VisualPytorch beta发布了!
功能概述:通过可视化拖拽网络层方式搭建模型,可选择不同数据集、损失函数、优化器生成可运行pytorch代码
扩展功能:1. 模型搭建支持模块的嵌套;2. 模型市场中能共享及克隆模型;3. 模型推理助你直观的感受神经网络在语义分割、目标探测上的威力;4.添加图像增强、快速入门、参数弹窗等辅助性功能
修复缺陷:1.大幅改进UI界面,提升用户体验;2.修改注销不跳转、图片丢失等已知缺陷;3.实现双服务器访问,缓解访问压力
访问地址:http://visualpytorch.top/static 或 http://114.115.148.27/static
发布声明详见:https://www.cnblogs.com/NAG2020/p/13030602.html
一、Dataloader与Dataset
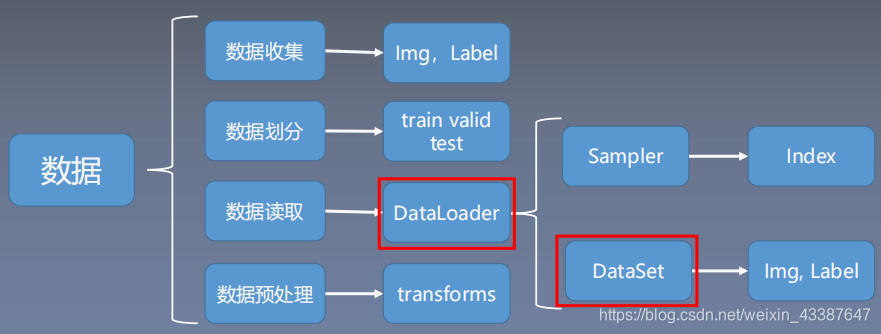
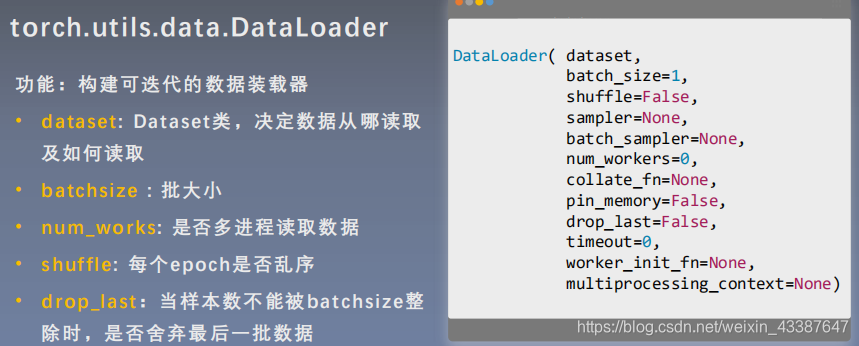
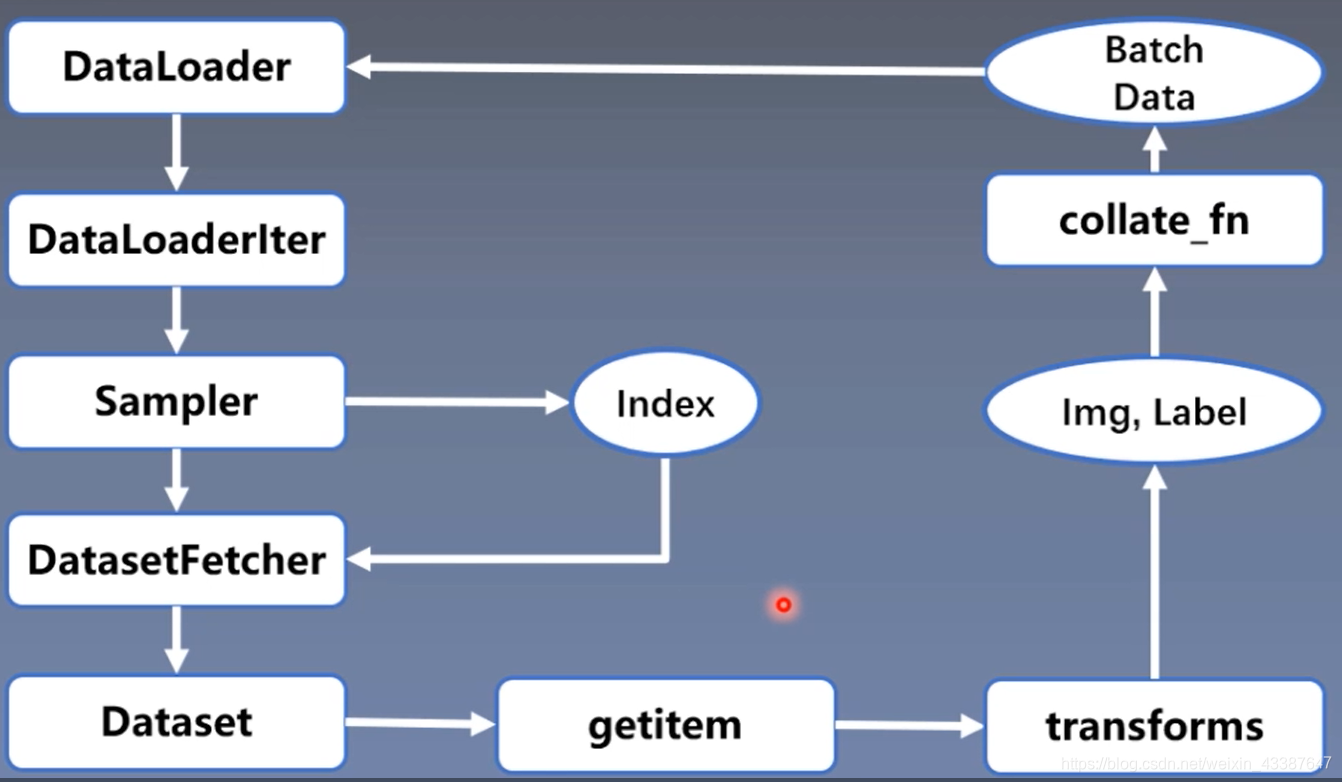
1. DataLoader
Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
Iteration:一批样本输入到模型中,称之为一个Iteration
Batchsize:批大小,决定一个Epoch有多少个Iteration
样本总数:87, Batchsize:8
1 Epoch = 10 Iteration ? drop_last = True
1 Epoch = 11 Iteration ? drop_last = False
2. Dataset

