
作者 | 王骜
来源 | Serverless 公众号
导读
USENIX ATC (USENIX Annual Technical Conference) 学术会议是计算机系统领域的顶级会议,入选中国计算机协会(CCF)推荐 A 类国际会议列表;本次会议共投稿 341 篇论文,接收 64 篇,录用率 18.8%。
阿里云 Serverless 团队第一个提出在 FaaS 场景下的去中心化快速镜像分发技术,团队创作的论文被 USENIX ATC’21 录用。以下是论文核心内容解读,重点在缩短阿里云函数计算产品 Custom Container Runtime 的函数冷启动端到端延迟。
USENIX ATC 将于 7.14-7.16 在线上举办,论文信息见:
https://www.usenix.org/conference/atc21/presentation/wang-ao
摘要
Serverless Computing(FaaS)是一种新的云计算范式,它允许客户只关注自身的代码业务逻辑,系统底层的虚拟化、资源管理、弹性伸缩等都交给云系统服务商进行维护。Serverless Computing 上支持容器生态,解锁了多种业务场景,但是由于容器镜像复杂,体积较大,FaaS 的 workload 动态性高且难以预测等特性,诸多业界领先的产品和技术并不能很好的应用于 FaaS 平台之上,所以高效的容器分发技术在 FaaS 平台上面临着挑战。
在这篇论文中,我们设计并提出 FaaSNet。FaaSNet 是一个具有高伸缩性的轻量级系统中间件,它利用到镜像加速格式进行容器分发,目标作用场景是 FaaS 中突发流量下的大规模容器镜像启动(函数冷启动)。FaaSNet 的核心组件包含 Function Tree (FT),是一个去中心化的、自平衡的二叉树状拓扑结构,树状拓扑结构中的所有节点全部等价。
我们将 FaaSNet 集成在函数计算产品上,实验结果表明,在高并发下的请求量下,相比原生函数计算(Function Compute, 下称 FC),FaaSNet 可以为 FC 提供 13.4 倍的容器启动速度。并且对于由于突发请求量带来的端到端延迟不稳定时间,FaaSNet 相比 FC 少用 75.2% 的时间可以将端到端延迟恢复到正常水平。
论文介绍
1. 背景与挑战
