基于递归和注意力机制的神经模型解释
Interpreting Recurrent and Attention-Based Neural Models: a Case Study on Natural Language Inference
Abstract
在本文中,我们通过一个NLI神经模型的案例研究来解释这种基于深度学习的模型。我们通过可视化attention的显著性和LSTM门控信号来解释NLI模型的中间层。我们提供了几个例子,在这些例子中,我们的方法能够揭示有趣的见解,并识别有助于模型决策的关键信息
Introduction
之前的工作主要是通过可视化文字或隐藏状态的表示完成的,以及分析它们在情感分析和词性标注等浅层任务中的重要性(通过显著性或删除)。与此相反,在具有挑战性的NLI任务中,我们着重于解释深层模型的中间层的门控和attention信号。解释深层模型的一个关键概念是显著性,它决定了对最终决策来说什么是关键的。到目前为止,显著性仅用于说明单词嵌入的影响。在本文中,我们将这一概念扩展到深度模型的中间层,以检查attention的显著性以及LSTM门控信号,以理解这些组件的行为及其对最终决策的影响。
我们有两个主要贡献。
- 引入新的策略来解释深层模型在其中间层的行为,具体来说,通过检查attention和门控信号的显著性。
- 对NLI任务的SOTA模型进行了广泛的分析,结果显示我们的方法揭示了传统的对于attention和单词显著性的检验方法所没有的有趣见解。
在本文中,我们的重点是NLI,这是一个基本的NLP任务,需要理解和推理。此外,SOTA NLI模型采用了复杂的神经结构,涉及到如attention和重复阅读这种关键机制,广泛应用于其他NLP任务的成功模型。因此,我们希望我们的方法对其他自然理解任务也有潜在的用处。
Task and Model
