LinkedHashMap看名字其实就知道了是链表和Map的集合体。
这个东西在1.4的时候被提出,然后一直沿用至今,说实话在目前的开发中我还是没有遇到过这个的使用场景。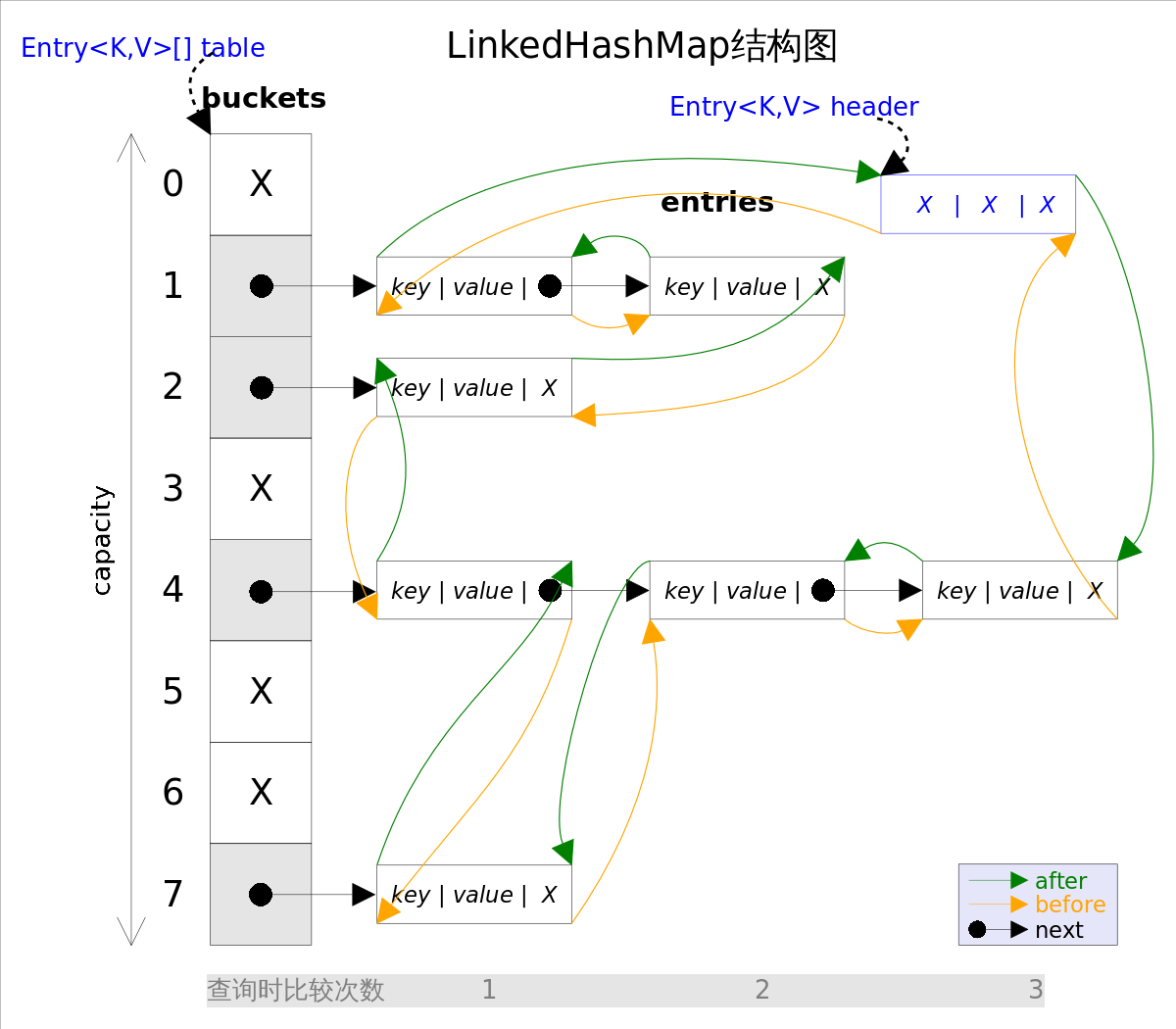

在LinkedHashMap中有两种便利顺序:
第一张图为LinkedHashMap整体结构图,第二张图专门把循环双向链表抽取出来,直观一点,注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。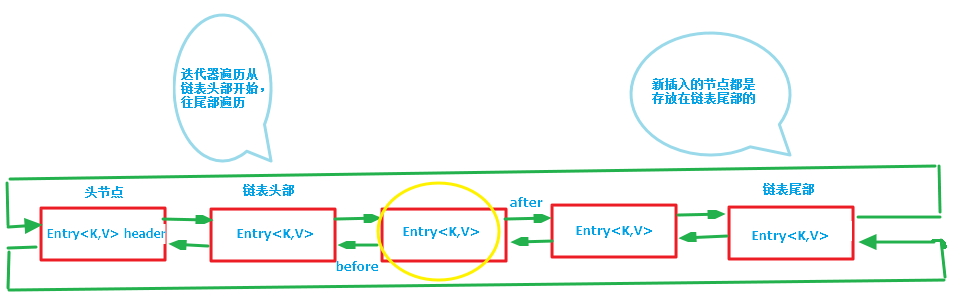
看得出他的结果和HashMap很像,它继承自HashMap,所以CRUD方法就不说了。
通过看它的JavaDoc可以得知它的几个特点:
- 底层是散列表和双向链表
- 允许为null,不同步
- 插入的顺序是有序的(底层链表致使有序)
- 装载因子和初始容量对LinkedHashMap影响是很大的
它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。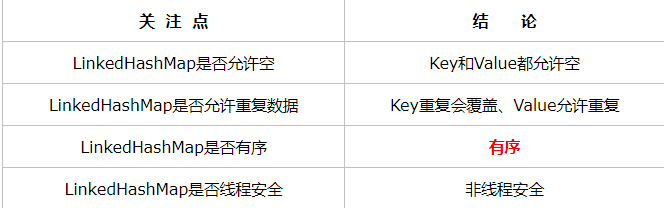
LinkedHashMap一共5个构造方法
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } // 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序 public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } // 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序 public LinkedHashMap() { super(); accessOrder = false; } // 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值 public LinkedHashMap(Map<? extends K, ? extends V> m) { super(m); accessOrder = false; } // 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; } //从构造方法中可以看出,默认都采用插入顺序来维持取出键值对的次序。 //所有构造方法都是通过调用父类的构造方法来创建对象的。
例子代码:
public static void main(String[] args) { LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<String, String>(); linkedHashMap.put("111", "111"); linkedHashMap.put("222", "222"); } —————————————————————————————————————————————————————————————————————————————————————— //首先是第3行~第4行,new一个LinkedHashMap出来,看一下做了什么: //通过源代码可以看出,在LinkedHashMap的构造方法中, //实际调用了父类HashMap的相关构造方法来构造一个底层存放的table数组。 