| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11169 |
| 作业目标 | <学会爬取网页数据,并利用,尝试使用软件工程的理论知识,熟悉使用Git> |
| 作业源代码 | https://gitee.com/huang-cy/software-engineering-uml/tree/master/first |
| 学号 | <211814113> |
1. 需求目标
实现网页数据的爬取,并对数据进行处理,得到需要的数据。
2.题目分析
爬取云班课上的相应数据,并进行处理,算出自己的分数,上传码云。
3. 题目思路
- 保存大班课和小班课数据,保存为HTML文件。
- 对HTML数据进行处理。
- 根据资料查询,使用 Jsoup 对HTML进行数据处理。
- 数据获取完成,选择所需数据(主要使用到,“经验值”,”已参与“,”课堂完成部分“,”小测“,“编程题”,“附加题”等数据),进行分数计算,这里有个陷阱(课堂完成部分应该 * 95,编程题 * 95,附加题 * 90)
- 题目完成之后,将所用的到文件传至码云。
4. 题目所用到的一些技术
##### 4.1 Jsoup
4.1.1将网页封装成 Document 对象
Document document = Jsoup.parse(new File("D:\all.html"),"UTF-8");
Element title = document.getElementsByTag("title").first();
System.out.println(title.text());
4.1.2元素获取
- getElementsById根据id查询元素
- getElementsByTag根据标签查询元素
- getElementsByClass根据class获取元素
- getElementsByAttribute根据属性获取元素
Element element = document.getElementById("city_bj");
element = document.getElementsByTag("title").first();
element = document.getElementsByClass("s_name").last();
element = document.getElementsByAttribute("abc").first();
element = document.getElementsByAttributeValue("class", "city_con").first();
4.1.3 Selector选择器
Select 方法支持在Document, Element,或Elements对象中使用。且是上下文相关的,因此可实现指定元素的过滤,或者链式选择访问。** 返回一个Elements集合,并提供一组方法来抽取和处理
4.2 propertise 在 idea 中的配置
右键工程项目 -> New --> Resource Bundle

明明文件 就能生成propertise文件
5.题目过程
5.1 主体函数

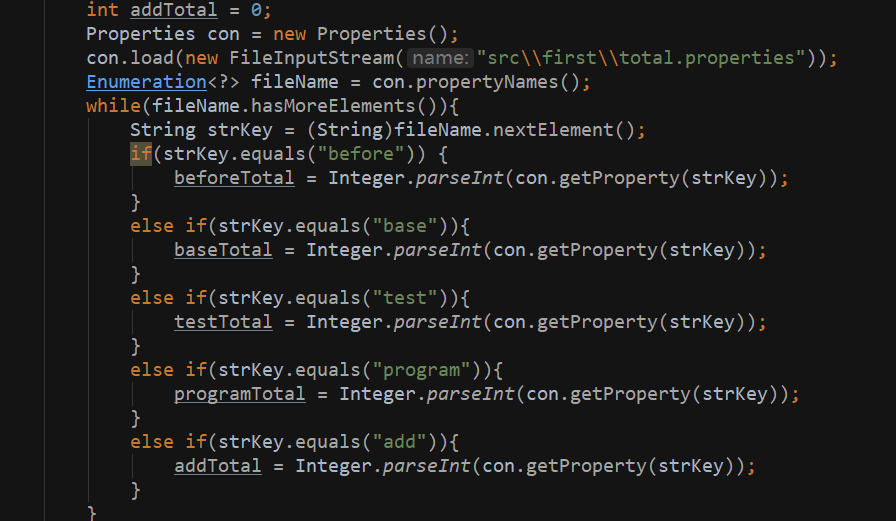
分别计算before,base,test,program,add分数,以及最后的总分
5.2 具体过程
Document allDocument = Jsoup.parse(new File("src\first\all.html"),"UTF-8");
Document smallDocument = Jsoup.parse(new File("src\first\small.html"),"UTF-8");
获取all.html 和 small.html 文件的数据并且分装在Document 对象中
进行具体定位到某一个div整体,
通过for 循环对数据分数进行相加

- 加载propertise文件
6. 最后总结
对java Jsoup 不熟练,有思路却做不出来。在借鉴同学的对具体数据获取的处理之后才把自己的思路做出成果。