并发容器
一、写时复制的List和Set
CopyOnWrite即写时复制,或称写时拷贝,是解决并发问题的一种重要思路。
一)CopyOnWriteArrayList
该类实现了List接口,它的用法与其他List基本一样。其特点如下:
1)它是线程安全的
2)它的迭代器不支持修改操作,但也不会抛出ConcurrentModificationException
3)它以原子方式支持一些复合操作,该类支持的两个原子方法:
//不存在才添加,添加成功返回true,否则返回false public boolean addIfAbsent(E e) //批量添加c集合中的非重复元素,不存在才添加,返回实际添加个数 public int addAllAbsent(Collection<? extends E> c)
CopyOnWriteArrayList的内部也是一个数组,但这个数组是以原子方式被整体更新的。
每次修改操作,都会新键一个数组,复制原数组的内容到新数组,在新数组上进行需要
的修改,然后以原子的方式设置内部数组的引用,这就是写时复制。
所有的读操作,都是先拿到当前引用的数组,然后直接访问该数组,在读的过程中可能
内部数组的引用已经被修改,但这不会影响读操作,它依旧访问原数组内容。
换句话说,数组内容都是只读的,写操作都是通过新键数组,然后原子性地修改数组
引用来实现的。内部数组声明为:
//声明为volatile保证内存可见性 private volatile transient Object[] array;
访问/设置该数组的方法:
final Object[] getArray() { return array; } final void setArray(Object[] a) { array = a; }
读不需要锁,可以并行,但写需要锁。CopyOnWriteArrayList内部使用ReentrantLock:
transient final ReentrantLock lock = new ReentrantLock();
默认构造方法:
public CopyOnWriteArrayList() { setArray(new Object[0]); }
//add方法:
public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
每次修改都要创建一个新的数组,然后复制所有的内容,这听上去是一个难以让人接受的方案,
如果数组较大,修改操作又比较频繁,可以想象,CopyOnWriteArrayList性能是很低的。事实
确实如此,CopyOnWriteArrayList不适用于数组很大且修改频繁的场景。它是以优化读为目标
的,读不需要同步性能很高,但这牺牲了写的性能。
之前介绍了保证线程安全的两种思路:一种是锁,使用synchronized或ReentrantLock;
另一种是循环CAS。写时复制是不同与这两种的另一种思路:写时复制通过复制资源减少
冲突。对于读远远多于写的场景,是一种很好的解决方案。
写时复制是一种重要的思维,用于各种计算机程序中,比如操作系统内部的进程管理和内存管理。
二)CopyOnWriteSet
该类内部是通过CopyOnWriteArrayList实现的:
private final CopyOnWriteArrayList<E> al;
在构造方法中被初始化:
public CopyOnWriteArraySet() { al = new CopyOnWriteArrayList<E>(); }
其add方法为:
public boolean add(E e) { return al.addIfAbsent(e); }
其适用场景类似于CopyOnWriteArrayList
二、ConcurrentHashMap
与HashMap相比,它有如下特点:
1)并发安全
2)直接支持一些原子复合操作
3)支持高并发,读操作完全并行,写操作支持一定程度并行
4)迭代不用加锁,不会抛出异常
5)弱一致性
一)并发安全
HashMap不是并发安全的,在并发更新的情况下,HashMap可能会出现死循环,占满CPU。
public static void unsafeConcurrentUpdate() { final Map<Integer, Integer> map = new HashMap<Integer, Integer>(); for(int i = 0; i < 1000; i++) { Thread t = new Thread() { Random rnd = new Random(); @Override public void run() { for(int i = 0; i < 1000; i++) { map.put(rnd.nextInt(), 1); } } }; t.start(); } }
解决办法:使用ConcurrentHashMap
二)原子复合操作
除了map接口,ConcurrentHashMap还实现了一个接口ConcurrentMap接口:
public interface ConcurrentMap<K, V> extends Map<K, V> { //条件更新,如果没有key,更新。 V putIfAbsent(K key, V value); //条件删除:如果map中有key且对应的值为value,则删除,删除成功返回true. boolean remove(Object key, Object value); //条件替换 boolean replace(K key, V oldValue, V newValue); //条件替换 V replace(K key, V value); }
三)高并发的基本机制
在Java7中,主要使用了
1.分段锁
将数据分为多个段,而每个段都有独立的锁。每一个段相当于一个独立的哈希表,
分段依据也是哈希值,无论是保存键值对还是根据键查找,都先根据键的哈希值
映射到段,再在对应的段上进行操作。
采用分段锁技术可以大大地提高并发度,多个段之间可以并行读写。
//concurrencyLevel表示估计更新的线程数 public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
2.读不需要锁
多个读可以并行,写的同时也可以读。
三)迭代安全
ConcurrentHashMap,在迭代过程中,如果另一个线程对容器进行了修改,迭代会继续,不会抛异常。
public static void test() { final ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>(); map.put("a", "apple"); map.put("b", "banana"); Thread t1 = new Thread() { @Override public void run() { for (Map.Entry<String, String> entry : map.entrySet()) { try { Thread.sleep(1000); } catch (Exception e) { e.printStackTrace(); } System.out.println(entry.getKey() + " : " + entry.getValue()); /*a : apple b : banana c : cee*/ } } }; t1.start(); //确保t1启动 try { Thread.sleep(100); } catch (Exception e) { e.printStackTrace(); } map.put("c", "cee"); }
public static void test() { final ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>(); map.put("a", "apple"); map.put("b", "banana"); Thread t1 = new Thread() { @Override public void run() { for (Map.Entry<String, String> entry : map.entrySet()) { try { Thread.sleep(1000); } catch (Exception e) { e.printStackTrace(); } System.out.println(entry.getKey() + " : " + entry.getValue()); /*a : apple b : banana c : cee*/ } } }; t1.start(); //确保t1启动 try { Thread.sleep(100); } catch (Exception e) { e.printStackTrace(); } map.put("c", "cee"); //如果将语句改为;输出为: /*a : apple b : banana*/ //这叫弱一致性 }
四)弱一致性
如果在遍历的过程中,内部元素发生变化,如果变化发生在已经遍历的部分,
迭代器就不会反应出来,变化发生在未遍历的部分,迭代器就会发现并反应
出来,这就是弱一致性。这种情况还出现在ConcurrentHashMap另外一个方法:
public void putAll(Map<? extends K, ? extends V> m)
该方法并非原子操作,而是调用put方法逐个元素进行添加。
三)基于跳表的Map和Set
Java并发包中的TreeMap/TreeSet对应的版本是ConcurrentSkipListMap和ConcurrentSkipListSet
一)基本概念
ConcurrentSkipListSet是基于ConcurrentSkipListMap实现的。
ConcurrentSkipListMap特点:
1)没有使用锁,所以操作都是无阻塞的,所以操作都可以并行,包括写,多线程可以同时写。