在NLI中,我们被给予两个句子,一个前提和一个假设,目标是决定逻辑关系(蕴涵,中立或矛盾)。本文分析ESIM,ESIM首先使用LSTM独立阅读句子,然后用attention层将句子进行对比。接着又是一层LSTM阅读并产生最终的表示。最后将表示进行比较再做出预测。ESIM-50是50维,ESIM-300是300维。
Visualization of Attention and Gating
在这项工作中,我们主要感兴趣的是NLI模型的内部工作。特别地,我们关注LSTM门信号和attention,以及它们如何对模型的决策做出贡献。
Attention
NLI之前的几项工作试图将注意层可视化,以提供对其模型的一些理解。这种可视化生成了一个热图,表示前提和假设的隐藏状态之间的相似性。不幸的是,无论决定如何(蕴涵、中立或矛盾),similarities往往是相同的。
例子:
前提:
“A kid is playing in the garden”
三种不同的假设:
h1: A kid is taking a nap in the garden (矛盾)
h2: A kid is having fun in the garden with her family (中立)
h3: A kid is having fun in the garden (蕴涵)
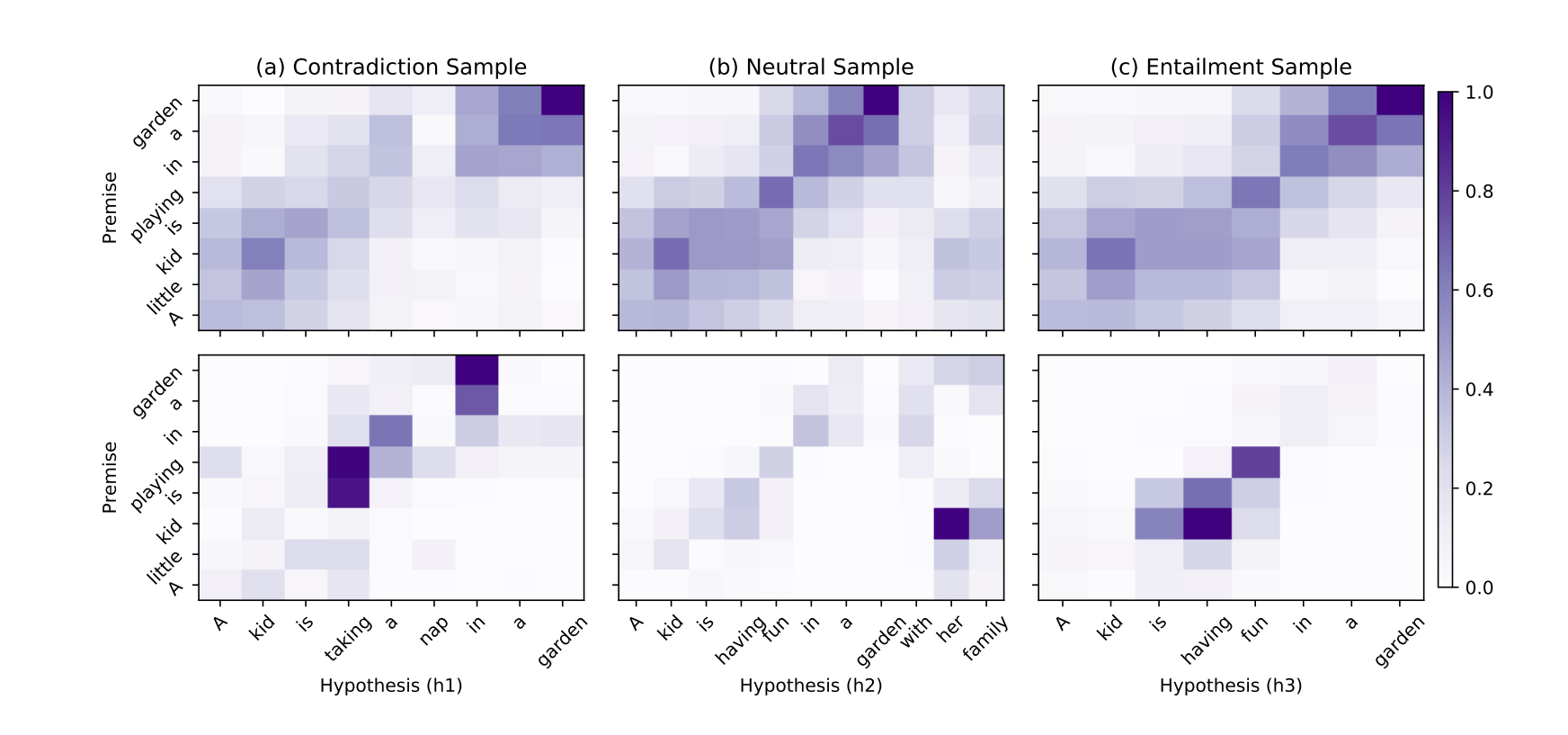
图1:标准化后的attention和attention saliency的可视化。每一列显示一个示例的可视化。上面的图表示attention可视化,下面的图表示attention saliency的可视化。预测标签显示在每一列的顶部。
