上面的双链表。一个很大的特点我个人感觉就是除了核心CPU外剩余的硬件资源都是过剩的,所以哨兵是一个很好的平衡手段。
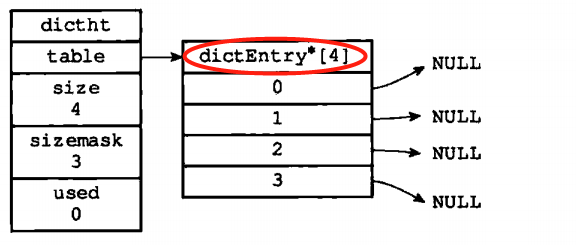
一个数组表示哈希表的最底层,size哨兵保存了哈希表的长度,还有一个大小等于size-1的哈希表掩码,以及一个used变量保存hash表中已经有的元素的个数。数组内使用一个实体类来进行键值对的保存。
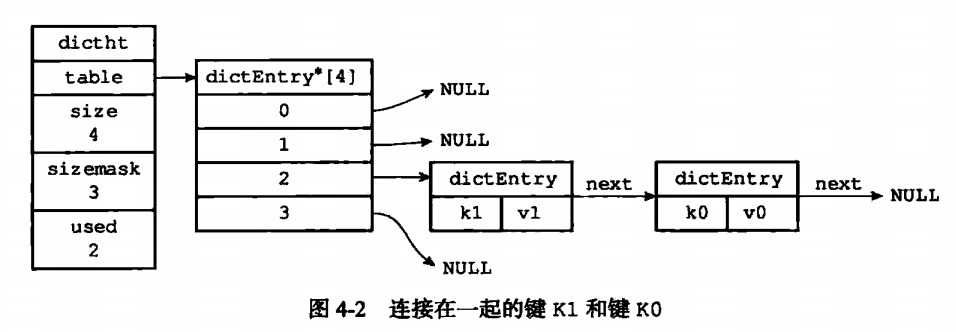
这个dictEntry中的设计就是一个正常三个局部变量,Key,Value以及下一个节点的地址。这个设计有点链表的风采。其实不是,这是为了让多个key有相同哈希值的时候能连接在一起,防止冲突。
这设计和Java1.8之前的HashMap基本逻辑上一样的。
上面说的就是redis中哈希表的设计方式。在redis中字典就是由这个哈希表再进行封装产生的。