人民币二分类为例:将RMB_data按照8:1:1分为train, test, valid三组,构建Dataset类
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
实例化Dataset与DataLoader:
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # 每一个epoch样本顺序不同
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)


二、图像预处理——transform

torchvision.transforms : 常用的图像预处理方法
- 数据中心化
- 数据标准化
- 缩放
- 裁剪
- 旋转
- 翻转
- 填充
- 噪声添加
- 灰度变换
- 线性变换
- 仿射变换
- 亮度、饱和度及对比度变换
图像增强:丰富数据集,提高模型的泛化能力
# 对图像进行有序的组合与包装
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std), # 标准化
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)), # 验证时不需要进行图像增强
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])

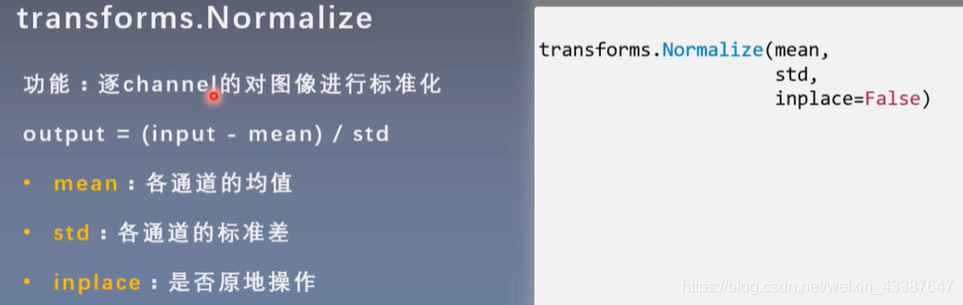
进行标准化能加快模型的收敛!
三、transform图像增强(一)
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力.


