学习日志-2021.09.24
学习进展(笔记):
多智能体博弈强化学习研究综述
-
强化学习主要解决的是序贯决策问题。(智能体与环境交互,根据环境的反馈做出决策,最终得到最优策略使得积累回报的期望最大)。单智能体向多智能体过度的难点。
- 维度爆炸(计算量指数级递增)。目前解决方法:①混合型训练机制;②基于伪计数的探索算法。
- 环境非平稳性(状态转移函数取决于联合动作)。目前解决方法:①采用AC框架,训练中可以获得其他智能体的信息和行动;②采用对手建模,模拟其他智能体的策略;③利用元学习更快适应非平稳性环境。
- 信度分配。目前解决方法:平均分配、差分回报分配、又是函数分配、基于情景记忆检索TVT算法。
-
多智能体博弈强化学习基本概念
-
马尔可夫决策(MDP)
- 五元组 (< S , A , P , R , gamma >)
- S:包含所有状态的有限集合
- A:包含智能体所有动作的有限集合
- P(转换函数): S × A × S -> [ 0 , 1 ]
- R(回报函数)
- (gamma) (折扣函数)∈ [ 0 , 1 ]
- 目标:找到期望值回报最大最优解策略
- 五元组 (< S , A , P , R , gamma >)
-
随机博弈(SG)
- 六元组< N , S , (A^i) , P , (R^i) , γ >
- N:为博弈玩家个数(为1时,MDP相同)
- (A^i):为第i个玩家的动作,(A^{-i}):为除第i个玩家外其他玩家的动作,(A = A^1 × A^2 × ... × A^n)。
- (R^i):为第i个回家的回报函数
- 六元组< N , S , (A^i) , P , (R^i) , γ >
-
部分可观察的随机博弈(POSG)
- 八元组< N , S , (A^i) , P , (R^i) , γ , (OB^i) , O >
