前期部署
1.JDK
2.上传HADOOP安装包
2.1官网:http://hadoop.apache.org/
2.2下载hadoop-2.6.1的这个tar.gz文件,官网:
https://archive.apache.org/dist/hadoop/common/hadoop-2.6.1/
下载成功后,把这个tar.gz包上传到服务器上,命令:
通过SecureCRT软件alt+p打开SFTP,然后把这个文件上传
上传成后,解压
tar -xvzf hadoop-2.6.1.tar.gz
然后把解压后的文件移动到/usr下,改名为hadoop
命令:
mv hadoop-2.6.1 /usr/hadoop

然后开始把hadoop的命令加到环境变量里面去
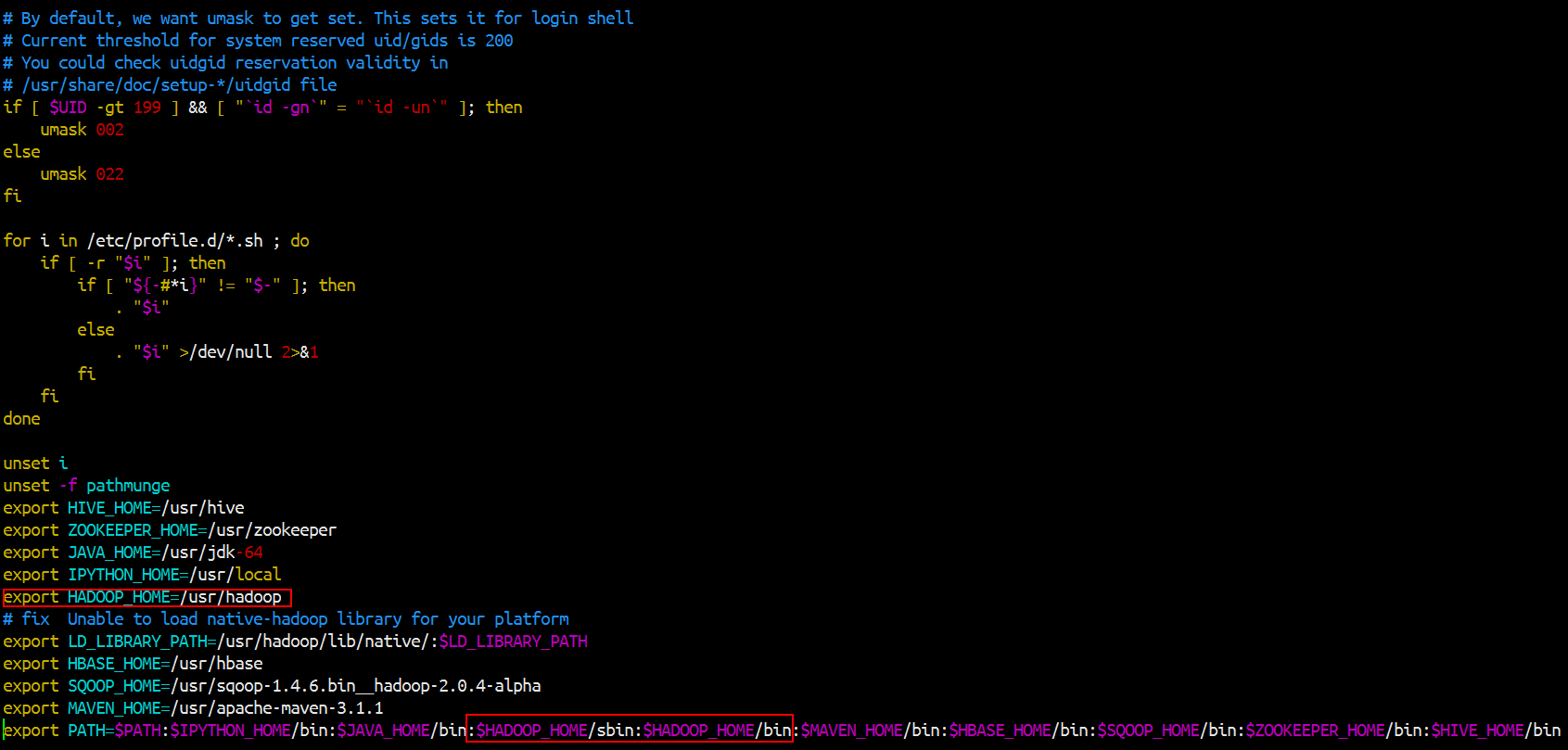
然后记得source一下
然后再修改配置文件,配置文件查看查看官网:
http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html
最简化配置如下:(在/usr/hadoop/etc/hadoop)
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-node-01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> //指定进程工作目录,数据存放目录 <value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value>
</property>
//设置保留副本的数量,即备份的数量,默认是3。客户端把文件交给fds之后,fds保留的副本数量 <property> <name>dfs.replication</name> <value>2</value> </property>
vim mapre-site.xml
mapreduce要放在一个资源调度平台上面跑,所以需要指定资源调度平台yarn,默认是local,不是在集群上运行
192.168.1.88 srv01 192.168.1.89 srv02 192.168.1.90 srv03
scp /etc/profile srv02:/etc/ //记得到srv02去source它的profile文件
scp /etc/profile srv03:/etc/ //记得到srv02去source它的profile文件
scp -R /usr/hadoop srv02:/usr/hadoop
scp -R /usr/hadoop srv03:/usr/hadoop
hadoop格式化是为了生成fsimage文件。
hdfs namenode -format

可以在浏览器上看到hadoop集群状态
namenode的ip加上50070端口
http://192.168.1.88:50070/
配置HDFS垃圾回收
fs.trash.interval
描述:检查点被删除的分钟数。如果为零,垃圾功能将被禁用。可以在服务器和客户端上配置此选项。如果垃圾桶被禁用服务器端,则客户端配置被检查。如果在服务器端启用垃圾箱,则使用服务器上配置的值,并忽略客户端配置值。
例子:7天后自动清理
<property>
<name>fs.trash.interval</name>
<value>7 * 24 * 60</value>
</property>
NameNode启动过程详解
namenode的数据存放在两个地方,一个是内存,一个是磁盘(edits,fsimage)
第一次启动HDFS
1.format : 格式化hdfs
2.make image : 生成image文件
3.start NameNode:read fsimage
4.start Datenode : datanode 向 NameNdoe 注册,汇报 block report ,
5.create dir /user/xxx/temp :写入edits文件
6.put files /user/xxx/tmp(*=site,xml) :写入edites文件
7.delete file /user/xxx/tmp/(core-site.xml):写入edits文件
对dfs的操作都会记录到edits里面
第二次启动hdfs:
1.启动NameNode,读取fsimage里面的镜像文件,读取edits文件,因为edits记录着上一次hdfs的操作,写入一个新的fsimage,创建一个新的edits记录操作
2.start Datenode : datanode 向 NameNdoe 注册,汇报 block report ,
3.create dir /user/xxx/temp :写入edits文件
4.put files /user/xxx/tmp(*=site,xml) :写入edites文件
5.delete file /user/xxx/tmp/(core-site.xml):写入edits文件
6.Secondly NameNode定期将edits文件和fsimage文件合并成一个新的fsimage文件替换掉NameNode上面的fsimage
另:手动编译hadoop记得要联网,因为它是用maven管理的,很多依赖需要下载