图1的第一行显示了由ESIM-50产生的三种情况的标准化attention的可视化,它对所有这些情况都做出了正确的预测。从图中我们可以看到,这三种attention map是相当相似的,尽管他们的决定完全不同。关键的问题是,attention可视化只能让我们看到模型是如何将前提与假设结合起来的,但没有显示这种结合是如何影响决策的。这促使我们考虑attention saliency。
Attention Saliency
在NLP中,显著性被用来研究词汇对最终决策的重要性。具体地说,在给定一个前提-假设对和模型的决策\(y\)的情况下,我们将一对前提-假设隐含状态\(e_{ij}\)之间的相似性作为一个变量。决策\(S(y)\)是包括所有\(i,j\)的\(e_{ij}\)的函数。定义\(e_{ij}\)的显著性为\(\frac{\part S(y)}{ \part e_{i,j}}\)。
图1第二行为同一ESIM-50模型获得的三个样本的attention saliency图。有趣的是,不同示例的显著性明显不同,每个都突出对齐的不同部分。对于h1,我们看到“is playing”和“taking a nap”的对齐,以及“in a garden”的对齐对矛盾的决定具有最突出的贡献。对于h2来说,“kid”和“her family”的对齐似乎是最突出的决定。最后,在h3中,“is having fun”和“kid is playing”之间的一致性对决定影响最大。
从这个例子中,我们可以看到,通过检查attention saliency,我们可以有效地确定哪一部分的对齐对最终的预测做出最关键的贡献,而仅仅可视化attention本身揭示了很少的信息。
Comparing Models
用attention saliency比较两个不同的ESIM:ESIM-50和ESIM-300。
前提:A man ordered a book