FC 于 2020 年 9 月支持自定义容器镜像(https://developer.aliyun.com/article/772788)功能,相继 AWS Lambda 在同年 12 月公布了 Lambda container image 支持,表明 FaaS 拥抱容器生态的大趋势。并且函数计算在 2021 年 2 月上线了函数计算镜像加速(https://developer.aliyun.com/article/781992)功能。函数计算这两项功能解锁了更多的 FaaS 应用场景,允许用户无缝将自己的容器业务逻辑迁移到函数计算平台上,并且可以做到 GB 级别的镜像在秒级启动。
当函数计算后台遇到大规模请求导致过多的函数冷启动时,即使有镜像加速功能的加持,也会对 container registry 带宽带来巨大压力,多台机器同时对同一个 container registry 进行镜像数据的拉取,导致容器镜像服务带宽瓶颈或限流,使得拉取下载镜像数据时间变长(即使在镜像加速格式下)。较为直接的做法可以提高函数计算后台 Registry 的带宽能力,但是这个方法不能解决根本问题,同时还会带来额外的系统开销。
1)Workload 分析
我们首先对 FC 两大区域(北京和上海)的线上数据进行了分析:
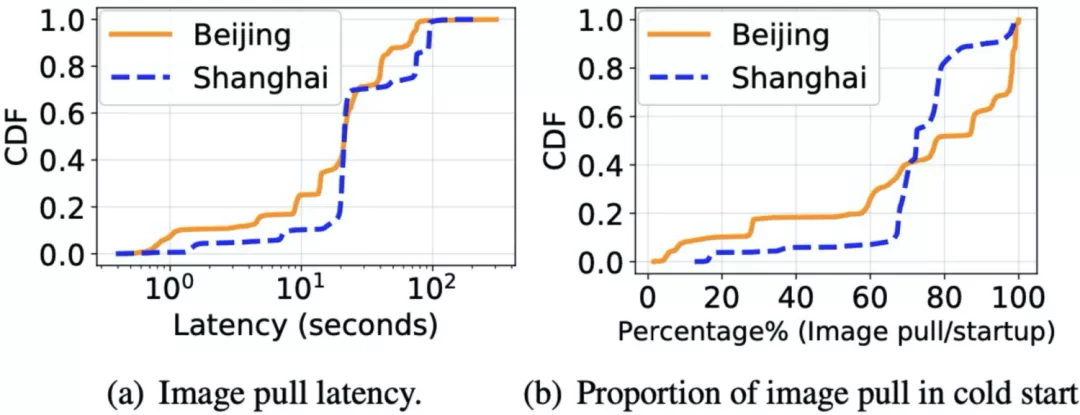
- 图(a)分析了函数冷启动中,FC 系统 pull image 的延迟,可以看到在北京和上海分别有 ~80% 和 ~90% 的拉去镜像延迟大于 10 秒;
- 图(b)展示 pull image 在整个冷启动中的占比,同样可以发现,北京区域内 80% 的函数,上海区域内 90% 的函数拉取镜像时间会占据大于整个冷启动中 60% 的延迟;
workload 的分析表明,函数的冷启动绝大多数时间花在了容器镜像数据的获取之上,所以优化此部分延迟可以大大提高函数的冷启动表现。
根据线上运维的历史记录,某大用户的代表在瞬时会并发拉起 4000 个函数镜像,这些镜像的大小解压前为 1.8GB,解压后大小为 3-4GB,在大流量的请求到达开始拉起容器的瞬间,就收到了容器服务的流控报警,造成了部分请求延迟被延长,严重的时候会收到了容器启动失败的提示。这类问题场景都是亟需我们来解决的。
2)State-of-the-art 对比
学术界和工业界有若干相关技术可以加速镜像的分发速度,例如:
阿里巴巴的 DADI:
https://www.usenix.org/conference/atc20/presentation/li-huiba
蜻蜓:
https://github.com/dragonfly/dragonfly
以及 Uber 开源的 Kraken:
https://github.com/uber/kraken/
- DADI