2)迭代器不会抛出异常,是弱一致性的
3)支持一些原子复合操作
4)可排序,默认按键的自然顺序,可传递比较器自定义。
示例代码:
Map<String, String> map = new ConcurrentSkipListMap<>(); map.put("c", "call"); map.put("a", "apple"); map.put("b", "banana"); System.out.println(map.toString()); //{a=apple, b=banana, c=call}
需要说明的是ConcurrentSkipListMap的size方法,与大多数容器实现不同,这个方法不是常量操作,
它需要遍历所有元素,复杂度为O(N),而且遍历结束后,元素个数已经改变。一般而言,在并发应用
中,这个方法用处不大。
二)基本实现原理
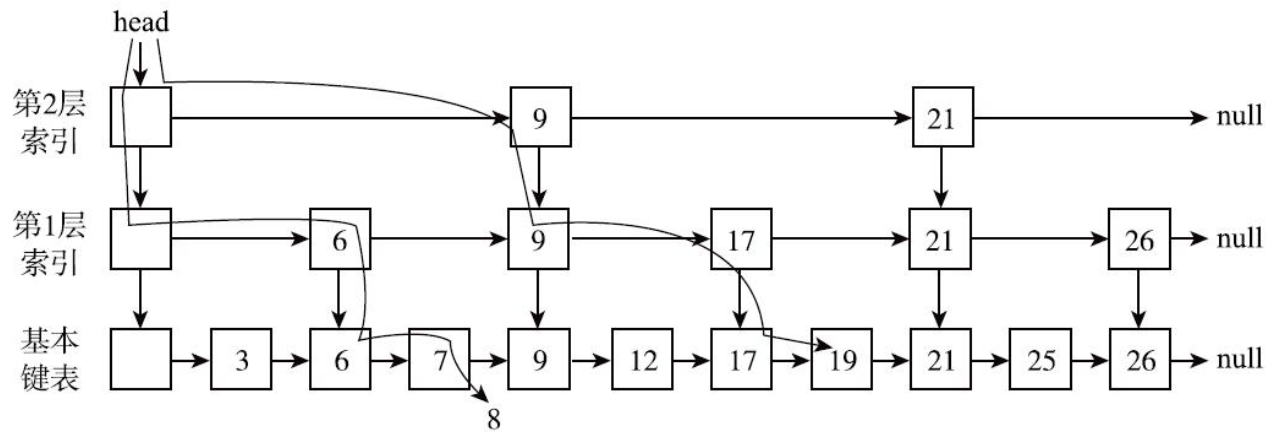
跳表是基于链表的,在链表的基础上加了多层索引结构。
例如,假如容器中包含如下元素:3, 6, 7, 9, 12, 17, 19, 21, 25, 26
对于一个Map来说,这些值可以视为键。ConcurrentSkipListMap会构造类似
下图的跳表结构:

这个链表是有序的,但与数组不同,链表不能根据索引直接定位,不能进行
二分查找。
在该结构中,高层的索引节点一定同时是底层的索引节点。
大致上第一层是基本链表的1/2,第二层是第一层的1/2。
每个索引节点有两个指针一个向右,一个向下。
有了这个结构,就可以实现类似二分查找了。查找元素总是从最高层
开始,将待查值与下一个索引节点的值进行比较,如果大于索引节点
就向右移动,继续比较,如果小于节点则移入下一层进行比较。如图
展示了查找19和8的过程:
这个结构是有序的,查找性能与二叉树类似。这个结构是在更新的过程中保持的,
保存元素的基本思路是:
1)先在基本链表找到插入位置,插入基本链表;
2)更新索引层
对于索引的更新:随机计算一个数,表示为该元素最高建几层的索引,一层的概率为1/2,二层为1/4,以此类推。
然后从最高层到最低层,在每一层为该元素建立索引节点,建立索引的位置也是先查找位置再插入。
对于删除元素,ConcurrentSkipListMap不是直接进行真正的删除,而是为了避免冲突,有一个复杂的标记过程,
在内部遍历元素的过程中进行真正的删除。
总结:ConcurrentSkipListMap/ConcurrentSkipListSet基于跳表实现,
有序,无锁,非阻塞,完全并行,主要操作复杂度为0(log(N))。
三、并发队列
Java并发包提供了丰富的队列,可以简单地分为如下几种:
1.无锁非阻塞并发队列:ConcurrentLinkedQueue和ConcurrentLinkedDueue.
它们适用于多个线程并发使用一个队列的的场合,都是基于链表实现,都没有大小
限制,是无解的。size方法不是一个常量运算。这两个类最基础的原理是循环CAS。
2.普通阻塞队列:基于数组的ArrayBlockingQueue,基于链表的LinkedBlockingQueue和LinkedBlockingDeque.
它们都实现了BlockingQueue接口:
//入队,如果队列满,等待直到队列有空间 void put(E e) throws InterruptedException; //出队,如果队列空,等待直到队列不为空,返回头部元素 E take() throws InterruptedException; //入队,如果队列满,最多等待指定时间,如果超时还是满,返回false boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException; //出队 E poll(long timeout, TimeUnit unit) throws InterruptedException;
特别需要注意的是,ArrayBlockingQueue是有界的,创建时指定大小,且在运行的过程中不会改变,这与ArrayDeque不同。
在内部它们都是通过显式锁和显式条件实现的。
3.优先级阻塞队列:PriorityBlockingQueue.
基本实现原理与PriorityQueue类似,基于堆。但它实现了BlockingQueue接口,是阻塞的。
4.延时阻塞队列:DelayQueue
它要求每个元素都实现Delayed接口,接口声明为:
public interface Delayed extends Comparable<Delayed> { //返回一个给定的时间单位unit整数,表示再延长多长时间,小等于0表示不再延长 long getDelay(TimeUnit unit); }
该类用于实现定时任务,它按元素的延时时间出队,只有当元素的延时过期之后才能被队列拿走,
也就是说take方法总是返回第一个过期的元素,如果没有则阻塞等待。
5.其他阻塞队列SynchronousQueue 和 LinkedTransferQueue