ZLX算法-----同构类问题的有力骗分算法
前言:
ZLX算法是一种解决判定性同构问题的蒙特卡罗式骗分算法:总能在确定的运行时间内出解,但是得到的解不能保证正确。
尽管由于具有拓扑序,树同构和仙人掌同构存在多项式算法,但是图同构已经证明是NP问题,本文所述的是一种不能保证完全正确,但是正确概率很大的多项式算法(即伪多项式算法),与图同构是NP问题不冲突。
ZLX算法能保证两个图如果同构,一定输出YES,但是不能保证如果不同构,一定输出NO,ZLX算法的精髓就在于寻找不同构的证据,如果找不到,那么就认为同构。我们将证明,ZLX算法的正确性比较高,想要构造出一种卡掉ZLX算法的图是不太容易的,但是也能卡掉。
原题链接:http://218.28.19.228/cogs/problem/problem.php?pid=2234
我们从一道例题开始讲起:
树木园:
给定两个仙人掌,判断是否同构。
仙人掌同构的定义:对其中一颗仙人掌进行重标号,如果重标号后两颗仙人掌相同,那么这两颗仙人掌同构。
算法一:
暴力匹配
时间复杂度O(Ann)(排列数),期望得分10分
算法二:
输出No,期望得分45分
算法三:随机输出Yes和No,期望得分50分,最高得分100分
算法四:输出Yes,期望得分55分
算法二三四在多组数据的情况下全部失效。
Hash算法系列:
我们需要用一些图论中与编号无关的东西来描述图的某个特征。
定理1:
图同构<->则图的所有与编号无关的特征相同.
证明:显然
定理2:
图的一些与编号无关的特征相同是图同构的必要条件,但不充分。
证明:显然
因此,我们hash的关键就在于选取有代表性的特征,且获得这些特征的时间复杂度在可容忍的范围内。
最容易想到的是用图中每个点的度数(与该点相邻的点的个数)来描绘图的特征,那么问题来了,计算度数后怎么进行匹配呢?
从小到大排序!
定理3:
图同构->两个图点的度数分别排序后完全匹配
证明:我们把图的信息压缩在了点上,排序就相当于对图进行重编号,而且重编号的点必须度数相同,于是我们就可以得到一个不保证正确的算法:
算法五:分别计算两个图所有点的度数,然后排序判断序列是否相等。
期望得分:80分(出题人数据太水啦)
我们不妨把排序后的度数称为度数序
很容易就能构造出度数序相同,但是图不同构的图,因为度数只能储存某个点到相邻点的边信息,而这个点跟比较远的点的关系难以被储存
我举一个简单易懂的例子:
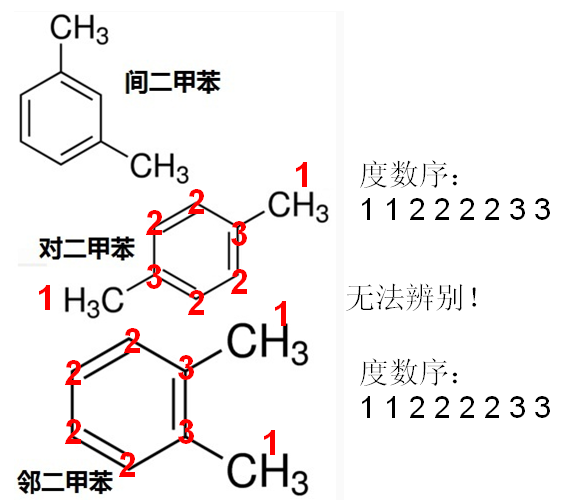
怎样才能表示更精确的信息呢?
度数叠加!
我们再次计算某个点的邻接点的一层度数的和作为某个点的二层度数,然后重新得出一个序列