DADI 提供了一种非常高效的镜像加速格式,可以实现按需读取(FaaSNet 也利用到了容器加速格式)。在镜像分发技术上,DADI 采用了树状拓扑结构,以镜像 layer 粒度进行节点间的组网,一个 layer 对应一个树状拓扑结构,每一个 VM 会存在于多颗逻辑树中。DADI 的 P2P 分发需要依赖若干性能规格(CPU、带宽)较大的 root 节点来担任数据回源角色、维护拓扑中 peer 的管理者角色;DADI 的树状结构偏静态,因为容器 provisioning 的速度一般不会持续很久,所以默认情况下,DADI 的 root 节点会在 20 分钟后将拓扑逻辑解散,并不会一直维护下去。
- 蜻蜓
蜻蜓同样也是一个基于 P2P 的镜像、文件分发网络,其中的组件包块Supernode(Master 节点),dfget(Peer 节点)。类似于 DADI,蜻蜓同样依赖于若干大规格的 Supernode 才可以撑起整个集群,蜻蜓同样通过中央 Supernode 节点来管理维护了一个全链接的拓扑结构(多个 dfget 节点分别贡献同一个文件的不同 pieces 已达到给目标节点点对点传输的目的),Supernode 性能会是整个集群吞吐性能的潜在瓶颈。
- Kraken
Kraken 的 origin、tracker 节点作为中央节点管理整个网络,agent 存在于每个 peer 节点上。Kraken 的 traker 节点只是管理组织集群中 peer 的连接,Kraken 会让 peer 节点之间自行沟通数据传输。但 Kraken 同样是一个以 layer 为单位的容器镜像分发网络,组网逻辑也会成为较为复杂的全连接模式。
通过对上述三种业界领先的技术阐释,我们可以看到几个共同点:
-
第一,三者均以 image layer 作为分发单位,组网逻辑过于细粒度,导致每个 peer 节点上可能会同时有多个 active 数据连接;
-
第二,三者都依赖于中央节点进行组网逻辑的管理以及集群内的 peer 节点协调,DADI 和蜻蜓的中央节点还会负责数据回源,这样的设计要求在生产使用中,需要部署若干大规格的机器来承担非常高的流量,同时还需要进行调参来达到预期的性能指标。
我们带着上述的一些前提条件来反观在 FC ECS 架构下的设计,FC ECS 架构中的每个机器的规格为 2 CPU 核、4GB 内存以及 1Gbps 内网带宽,并且这些机器的生命周期是不可靠的,随时可能被回收。
这样带来了三个较为严重的问题:
-