字典(dict),三个变量,dictType用来判断不同的类型的特定函数,dictType保存了一些用于操作特定类型键值对的函数。redis为这些特定类型提供了不同的可选值。
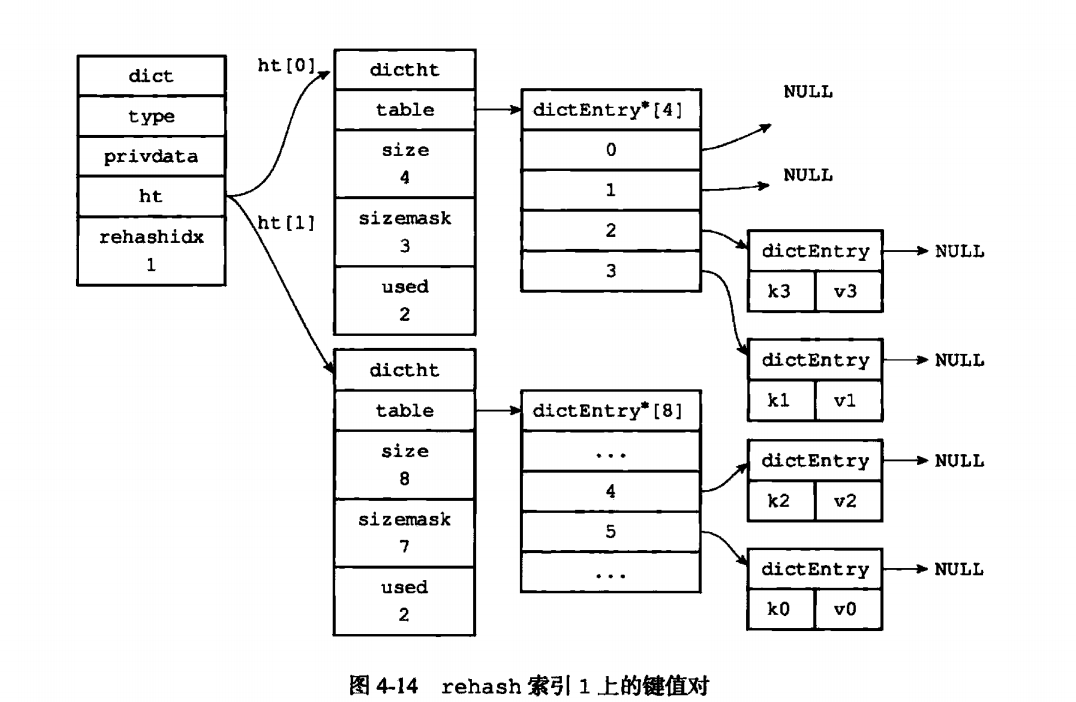
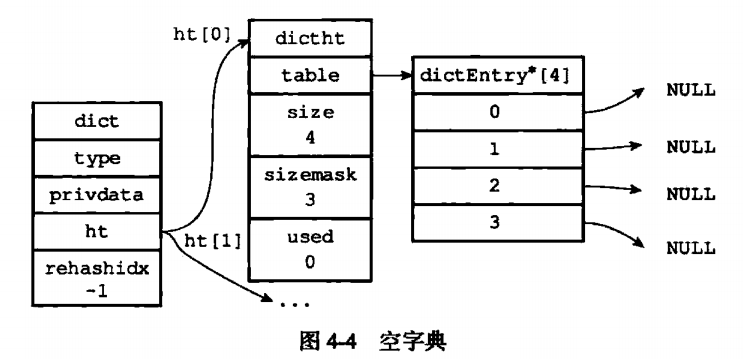
privdata用来保存私有数据,最后就是上面说的哈希表(dictht),在字典里面,哈希表的默认大小是2个。每一个都是哈希表,要两个的原因是为了rehash。
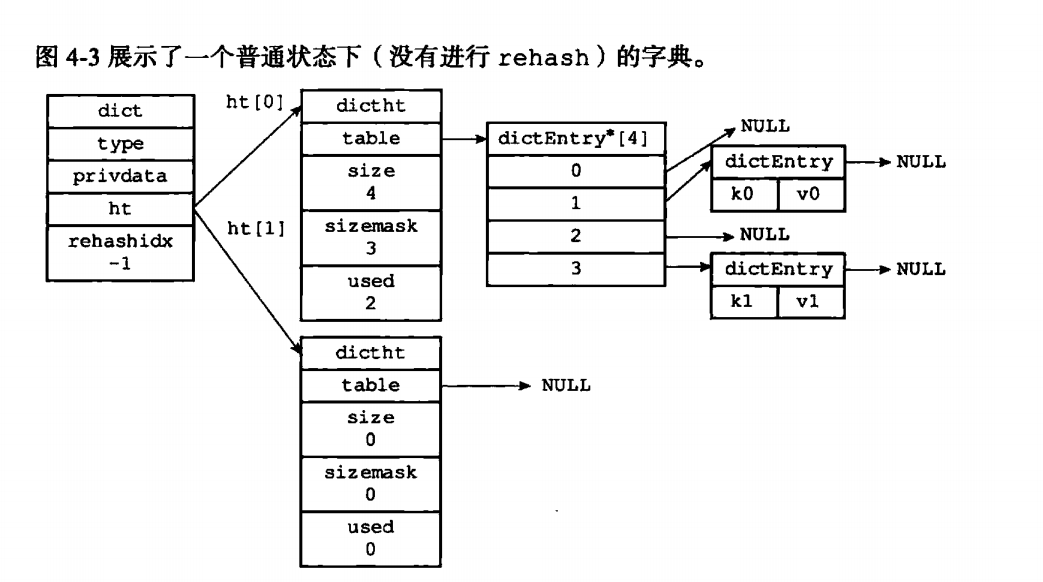
什么是rehash呢, 指的是重新计算键的哈希值和索引值,然后将键值对放置到 ht[1] 哈希表的指定位置上。那么为什么会出现冲突呢?下面书里就介绍了为什么会产生冲突的原因,以及如何思考hash的算法。