- (OB^i):为第i个玩家的观测集,联合观测集为(OB = OB^1 × OB^2 × ... × OB^n);
- O:为S × A -> [ 0 , 1 ]的观测函数。
- 八元组< N , S , (A^i) , P , (R^i) , γ , (OB^i) , O >
-
纳什均衡
-
一组策略((σ^1_*,...,σ^n_*)),该策略是的每个玩家在其他玩家策略不变的情况下,该玩家的收益不会减少,即对 $ ∀s∈S,i=1,2,...,n $ ,都有:
[R^i(s,σ^1_*,...,σ^n_*)≥R^i(s,σ^1_*,...,σ^{i-1},σ^i,σ^{i+1},...,σ^n_*) ],其中(σ^i∈prod^{i},prod^{i})是玩家i所有可能的策略集合。
-
-
元博弈
- 。。。
-
-
标准博弈
-
共同利益博弈
-
团队博弈:每个智能体之需要维护自己的值函数,而且值函数只取决于当前的状态和动作,从而避免了考虑联合动作时的环境非平稳和维度爆炸问题。
-
最优解的关键:如何解决智能体之间的合作关系。

-
-
随机势博弈(SPG)
- 如果每个玩家对于自身目标改变或策略选取,都可以映射到某个全局函数中去,这个函数就叫做势函数,这个博弈就叫做势博弈。
-
Dec-POMDP
- 在Dec-POMDP中,多智能体的目标是在能观察到的局部信息基础上实现全部奖励的最大化,在共同利益博弈中解决Dec-POMDP问题是十分困难的。Dec-POMDP是非线性规划问题。
- 目前的解决算法:VDN、QMIX、QTRAN等算法,都基于集中式训练和分散式执行(CTDE)的学习框架。
-
-
不同利益博弈
-
有限零和博弈
-
参与博弈的玩家个数有限,并且是严格的竞争关系,所有玩家的总体收益和指出的总和为零。