1. 裁剪
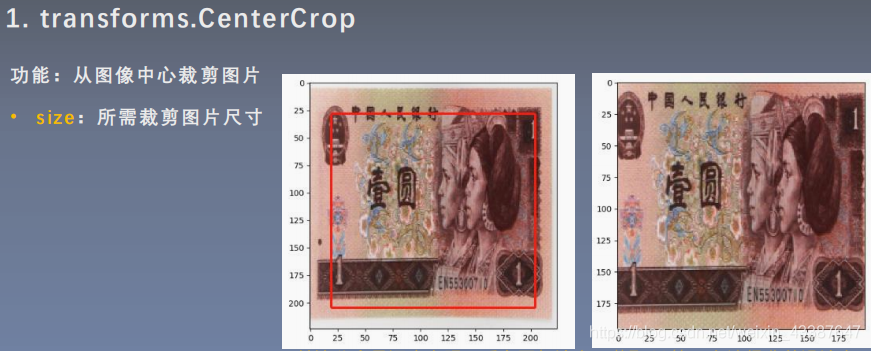

- padding_mode:填充模式,有4种模式
- 1、constant:像素值由fill设定
- 2、edge:像素值由图像边缘像素决定
- 3、reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4] → [3,2,1,2,3,4,3,2]
- 4、symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4] → [2,1,1,2,3,4,4,3]
- fill:constant时,设置填充的像素值
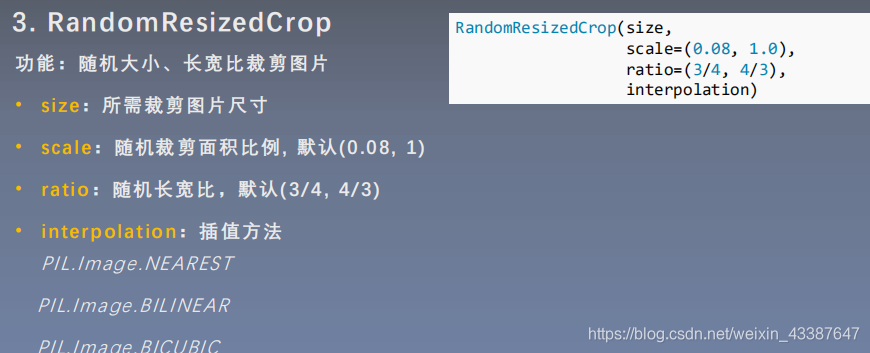
2. 翻转和旋转


