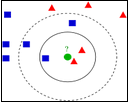
 左图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
左图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相 似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决 策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方 法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
kNN算法本身简单有效,它是一种lazy-learning算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。kNN分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么kNN的分类时间复杂度为O(n)。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分 类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该 算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
优点:精度高、对异常值不敏感、无数据输入假定。缺点:计算复杂度高、空间复杂度高。 适用数据范围:数值型和标称型。
from numpy import * import operator def CreateDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labels def classify0(inx,dataSet,labels,K): dataSetSize=dataSet.shape[0] #(以下三行)距离计算 diffMat=tile(inx,(dataSetSize,1 )) - dataSet sqDiffMat=diffMat**2 sqDistances=sqDiffMat.sum(axis=1) distances=sqDistances**0.5 sortedDistIndicies=distances.argsort() classCount={} #(以下两行)选择距离最小的K个点 for i in range(K): voteIlabel=labels[sortedDistIndicies[i]] classCount[voteIlabel]=classCount.get(voteIlabel,0) + 1 sortedClassCount=sorted ( classCount.items(), #排序 key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0]
>>> import KNN
>>> groups,labels=KNN.CreateDataSet()
>>> KNN.classify0([0,0],groups,labels,3)
'B'
>>>