当一个新的键值要加入字典里面的时候,先通过键值计算出哈希值和索引值,然后根据索引值将新键值对里面的哈希表节点放到哈西数组的制定索引数组上面。
具体的流程hash = dict ->type ->hashFunction(key),当然根据不同的sizemask会计算出不同的索引值,index = hash&dict ->ht[x].sizemask;
如果把一个msg和"111"放入字典,先对msg进行哈希计算,如果算出的结果是8,index = hash&dict ->ht[x].sizemask=8&dict=8&3=0;
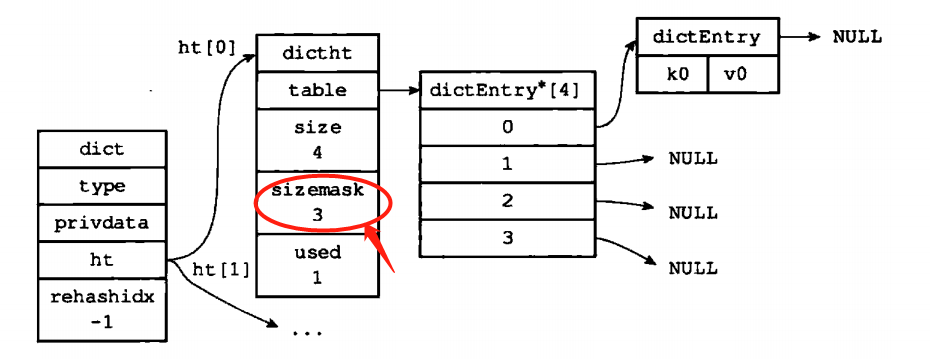
所以最后放入的就是0这个位置,至于Hash算法的选择,redis使用的是MurmurHash2算法来进行key值的hash计算。
