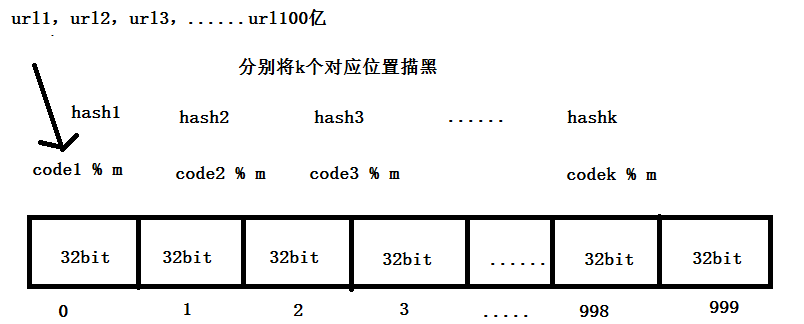
查黑名单(大数据 100亿数据)
不理想的是:
1.使用哈希表来查(要使用非常大的空间)
2.改进:使用哈希分流,然后将使用多个计算机处理(浪费机器,代价高)
理想的是使用布隆过滤器(一种集合,但是有失误率,不属于黑名单的url可能会被认为在黑名单中,误报):
使用的是基本数据类型的数组
然后使用数组中的bit位
如 int 型 数据 4个字节,32bit,int [] array = new int[1000];可以表示32*1000个位置

例:将某个位置描黑index:
1.这个bit位来自哪个整数:intIndex = index / 32
2.这个位置是这个整数的具体哪个bit:bitIndex = index % 32
3.描黑操作(找到相应的bit位):array[intIndex] = (array[intIndex] | (1 << bitIndex));
也可以用long类型的(64bit),
long [] array = new long[1000] 1000*64 个位置
long[][] array = new long[1000][1000] 1000*1000*64 个位置
每个url经过k个哈希函数(相互独立的),对应相应位置上描黑,所有黑名单中每个url都描黑之后,整个布隆过滤器的数组相应位置就被描黑了
当检查url时,计算k个哈希函数的位置,当所有的位置都是黑的的情况下,就认为在过滤器中,否则就不在
样本量 n:100亿, 失误率 p:0.0001万分之一
1.需要开的空间大小m 大小为bit:
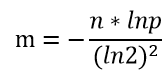 m = 1,879,591,836,735 bit
m = 1,879,591,836,735 bit
其中n 为样本量,p为预期失误率
实际的字节 m / 8 1,879,591,836,735 bit / 8 = 234948979591字节 =23.3G(向上取整) 内存
2.哈希函数的个数k:
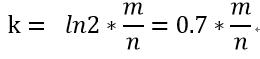 k = 13 (向上取整)
k = 13 (向上取整)
注:m和k向上取整
3.根据m和k向上取整之后,真实的失误率:
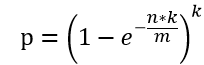 p=6/十万
p=6/十万