假设1:John ordered a book from amazon
假设2:Mary ordered a book from amazon
ESIM-50未能捕捉到两个不同名字的性别联系,输出了中立。而ESIM-300正确地预测了第一种情况的包含性和第二种情况的矛盾性。
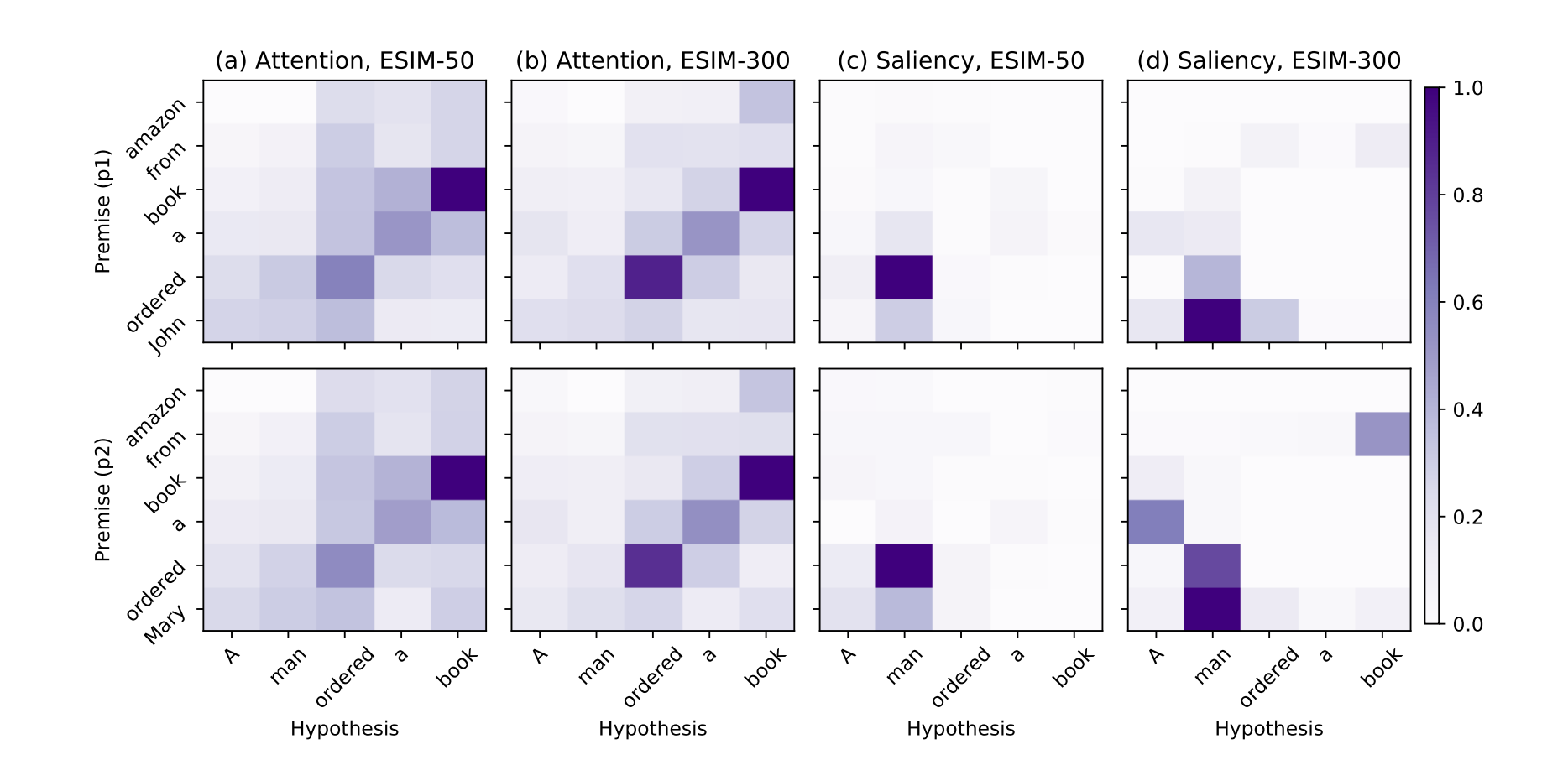
在图2的前两列(列a和b)中,我们分别可视化了两个例子对ESIM-50(左)和ESIM-300(右)的attention。虽然这两个模型做出了不同的预测,但它们的attention map在性质上是相似的。
图2中3-4列分别给出了ESIM-50和ESIM-300对两个样例的attention saliency。我们可以看到,在这两个例子中,ESIM-50主要关注“ordered”的对齐,而ESIM-300更多地关注“John”和“Mary”与“man”的对齐。有趣的是,对于基于attention map的两个关键单词对(“John”,“man”)和(“Mary”,“man”),与ESIM-50相比,ESIM-300似乎没有学习到显著不同的相似值。然而,显著性图显示,这两个模型使用这些值的方式非常不同,只有ESIM-300正确地关注它们。
LSTM Gating Signals
LSTM选通信号决定信息的流动。换句话说,它们表示LSTM如何读取单词序列,以及如何捕获和组合来自不同部分的信息。LSTM门控信号很少被分析,可能由于它们的高维性和复杂性。在这项工作中,我们考虑了门控信号和他们的显著性,这是对每个门控信号计算作为最终决定的分数的偏导数。
我们没有考虑门控信号的单个维度,而是将它们聚合以考虑它们的规范,既考虑信号,也考虑其显著性。注意,ESIM模型有两个LSTM层,第一个(输入)LSTM执行输入编码,第二个(推理)LSTM生成推理的表示。
