Anthor:Terry Li
Link: http://terryli.blog.51cto.com/704315/163315
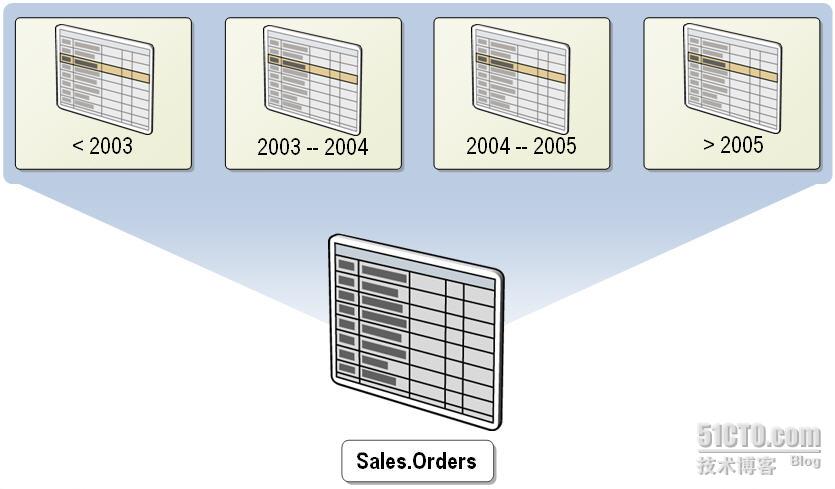
|
分区
|
取值范围
|
|
1
|
(负无穷,500000]
|
|
2
|
[500001,1000000]
|
|
3
|
[1000001,1500000]
|
|
4
|
[1500001,正无穷)
|
|
分区
|
取值范围
|
|
1
|
(负无穷,499999]
|
|
2
|
[500000,999999]
|
|
3
|
[1000000,1499999]
|
|
4
|
[1500000,正无穷)
|
|
分区
|
取值范围
|
|
1
|
<=2007/12/31
|
|
2
|
[2008/01/01,2008/12/31]
|
|
3
|
>=2009/01/01
|
|
文件组
|
分区
|
取值范围
|
|
fg1
|
1
|
(负无穷,500000]
|
|
fg2
|
2
|
[500001,1000000]
|
|
fg3
|
3
|
[1000001,1500000]
|
|
fg4
|
4
|
[1500001,正无穷)
|
|
文件组
|
分区
|
取值范围
|
|
fg1
|
1
|
(负无穷,500000]
|
|
Fg1
|
2
|
[500001,1000000]
|
|
Fg1
|
3
|
[1000001,1500000]
|
|
Fg2
|
4
|
[1500001,正无穷)
|
|
文件组
|
分区
|
取值范围
|
|
fg1
|
1
|
(负无穷,500000]
|
|
Fg1
|
2
|
[500001,1000000]
|
|
Fg1
|
3
|
[1000001,1500000]
|
|
Fg1
|
4
|
[1500001,正无穷)
|
(
NAME = N'Sales',
FILENAME = N'C:\Sales.mdf',
SIZE = 3MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG1
(
NAME = N'File1',
FILENAME = N'C:\File1.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG2
(
NAME = N'File2',
FILENAME = N'C:\File2.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
),
FILEGROUP FG3
(
NAME = N'File3',
FILENAME = N'C:\File3.ndf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
)
LOG ON
(
NAME = N'Sales_Log',
FILENAME = N'C:\Sales_Log.ldf',
SIZE = 1MB,
MAXSIZE = 100MB,
FILEGROWTH = 10%
)
GO
GO
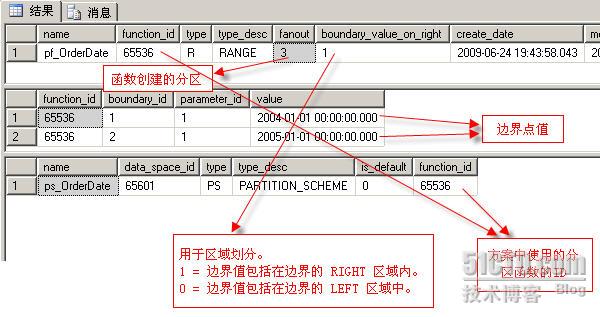
CREATE PARTITION FUNCTION pf_OrderDate (datetime)
AS RANGE RIGHT
FOR VALUES ('2003/01/01', '2004/01/01') --n不能超过 999,创建的分区数等于 n + 1
GO
GO
CREATE PARTITION SCHEME ps_OrderDate
AS PARTITION pf_OrderDate
TO (FG1, FG2, FG3)
GO
GO
CREATE TABLE dbo.Orders
(
OrderID int identity(10000,1),
OrderDate datetime NOT NULL,
CustomerID int NOT NULL,
CONSTRAINT PK_Orders PRIMARY KEY (OrderID, OrderDate)
)
ON ps_OrderDate (OrderDate)
GO
CREATE TABLE dbo.OrdersHistory
(
OrderID int identity(10000,1),
OrderDate datetime NOT NULL,
CustomerID int NOT NULL,
CONSTRAINT PK_OrdersHistory PRIMARY KEY (OrderID, OrderDate)
)
ON ps_OrderDate (OrderDate)
GO
GO
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/6/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/8/13', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/8/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/9/23', 1000)
GO
GO