public LinkedHashMap() { super(); accessOrder = false; } public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR); table = new Entry[DEFAULT_INITIAL_CAPACITY]; init(); } //我们已经知道LinkedHashMap的Entry元素继承HashMap的Entry,提供了双向链表的功能。在上述HashMap的构造器中, //最后会调用init()方法,进行相关的初始化,这个方法在HashMap的实现中并无意义,只是提供给子类实现相关的初始化调用。 //LinkedHashMap重写了init()方法,在调用父类的构造方法完成构造后,进一步实现了对其元素Entry的初始化操作。 void init() { header = new Entry<K,V>(-1, null, null, null); header.before = header.after = header; }
这里出现了第一个多态:init()方法。尽管init()方法定义在HashMap中,但是由于:
1、LinkedHashMap重写了init方法
2、实例化出来的是LinkedHashMap
因此实际调用的init方法是LinkedHashMap重写的init方法。假设header的地址是0x00000000,那么初始化完毕,实际上是这样的:
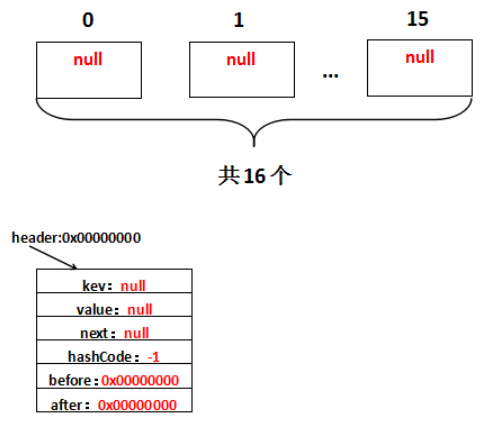
注意这个header,hash值为-1,其他都为null,也就是说这个header不放在数组中,就是用来指示开始元素和标志结束元素的。header的目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。
当放入之后就会变成这样
在查询的时候会发现一个有意思的点:最常用的将其放在链表的最后,不常用的放在链表的最前
这个访问顺序在LinkedHashMap如果不重写用处并不大,它是用来给别的实现进行扩展的
- 因为最常被使用的元素再遍历的时候却放在了最后边,在LinkedHashMap中我也没找到对应的方法来进行调用~
- 一个removeEldestEntry(Map.Entry<K,V> eldest)方法,重写它可以删除最久未被使用的元素!!
- 有一个是afterNodeInsertion(boolean evict)方法,新增时判断是否需要删除最久未被使用的元素!!
在LinkedHashMap中有两种便利顺序:
- 访问顺序(access-ordered)(和InnoDB中一样使用LRU算法)
- 插入顺序(insertion-ordered)