在图3中,我们为正向输入(下三行)和推理(上三行)lstm的不同门(输入、忘记、输出)绘制归一化信号和显著性规范。这些结果是由第3.1节的三个例子的ESIM-50模型产生的,每列一个。
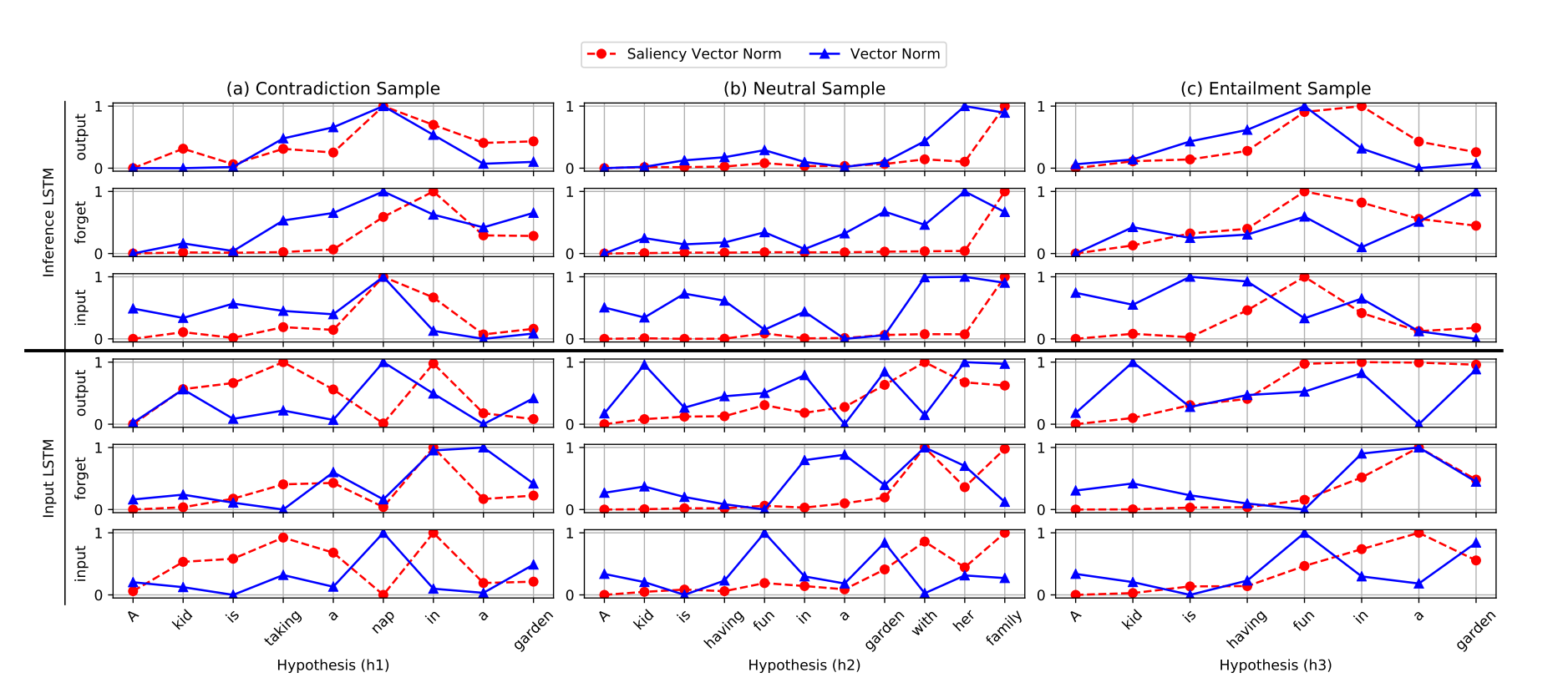
我们首先注意到,在同一个LSTM中,不同门之间的显著性趋于一致,这表明我们可以联合解释它们,以识别句子中对模型预测重要的部分。
显著性曲线显示了不同的例子之间的显著差异。例如,中性例子的显著性模式与其他两个例子有显著性差异,并且集中在句尾("with her family"),如果句子中没有这一部分,这种关系将会是“蕴含”。这个特定部分的焦点(由其强烈的显著性和强烈的门控信号所证明),呈现了从前提得不到的信息,解释了模型的中立决定。
比较输入LSTM和推理LSTM的行为,我们观察到有趣的焦点转移。特别是,我们发现推理LSTM倾向于在句子的关键部分看到更集中的显著性,而输入LSTM看到更广泛的显著性。例如,在矛盾的例子中,输入LSTM的“take”和“in”显著性都很高,而LSTM的推理主要集中在“nap”上,这是暗示矛盾的关键词。请注意,ESIM在输入层和推理LSTM层之间使用注意力来对齐/对比句子,因此推理LSTM更关注句子之间的关键差异是有道理的。在中立的例子中也可以观察到这一点。
值得注意的是,虽然总体趋势相似,但反向LSTM有时会聚焦在句子的不同部分,说明正向和倒向阅读对句子的理解是互补的。
Conclusion
我们为神经模型提出了新的可视化和解释策略,以理解它们如何和为什么工作。我们证明了所提出的策略在复杂任务上的有效性(NLI)。我们的策略能够提供以前解释技术无法实现的有趣见解。我们未来的工作将扩展到考虑其他的NLP任务和模型,并为进一步改进这些模型提供有用的见解。