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/6/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/8/13', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/8/25', 1000)
INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/9/23', 1000)
GO
SELECT * FROM dbo.OrdersHistory
FROM dbo.Orders
WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
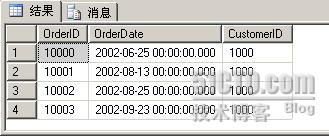
FROM dbo.Orders
WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
COUNT(*) AS [COUNT]
FROM dbo.Orders
GROUP BY $PARTITION.pf_OrderDate(OrderDate)
ORDER BY Partition ;
GO
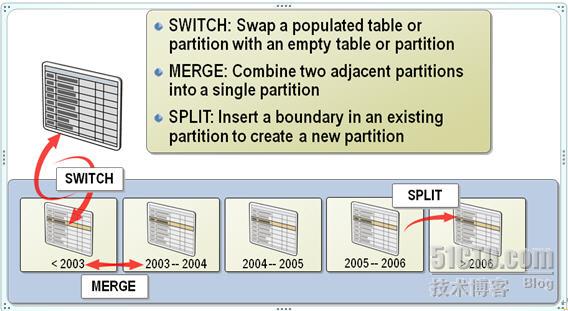
ALTER TABLE dbo.Orders SWITCH PARTITION 1 TO dbo.OrdersHistory PARTITION 1
GO
SELECT * FROM dbo.OrdersHistory
GO
ALTER TABLE dbo.Orders SWITCH PARTITION 2 TO dbo.OrdersHistory PARTITION 2
GO
|
文件组
|
分区
|
取值范围
|
|
FG1
|
1
|
(过去某年, 2003/01/01)
|
|
Fg2
|
2
|
[2003/01/01, 2004/01/01)
|
|
Fg3
|
3
|
[2004/01/01,未来某年)
|
GO
ALTER PARTITION SCHEME ps_OrderDate NEXT USED FG2
ALTER PARTITION FUNCTION pf_OrderDate() SPLIT RANGE ('2005/01/01')
GO
|
文件组
|
分区
|
取值范围
|
|
FG1
|
1
|
(过去某年, 2003/01/01)
|
|
Fg2
|
2
|
[2003/01/01, 2004/01/01)
|
|
Fg3
|
3
|
[2004/01/01, 2005/01/01)
|
|
Fg2
|
4
|
[2005/01/01, 未来某年)
|
GO
ALTER PARTITION FUNCTION pf_OrderDate() MERGE RANGE ('2003/01/01')
GO
|
文件组
|
分区
|
取值范围
|
|
Fg2
|
1
|
[过去某年, 2004/01/01)
|
|
Fg3
|
2
|
[2004/01/01, 2005/01/01)
|
|
Fg2
|
3
|
[2005/01/01, 未来某年)
|
FROM dbo.OrdersHistory
WHERE $PARTITION.pf_OrderDate(OrderDate) = 2
FROM dbo.OrdersHistory
WHERE $PARTITION.pf_OrderDate(OrderDate) = 1
select * from sys.partition_range_values
select * from sys.partition_schemes
本文出自 “李涛的技术专栏” 博客,请务必保留此出处http://terryli.blog.51cto.com/704315/169601
以下为来自网络收集的信息:
问题:SqlServer 分区表一定快吗?
数据库一个表比较大,所以想对该表进行分区。我的计划是对数据库分多个文件组和文件,但都存在一块硬盘的一个分区里(这个服务器只有一块硬盘,一个是C区,一个是D区)
查阅资料上说“若数据库服务器存在多个CPU,则为每个分区分配一个线程,并且分区对应的文件组分别存储在不同物理硬盘中,则每个CPU并行执行查询操作,从而提高效率”。
我想问下,若每个分区存储都是存在一个文件组中,或者多个文件组还是在 一个物理磁盘里,那是不是多个线程还是要串行查询的?
感觉资料上都说得比较笼统,没有事实的图文和理论来证明。
请大侠们帮忙解答下,谢谢!
回答:
1、如果分區表放在一塊硬盤中(一個分區或是多個分區),不會有太大提高,因為讀數據都是要從這塊硬盤來讀。
2、還要看查詢的語句,如果是:select * from 分區表,那分區比不分區可能還要慢。因為要讀出全部數據,分區表還要合併數據。(此處是指分區表放到一塊硬盤中,如果是放到多塊硬盤中,會快。)
3、如果有三個分區,分別放到三塊硬盤上,那讀數據時,按分區方法,有可能系統會有三個線程,在三個分區(三塊硬盤)同時讀,理論上說,速度會快三倍。
4、分區也可以減少索引層數。因為同一分區記錄數變少。
5、據說,好像如果硬盤做成RAID,會比分區表更好一些。
相关链接:
SQL Server 2005 中的分区表和索引
SQL Server 表分区注意事项