为什么叠加一层就能辨别出来对二甲苯和邻二甲苯呢?
因为我们把某个点邻接点的邻接点的信息传到了这个点!某个点的邻接点的一层度数包含了邻接点的邻接点的信息,我们通过一层叠加,就把这个信息传到了这个点。
我们计算某个点的邻接点的二层度数的和作为某个点的三层度数
这样,某个点邻接点的邻接点的邻接点的信息就传到了这个点.
我们计算某个点的邻接点的三层度数的和作为某个点的四层度数
……
我们计算某个点的邻接点的M-1层度数的和作为某个点的M层度数
这样,我们就把更多的度数信息压缩在了这个点.
定理4:A点的信息最先被传到B点的时间(需要叠加的层数)规模为dis(a,b)((a,b)的最短路径)
证明:这个可以通过自己意淫
定理5:点数为n的简单无向图(路径长度全为1)的不重复的最长的最短路径(图的直径?)至多为n
最坏的情况就是一条链,因此我们运行n次,每个点就一定会包含全图的度数信息,总时间复杂度为O(n*m),如果我们假设仅由度数信息就可判断是否同构,
就一定能保证正确。
但是,实际上叠加层数不需要很多,我就控制了20层左右就基本上能输出正解,
构造出20层以上仍然不能判断出来的图是不太容易的
以上的算法实际上通过上述性质利用了图的另一个信息:点与点之间的路径信息
剩下十分Wa在一颗小树和小仙人掌
是由于树和仙人掌的度数对结构的影响不如一般图明显,所以树和仙人掌需要更大的度数叠加
时间复杂度O(m*20),期望得分90分
策略一:树和仙人掌直接用特定的同构做
策略二:动态调整层数,如果N大层数就放小,如果N小层数就放大
期望得分100分
一些优化
空间优化:可以用滚动数组来叠加,防止M掉
Hash的优化:对多个大质数取模,或者变加法hash为乘法hash,异或和hash,或者把几种hash有机结合起来
扩展和优化
利用图的其他与标号无关的关键信息进行加强版的hash:每个双连通分量的大小,图的割顶,割桥,树的重心,仙人掌的某些点被套在大小为多少的环内,同样,我们为了快速传递整个图的信息,也可以对这些特征计算特征值然后用快速叠加算法优化正确率。
如果hash功能强,求有多少种重标号方式(即匹配方式)也许也是可以的。
如果你觉得本算法太难(其实本算法只难在信息传递的证明,且严格意义上来讲并不能被鄙视为一个骗分算法,因为其他算法也是hash啊!都有可能被卡啊),请看真·正解:
对于树,我们先找重心,然后以重心为根用有根树的hash,如果有多个重心,我们新建一个超级父亲指向这些重心即可
暴力可能有最小表示法
对于仙人掌上的每个环,我们新建一个红点连向环上所有的点,然后把原先环上的边全部删除。

出题人:这样就可以通过样例 2 辣! ……等等 那我为什么无法通过样例 3?
因为我们这样处理的时候忽略了环上的顺序!样例 3 就是这样的一个情况。

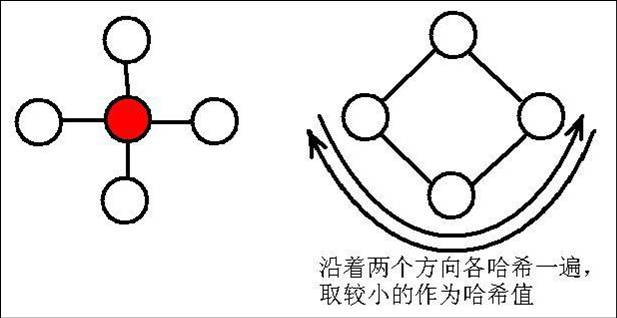
首先我们需要一种不支持交换律的哈希。(出题人:RK 啥的随便搞辣。。。 如果一个红点不是根节点,那么就从父亲节点沿着环的两个方向分别哈希一
遍,取较小值作为哈希值
代码量要5K+,5K+,还要考虑成吨的情况!
况且我这种算法是可以用来做一般图的!
虽然我说了一大堆不知所云的内容,代码是非常简单的:
#include <fstream> #include <algorithm> #include <queue> #include <vector> #define N 100010 using namespace std; ifstream in("cactus.in"); ofstream out("cactus.out"); vector<int> F[N],G[N]; int n,m; bool flag=1;//是否判定为同构 int mod=1000007;//可以对多个大质数取模 int M; class node { public: int s[N]; }A[11],B[11]; bool operator <(node a,node b) { for(int i=1;i<=n;i++)return a.s[i]<b.s[i]; return 1; } void read() { int i,u,v; in>>n>>m; for(i=1;i<=m;i++) { in>>u>>v; G[u].push_back(v); G[v].push_back(u); A[1].s[u]++; A[1].s[v]++; } for(i=1;i<=m;i++) { in>>u>>v; F[u].push_back(v); F[v].push_back(u); B[1].s[u]++; B[1].s[v]++; } //计算两个图的第一层度数(实为度数的二倍) M=min(1000,10000000/(n*20)); M=max(M,10); //M为层数,动态调整层数 } void work() { int i,j,k,u,v; for(k=2;k<=M;k++) { for(i=1;i<=n;i++) { u=i; for(j=0;j<G[u].size();j++)//第二层由第一层转移,A[2]实为A[k],A[1]对应A[k-1],滚动数组优化节省空间 { v=G[u][j]; A[2].s[u]+=A[1].s[v]; A[2].s[u]%=mod; } } for(i=1;i<=n;i++) { u=i; for(j=0;j<F[u].size();j++) { v=F[u][j]; B[2].s[u]+=B[1].s[v]; B[2].s[u]%=mod; } } A[1]=A[2]; B[1]=B[2]; sort(A[2].s,A[2].s+n+1);//对该层度数进行排序 sort(B[2].s,B[2].s+n+1); for(i=1;i<=n;i++) { if(A[2].s[i]!=B[2].s[i]) { flag=0;//如果某个度数不对应,一定不同构 break; } } for(i=1;i<=n;i++)A[2].s[i]=0; for(i=1;i<=n;i++)B[2].s[i]=0; if(!flag)break; } if(flag)out<<"YES"<<endl; else out<<"NO"<<endl; } int main() { read(); work(); return 0; }