内网带宽不足导致在全连接中较为容易出现带宽挤兑,导致数据传输性能下降。全连接的拓扑结构没有做到 function-aware,在 FC 下极易引起系统安全问题,因为每台执行函数逻辑的机器是不被FC系统组件信任的,会留下租户 A 截取到租户 B 数据的安全隐患;
-
CPU 和带宽规格受限。由于函数计算 Pay-per-use 的计费特性,我们集群内的机器生命周期是不可靠的,无法在机器池中拿出若干机器作为中央节点管理整个集群。这部分机器的系统开销会成为一大部分负担,还有就是可靠性不能被保证,机器会导致 failure 的情况;FC 所需要的是继承按需付费特性,提供可以瞬时组网的技术。
-
多函数问题。上述三者并没有 function-awareness 机制,例如 DADI P2P 中,可能存在单节点存有过多镜像成为热点,造成性能下降的问题。更严重的问题是多函数拉取本质上是不可预测的,当多函数并发拉取打满带宽,同期的从远端下载的服务也会受到影响,如代码包,第三方依赖下载,导致整个系统出现了可用性的问题。
带着这些问题,我们在下一节中详细阐释 FaaSNet 设计方案。
2. 设计方案 - FaaSNet
根据上述三种业界成熟的 P2P 方案,没有做到 function 级别的感知,并且集群内的拓扑逻辑大多为全连接的网络模式,并且对机器的性能提出了一定需求,这些前置设定不适配 FC ECS 的系统实现。所以我们提出了 Function Tree (下称 FT),一个函数级别并且是 function-aware 的逻辑树状拓扑结构。
1)FaaSNet 架构
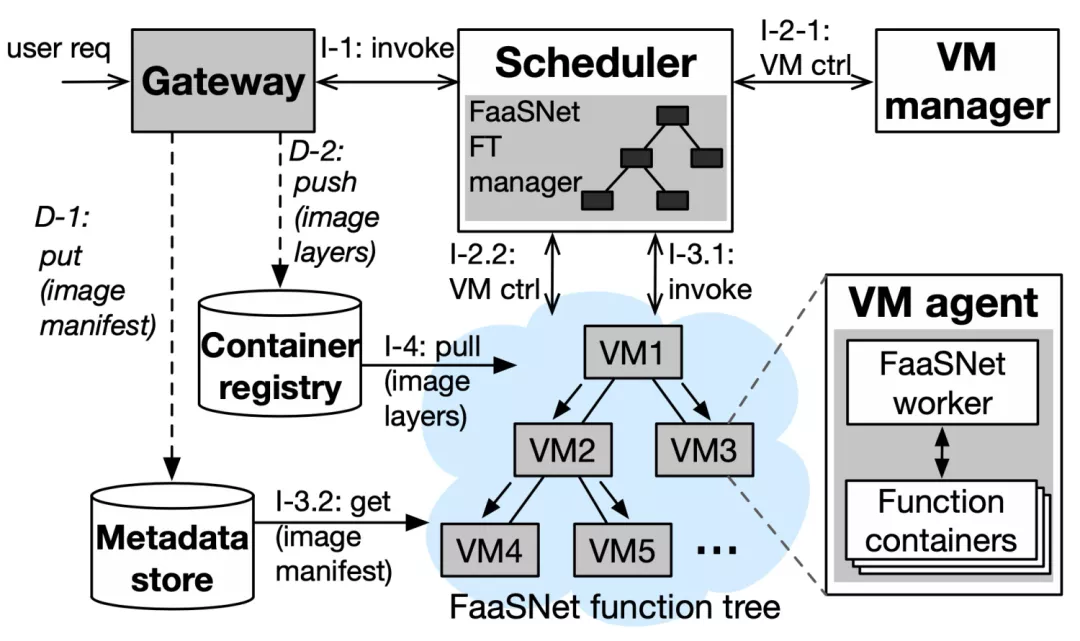
图中灰色的部分是我们 FaaSNet 进行了系统改造的部分,其他白色模块均延续了 FC 现有的系统架构。值得注意的是,FaaSNet 所有 Function Tree 均在 FC 的调度器上进行管理;在每一个 VM 上,有 VM agent 来配合 scheduler 进行 gRPC 通信接受上下游消息;并且,VM agent 也负责上下游的镜像数据获取与分发。
2)去中心化的函数/镜像级别自平衡树状拓扑结构
为了解决上述三个问题,我们首先将拓扑结构提升到了函数/镜像级别,这样可以有效降低每一个 VM 上的网络连接数,另外,我们设计了一种基于 AVL tree 的树状拓扑结构。接下来,我们详细阐述我们的 Function Tree 设计。
Function Tree
- 去中心化自平衡二叉树拓扑结构
