1.理解分类与监督学习、聚类与无监督学习。
简述分类与聚类的联系与区别。
简述什么是监督学习与无监督学习。
2.朴素贝叶斯分类算法 实例
利用关于心脏病患者的临床历史数据集,建立朴素贝叶斯心脏病分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:
–心梗
–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传手工演算过程。
|
性别 |
年龄 |
KILLP |
饮酒 |
吸烟 |
住院天数 |
疾病 |
|
|
1 |
男 |
>80 |
1 |
是 |
是 |
7-14 |
心梗 |
|
2 |
女 |
70-80 |
2 |
否 |
是 |
<7 |
心梗 |
|
3 |
女 |
70-81 |
1 |
否 |
否 |
<7 |
不稳定性心绞痛 |
|
4 |
女 |
<70 |
1 |
否 |
是 |
>14 |
心梗 |
|
5 |
男 |
70-80 |
2 |
是 |
是 |
7-14 |
心梗 |
|
6 |
女 |
>80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
7 |
男 |
70-80 |
1 |
否 |
否 |
7-14 |
心梗 |
|
8 |
女 |
70-80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
9 |
女 |
70-80 |
1 |
否 |
否 |
<7 |
心梗 |
|
10 |
男 |
<70 |
1 |
否 |
否 |
7-14 |
心梗 |
|
11 |
女 |
>80 |
3 |
否 |
是 |
<7 |
心梗 |
|
12 |
女 |
70-80 |
1 |
否 |
是 |
7-14 |
心梗 |
|
13 |
女 |
>80 |
3 |
否 |
是 |
7-14 |
不稳定性心绞痛 |
|
14 |
男 |
70-80 |
3 |
是 |
是 |
>14 |
不稳定性心绞痛 |
|
15 |
女 |
<70 |
3 |
否 |
否 |
<7 |
心梗 |
|
16 |
男 |
70-80 |
1 |
否 |
否 |
>14 |
心梗 |
|
17 |
男 |
<70 |
1 |
是 |
是 |
7-14 |
心梗 |
|
18 |
女 |
70-80 |
1 |
否 |
否 |
>14 |
心梗 |
|
19 |
男 |
70-80 |
2 |
否 |
否 |
7-14 |
心梗 |
|
20 |
女 |
<70 |
3 |
否 |
否 |
<7 |
不稳定性心绞痛 |
3.使用朴素贝叶斯模型对iris数据集进行花分类。
尝试使用3种不同类型的朴素贝叶斯:
- 高斯分布型
- 多项式型
- 伯努利型
并使用sklearn.model_selection.cross_val_score(),对各模型进行交叉验证。
1.理解分类与监督学习、聚类与无监督学习。
(1)简述分类与聚类的联系与区别。
联系:通常,为有监督分类提供若干已标记的模式(预分类过),需要解决的问题是为一个新遇到的但无标记的模式进行标记.在典型的情况下,先将给定的无标记的模式用来学习〔训练),反过来再用来标记一个新模式.聚类需要解决的问题
(2)简述什么是监督学习与无监督学习。
监督学习:通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。
无监督学习:在于我们事先没有任何训练样本,而需要直接对数据进行建模。
2.

3.
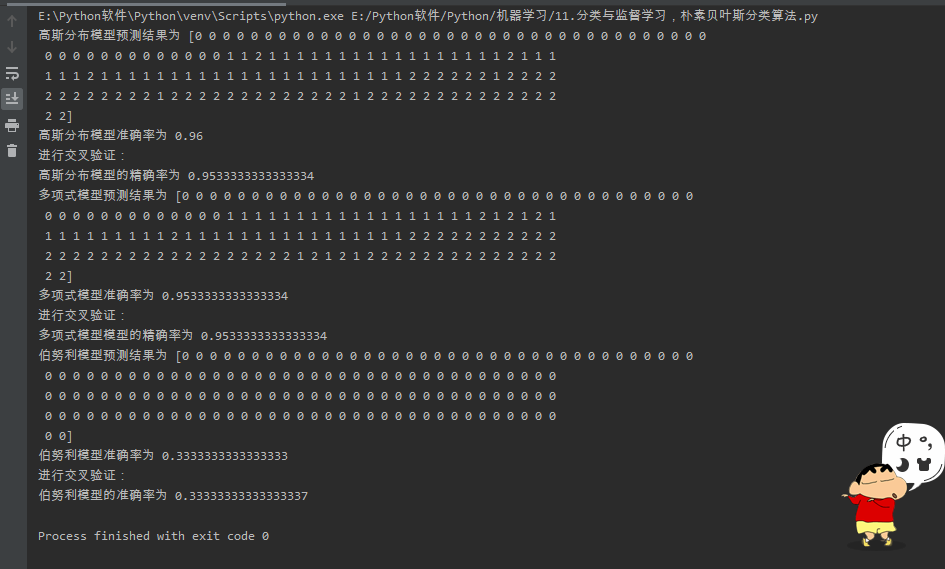
from sklearn.datasets import load_iris #sklean的鸢尾花数据集 from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB #导入高斯贝叶斯,多项式型高斯贝叶斯,伯努利型高斯贝叶斯 from sklearn.model_selection import cross_val_score #sklean的交叉验证分数 # 导入鸢尾花数据集 iris = load_iris() data = iris['data'] #长度数据 target = iris['target'] #种类数据 # 高斯分布型 GNB_model = GaussianNB() # 构建高斯分布模型 GNB_model.fit(data, target) # 训练 GNB_pre = GNB_model.predict(data) # 预测 print("高斯分布模型预测结果为",GNB_pre) print("高斯分布模型准确率为",sum(GNB_pre == target) / len(data)) # 进行交叉验证 print("进行交叉验证:") GNB_score = cross_val_score(GNB_model, data, target, cv=10) print("高斯分布模型的精确率为", GNB_score.mean()) # 多项式型 MNB_model = MultinomialNB() # 构建多项式模型 MNB_model.fit(data, target) # 训练 MNB_pre = MNB_model.predict(data) # 预测 print("多项式模型预测结果为",MNB_pre) print("多项式模型准确率为" ,sum(MNB_pre == target) / len(data)) print("进行交叉验证:") # 进行交叉验证 MNB_score = cross_val_score(MNB_model, data, target, cv=10) print("多项式模型模型的精确率为",MNB_score.mean()) # 伯努利型 BNB_model = BernoulliNB() # 构建伯努利模型 BNB_model.fit(data, target) # 训练 BNB_pre = BNB_model.predict(data) # 预测 print("伯努利模型预测结果为",BNB_pre) print("伯努利模型准确率为",sum(BNB_pre == target) / len(data)) print("进行交叉验证:") # 进行交叉验证 BNB_score = cross_val_score(BNB_model, data, target, cv=10) print("伯努利模型的准确率为", BNB_score.mean())