由于Hash算法无法保证不产生冲突的情况所以,当key相同的时候,在dictht的位置也有很大可能相同,于是就需要使用到dictEntry里面的链式结构来解决掉冲突
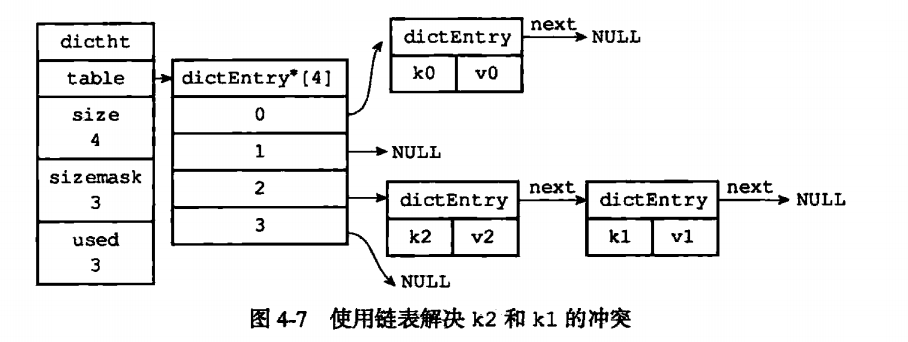
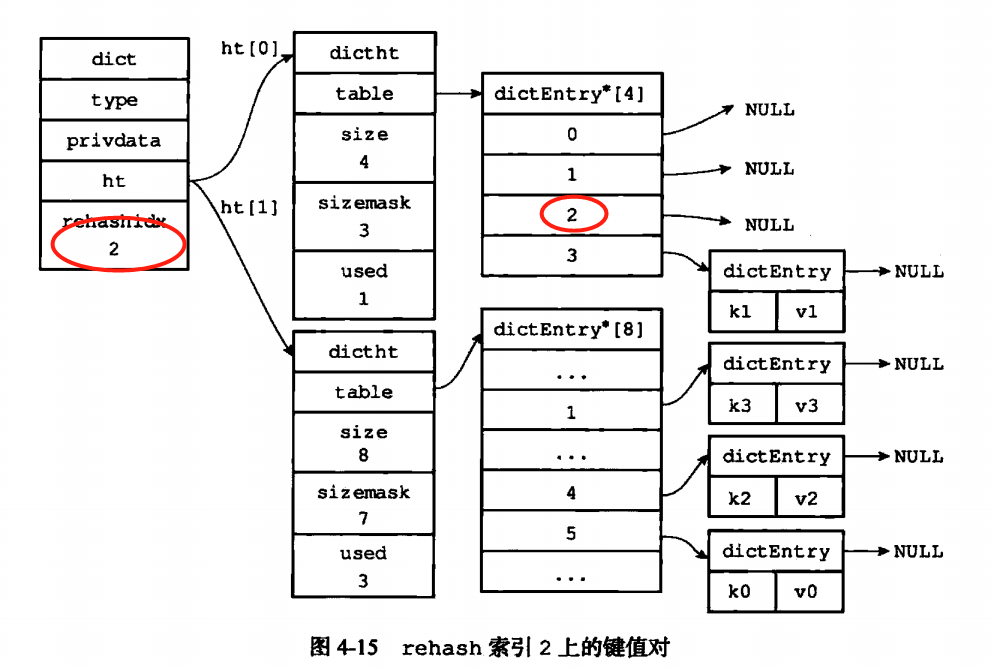
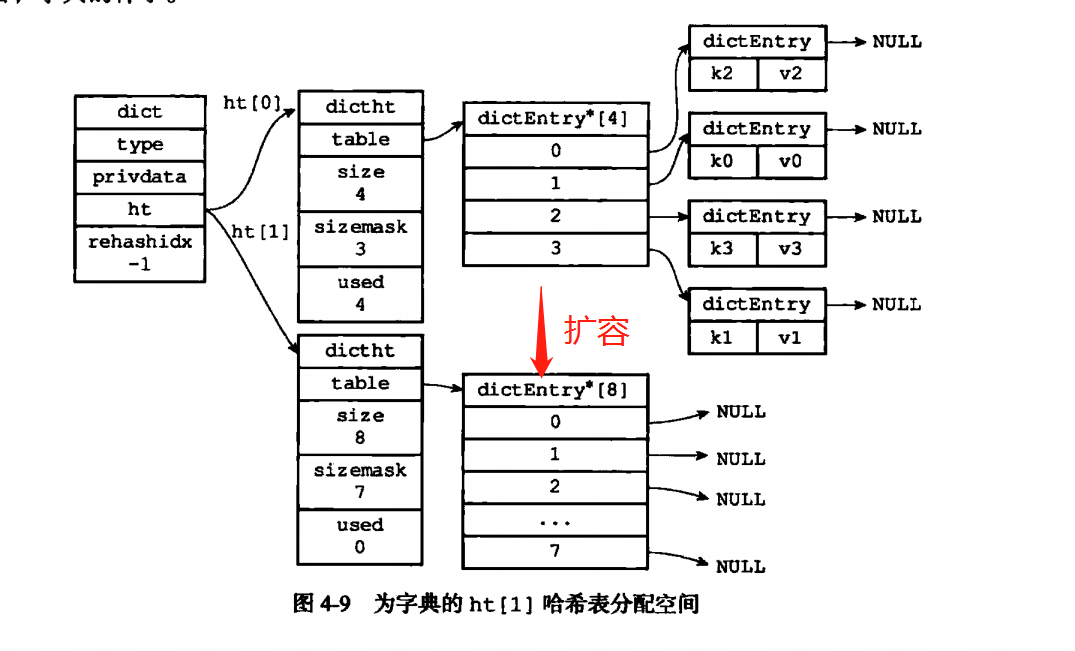
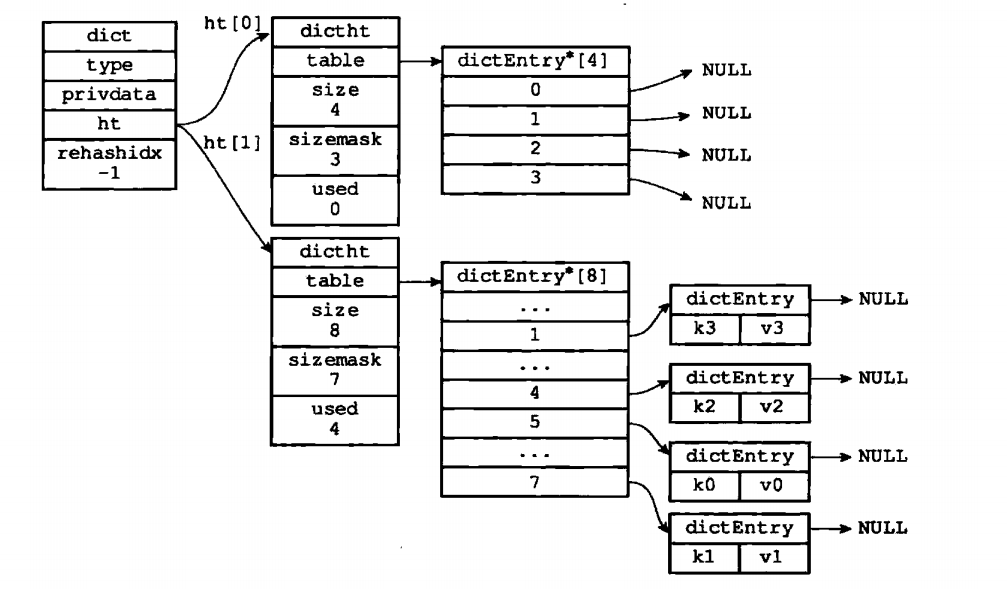
同时hash表有一个问题就是,hash会越来越多,当hash键过多的时候,就需要进行rehash,这时候ht[1]就有用处了,首先判断是扩容还是缩容,扩容则是*2,缩容则是/2.然后再对h[1]上的所有hash进行rehash计算,最后再把ht[1]和ht[0]的地址互换。同时清零老的hash表。
 。
。
当然进行rehash肯定是有条件的,例如服务器正在正常的执行某个操控肯定不能突然进行hash,可以通过前置条件或者触发条件来进行辅助。
一般是以下两个条件:1.服务器没有执行BGSAVE以及BGREWRITEAOF并且hash的负载因子大于等于1。2.服务器正在执行BGSAVE以及BGREWRITEAOF但hash的负载因子大于等于5。
当负载因子小于0.1的时候会自动进行缩容,为什么是以上两个指令来作为判断条件呢?因为上述两个在执行的时候,会创建子进程进行写时复制,这个操作也是一个扩容的操作,如果再进行扩容就会使用额外的内存,这让本不富裕的家庭雪上加霜。
当然在redis中,使用的是渐进式rehash,如果一下子将10000W的hash值进行rehash,cpu都要超频了。

这思想我给满分,哨兵,分治,线程变量都思想都放入了。在变化的时候rehashindex是用于来标记位置的。rehash时候是根据数组的偏移量来一个个顺序进行的,是顺序的。