FT 的设计来源于 AVL tree 算法的启发,在 FT 中,目前不存在节点权重这个概念,所有节点等价(包括根节点),当树中添加或删除任意个节点时,整个树都会保持一个 perfect-balanced 结构,既保证任意一个节点的左右子树的高度差的绝对值不超过 1。当有节点加入或删除后,FT 会自己调整树的形状(左/右旋)从而达到平衡结构,如下图右旋示例所示,节点 6 即将被回收,它的回收导致了以节点 1 作为父节点的左右子树高度不平衡,需要进行右旋操作已达到平衡状态,State2 代表旋转后的终态,节点 2 成为了新的树根节点。注:所有节点均代表 FC 中的 ECS 机器。
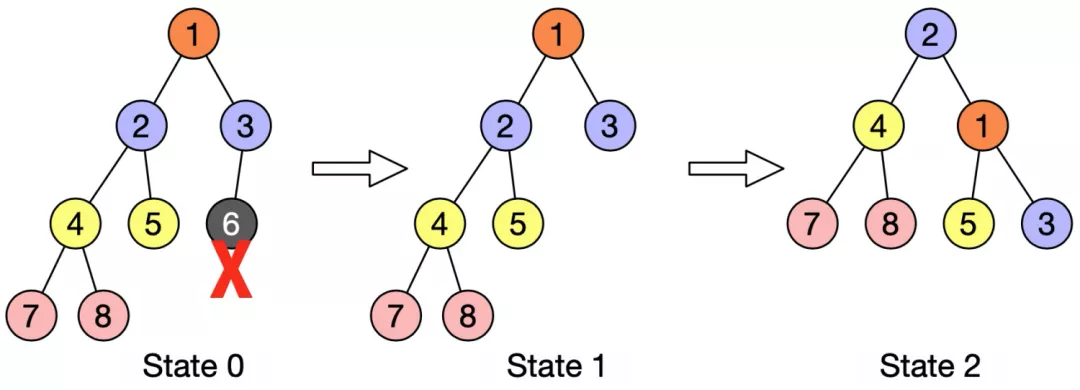
在 FT 中,所有节点全部等价,主要职责包括:1. 从上游节点拉取数据;2. 向下游两个孩子节点分发数据。(注意,在 FT 中,我们不指定根节点,根节点与其他节点的唯一区别是他的上游为源站,根节点不负责任何的 metadata 管理,下一部分我们会介绍我们如何进行元信息的管理)。
- 多个 FT 在多个 peer 节点上的重叠
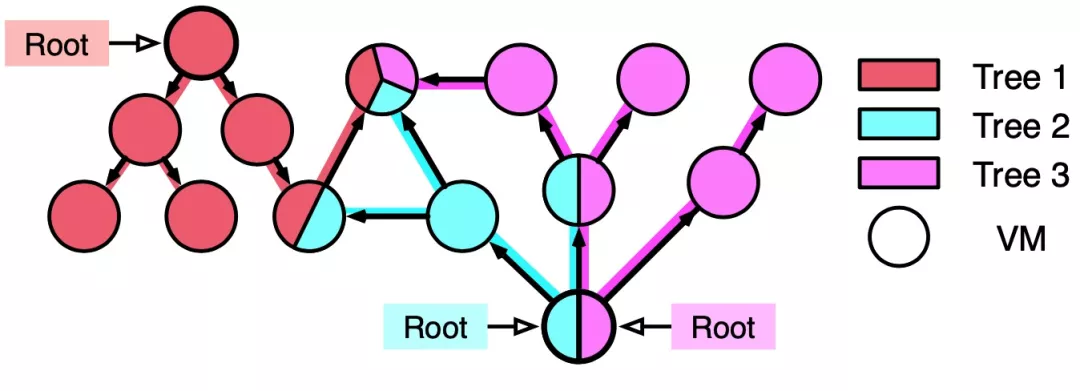
一个 peer 节点上势必会存在同一用户下的不同函数,所以一定会出现一个 peer 节点位于多个 FT 的情况。如上图所示,实例中有三个 FT 分别属于 func 0-2。但是由于 FT 的管理是互相独立的,所以即使有重叠下的传输,FT 也是可以帮助每个节点找到对应的正确的上有节点。
另外我们会将一个机器可以 hold 最大数量函数做限制已达到 function-awareness 的特性,进一步解决了多函数下拉取数据不可控的问题。
设计的正确性讨论
- 通过在 FC 上集成,我们可以看到因为 FT 中的所有节点等价,我们不需要依赖于任何的中央节点;
- 拓扑逻辑的管理者不存在于集群之中,而是由 FC 的系统组件(scheduler)来维护这一内存状态,并通过 gRPC 随着创建容器的操作请求下发给每一个 peer 节点;
- FT 完美适配 FaaS workload 的高动态性,以及集群中任何规模的节点加入于离开,FT 会自动更新形态;
- 以函数这一较粗粒度进行组网,并且利用二叉树数据结构来实现 FT,可以大大降低每个 peer 节点上的网络连接数;
- 以函数为隔离进行组网,可以天然实现 function-aware 以提高的系统的安全性和稳定性。
3. 性能评测
实验中我们选取了阿里云数据库 DAS 应用场景的镜像,以 python 作为 base image,容器镜像解压前大小为 700MB+,拥有 29 层 layers。我们选取压力测试部分进行解读,全部测试结果请参考论文原文。测试系统我们对比了阿里巴巴的 DADI、蜻蜓技术和 Uber 开源的 Kraken 框架。