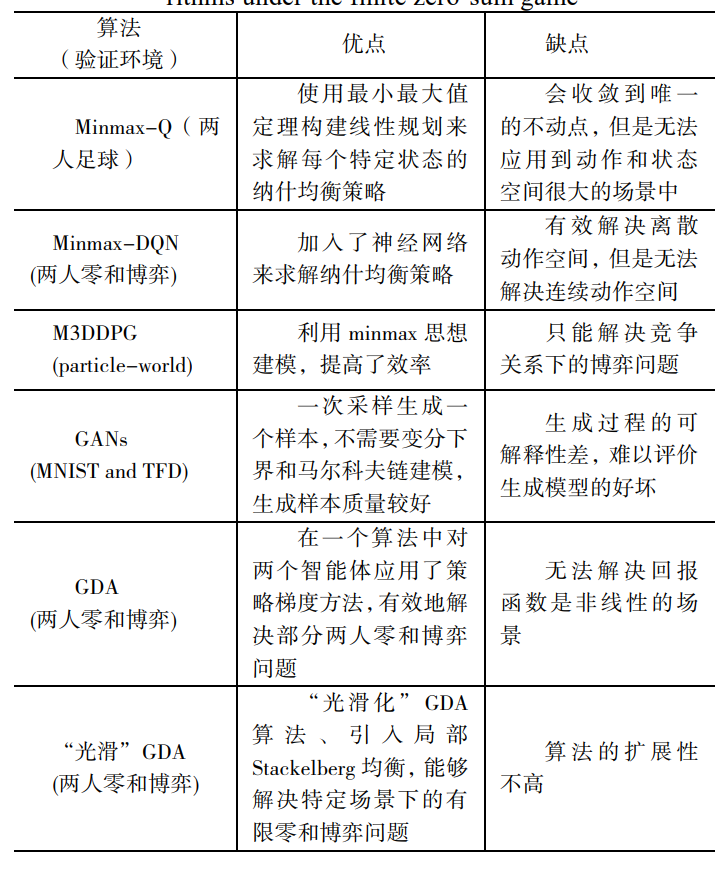
-
-
有限一般和博弈
- 求解一般和随机博弈的计算复杂度是PPAD,而求解零和博弈的计算复杂度是P-complete,所以解决一般和的随机博弈问题的难度比零和的随机博弈要困难很多。
-
-
-
扩展式博弈
-
完全信息的扩展式博弈
- 先决策玩家无法知道后决策玩家的策略,因此会导致不可置信的纳什均衡存在
- 典型算法:α-β修剪算法
- 例子:AlphaGO系列,使用蒙特卡洛树搜索的框架进行模拟,并在学习策略时中使用监督学习。
-
不完全信息的扩展式博弈
-
即时
-
难点:①子博弈之间相互关联;②存在状态不可分的信息集,这使得强化学习中基于状态估值方法不再适用;③博弈求解规模比较大。
-
反事实遗憾值最小化算法(CFR)
- 结合了遗憾值最小算法和平均策略,通过最小化单个信息集合上的遗憾值来达到最小化全局遗憾的目标,最终使得博弈过程中的平均策略趋近于纳什均衡
- 缺点:时间复杂度高和收敛速度慢
- 算法改进:
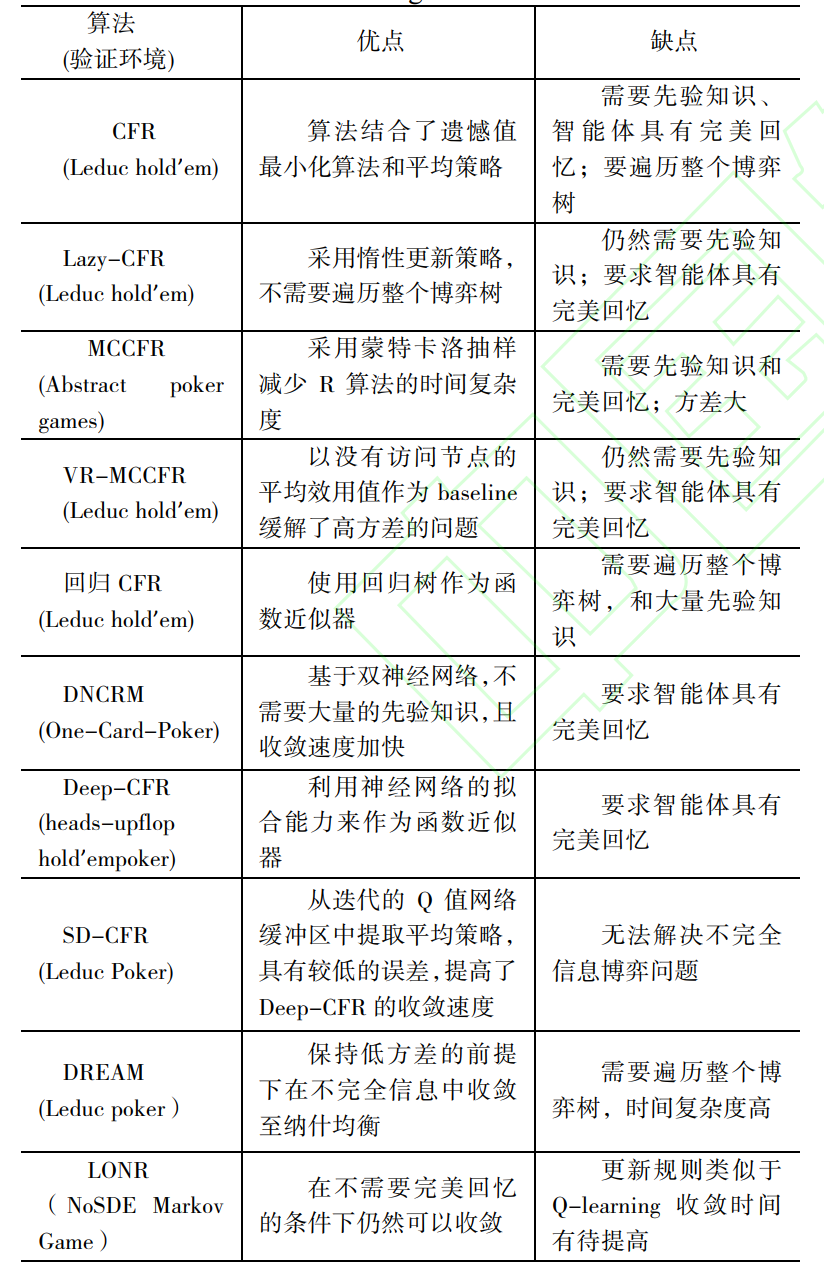
-
虚拟自我对弈算法(NFSP)
- 虚拟对弈(FP算法):根据对手的平均策略做出最佳反应来求解纳什均衡的一种算法,重复迭代后该算法在两人零和博弈、势博弈的平均策略将会收敛到纳什均衡。
- NFSP系列算法:
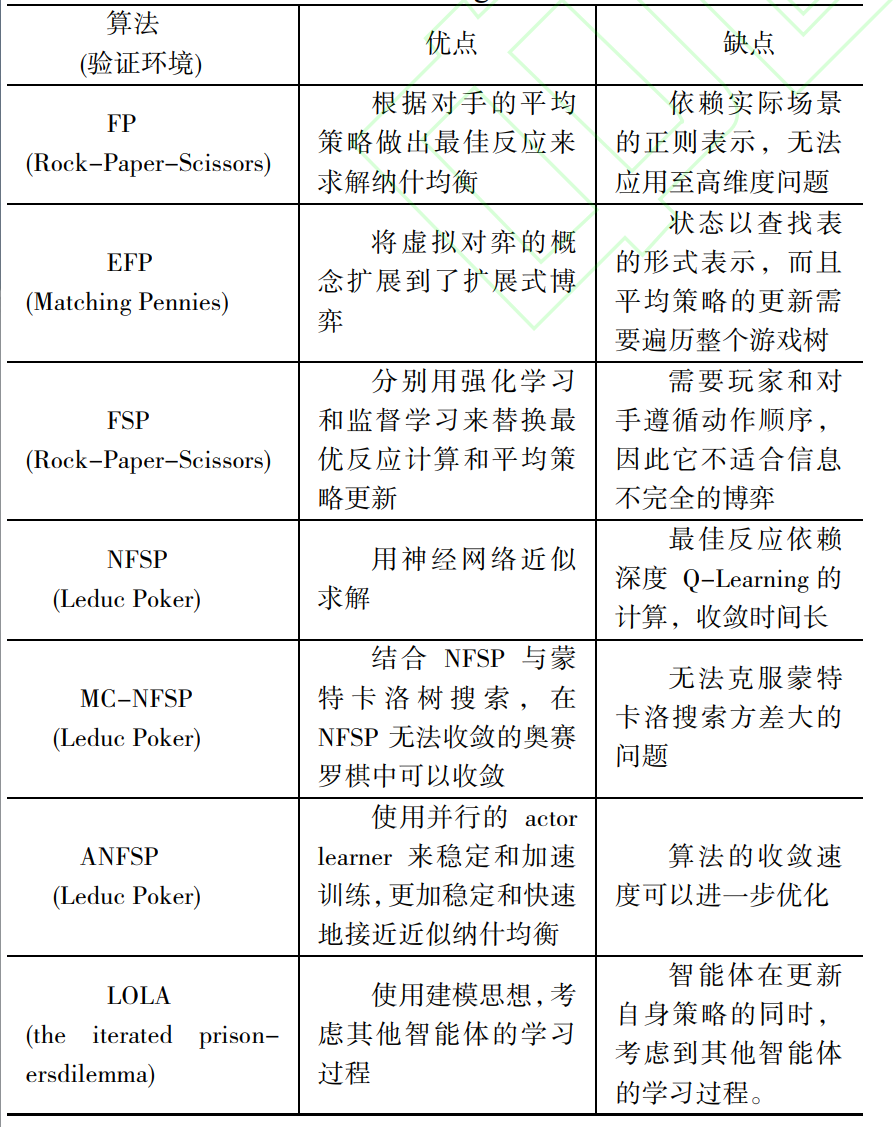
-
-
-
多智能体博弈强化学习算法的重难点
- 博弈强化学习算法的优化
- 收敛性
- 求解法则
- 博弈强化学习算法模型
- 目前在具体的建模过程中考虑的因素较少,导致模型过度简化
- 博弈强化学习算法的通用性和扩展性
- 博弈强化学习算法的优化