一、协程
1.定义:
单线程实现并发,可以再应用程序当中控制多个任务的切换+保存状态。
优点:在应用程序级别的速度要远远高于操作系统的切换
缺点:多个任务一旦有一个任务阻塞住了,没有及时切换,整个线程都将阻塞在原地,该线程内的其他任务都不能继续执行了。
所以,在引入协程之后,就需要检测单线程下所有的IO行为,必须实现一旦遇到IO就立即切换,少一个都不行,因为一旦遇到一个任务阻塞住了,其它的任务都将阻塞住,及时其余的线程都是可以计算的,它们也是无法继续执行了。
2.协程的目的
程序想要能够在单线程下实现并发,并发即指的是多个任务看起来是同时执行的。
协程的并发=切换+保存运行暂停时的状态
二、IO模型
分类:阻塞IO ( blocking IO)
非阻塞IO( nonblocking IO)
IO多路复用( IO multiplexing)
异步IO( asynchronous IO)
IO发生时涉及的对象和步骤:
对于一个network IO 即网络 IO (这里我们以read举例),它会涉及到两个系统对象,一个是调用这个 IO 的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段。
#1 等待数据准备 (Waiting for the data to be ready) #2 将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
事先准备:
1、输入操作:read、readv、recv、recvfrom、recvmsg共5个函数,表示一个通用的读文件设备的接口。如果有阻塞状态,则会经历 wait data 和 copy data 两个阶段,如果事先设置成非阻塞状态则在 wait data 阶段会等不到 data 时抛出异常。
2、输出操作:write、writev、send、sendto、sendmsg共5个函数,表示一个通用的写文件,然后向客户端发送数据设备的接口,在发送数据时,若缓冲区满了会阻塞在原地,如果设置为非阻塞,则会抛出异常。
3、接收外来链接:accept,与输入操作类似
4、发起外出链接:connect,与输出操作类似
(1)阻塞IO(blocking IO)
在 linux 中,默认情况下所有的 socket 都是 blocking=True 的状态。
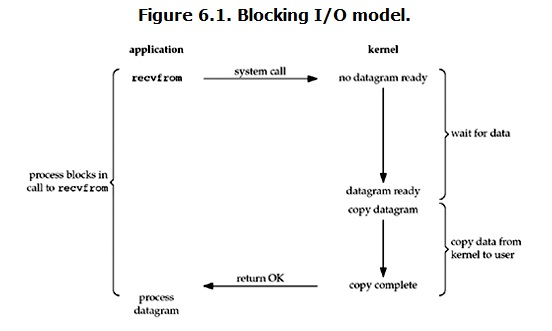
流程:
客户端应用程序向本地操作系统发起 recvfrom 操作后,在网络 IO 中,服务端的 kernel 中一般是不会立即就有数据返回;此时服务端这边就会处于 wait for data 状态,而客户端这边的进程也因为不能及时收到数据而处于阻塞的状态,当服务端收到数据之后,服务端的 kernel 还会经历 copy data 阶段,然后再向服务端发送出数据;因为客户端再发送接收数据的过程中一直处于接收的状态,这个过程就称为阻塞 IO。
特点:在 IO 执行的两个阶段(等待接收 data 和 copy data )都被 block 了。
(2)非阻塞 IO(non-blocking IO)
Linux下,可以通过设置socket使其变为non-blocking。
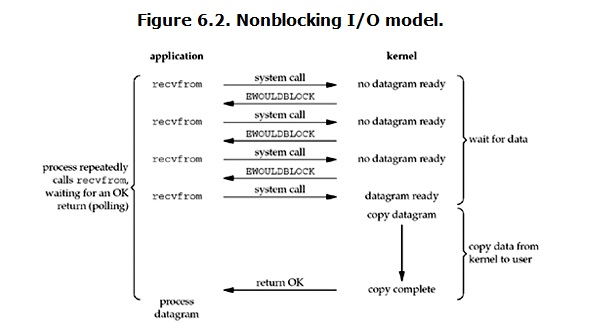
流程:
客户端应用程序的操作系统向服务端的操作系统发送一条 recvfrom 请求,若服务端的 kenel 中没有数据,则会立即返回一个信息说明还未收到数据,之后客户端应用程序会不间断地发出请求接收数据,此时基本上也就是陷入一个死循环了,这个死循环就是服务端的 wait for data 阶段;当某一次服务端收到数据之后,会立即在kenel 中 copy data ,然后将 data 返回给客户端。
缺陷:在客户端不断向服务端发送请求数据时,会大量的占用了 CPU 资源,造成极大的浪费。
(3)多路复用 IO(IO multiplexing)
别名:事件驱动 IO(event driven IO)
原理:select/epoll 这个function 会不间断的向服务端操作系统的 socket 发起咨询是否收到数据,知道某个 socket 收到数据之后,才会向服务端的进程发出一条仅仅是说明服务端已经收到数据的信息。
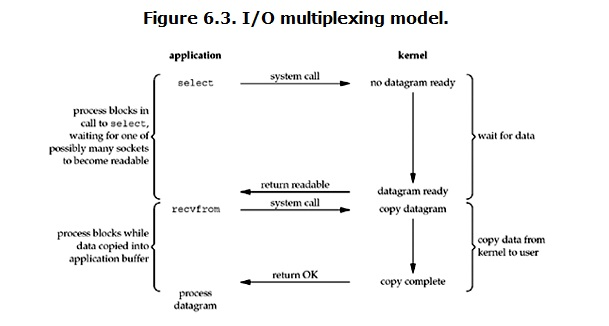
流程:
客户端将自己向服务端发起请求的这个要求包给了 select ,然后由 select 代替客户端应用程序向服务端操作系统发起请求数据,客户端的应用程序就可以自己跟自己继续玩了,知道服务端的操作系统通知 select 说已收到数据时,又由 select 向客户端发送通知,让客户端玩耍够了,自己去向服务端发起请求下载数据,服务端的 kenel 则会 copy data 之后将 data 返回给用户进程。
在这个流程中,客户端虽然在 wait for data 阶段是没有阻塞的,但是它会在服务端操作系统 copy data 时,经历了一小段的阻塞阶段。
优点:
相对于前面两个模型来讲,select/epoll 可以同时管理很多个的 socket ,解决了客户端 socket 的 CPU 占用率过高的问题。
缺点:
select 可管理的 socket 终归时有限的,若在数量过大的情况,也是会影响服务端的运行效率的。
待更。。。