1)压力测试
压测部分记录的延迟为用户感知的端到端冷启动平均延迟。首先我们可以看出镜像加速功能相比于传统的 FC 可以显著提升端到端延迟,但是随着并发量的提高,更多的机器同时对中央的 container registry 拉取数据,造成了网络带宽的竞争导致端到端延迟上升(橘色和紫色 bar)。但是在 FaaSNet 中,由于我们去中心化的设计,对源站的压力无论并发压力多大,只会有一个 root 节点会从源站拉取数据,并向下分发,所以具有极高系统伸缩性,平均延迟不会由于并发压力的提高而上升。

在压测部分的最后,我们探究了同一个 VM 上如果放置不同 image 的函数(多函数)会带来如何的性能表现,这里我们比较了开启镜像加速功能并且装配 DADI P2P 的 FC(DADI+P2P)和 FaaSNet。
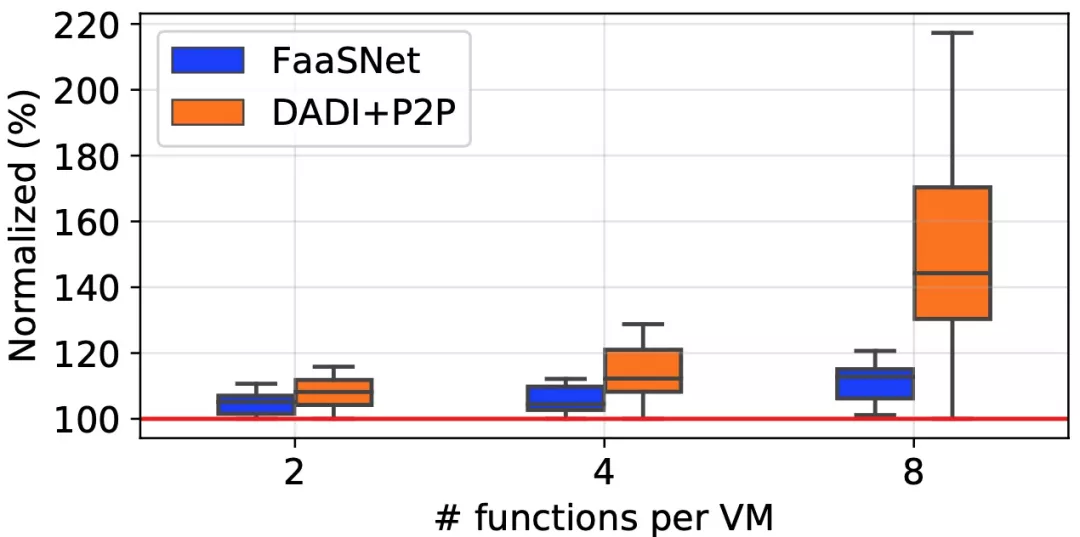
上图纵轴表示标准化后的端到端延迟水平,随着不同镜像的函数的数量增多,DADI P2P 由于 layer 变多,并且 FC 内每台 ECS 的规格较小,对每台 VM 的带宽压力过大,造成了性能下降,端到端延迟已被拉长至 200% 多。但是 FaaSNet 由于在镜像级别建立连接,连接数目远远低于 DADI P2P 的 layer tree,所以仍然可以保持较好的性能。
总结
高伸缩性和快速的镜像分发速度可以为 FaaS 服务商更好的解锁自定义容器镜像场景。FaaSNet 利用轻量级的、去中心化、自平衡的 Function Tree 来避免中央节点带来的性能瓶颈,没有引入额外的系统化开销且完全复用了现有 FC 的系统组件与架构。FaaSNet 可以根据 workload 的动态性实现实时组网已达到 function-awareness,无须做预先的 workload分析与预处理。
FaaSNet 的目标场景不单单局限于 FaaS,在众多的云原生场景中,例如 Kubernetes,阿里巴巴 SAE 在应对突发流量的处理上都可以施展拳脚,来解决由于冷启动过多影响用户体验的痛点,从根本上解决了容器冷启动慢的问题。
FaaSNet 是国内首个云厂商在国际顶级会议发表 Serverless 场景下应对突发流量的加速容器启动技术的论文。我们希望这一工作可以为以容器为基础的 FaaS 平台提供新的机会,可以完全打开拥抱容器生态的大门,解锁更多的应用场景,如机器学习、大数据分析等任务。