center=(0,0) # 左上角旋转
expand仅针对center,没办法找回左上角旋转丢失的信息
四、transform图像增强(二)
1. 图像变换

padding_mode为镜像时,fill不起作用
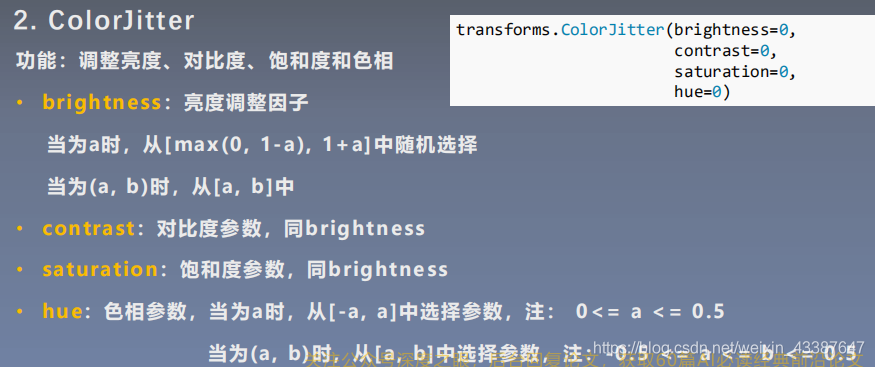



直接在tensor上进行操作:
transforms.ToTensor()
transforms.RandomErasing(p=1, scale=(0.02,0.33), ratio=(0.5,1), value=(254/255,0,0))
其中value只要是字符串,随机色彩
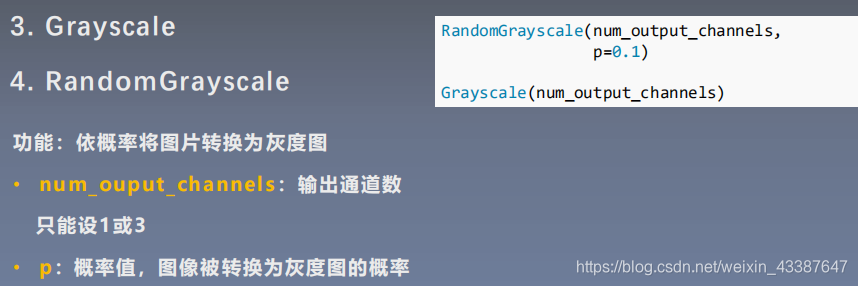
2. transform操作

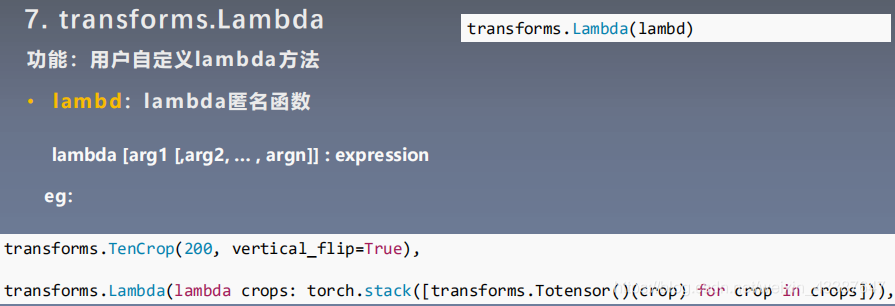
3. 自定义transform
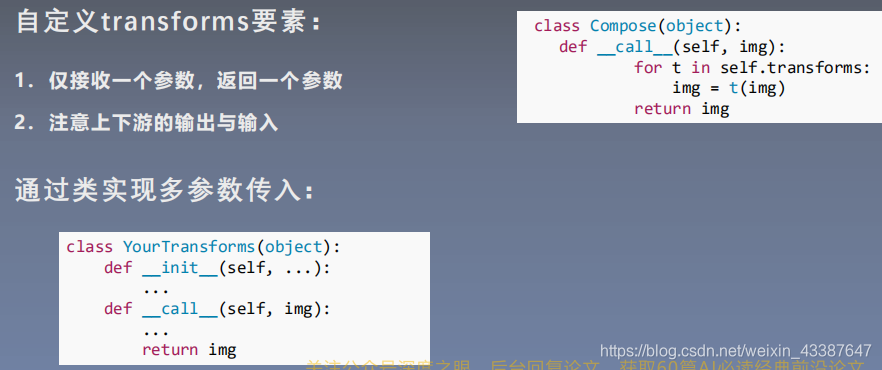
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) or (isinstance(p, float))
self.snr = snr
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
if random.uniform(0, 1) < self.p:
img_ = np.array(img).copy()
h, w, c = img_.shape
signal_pct = self.snr
noise_pct = (1 - self.snr)
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声:白
img_[mask == 2] = 0 # 椒噪声:黑
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img
4. 实战
原则:让训练集与测试集更接近
- 空间位置:平移
- 色彩:灰度图,色彩抖动
- 形状:仿射变换
- 上下文场景:遮挡,填充
- ......



分析原图,主要是色相的问题,将输入图片直接转为灰度图
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=1),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
源代码:
# -*- coding: utf-8 -*-
"""
# @file name : RMB_data_augmentation.py
# @author : tingsongyu
# @date : 2019-09-16 10:08:00
# @brief : 人民币分类模型数据增强实验
"""
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import transform_invert
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=1),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomGrayscale(p=1),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
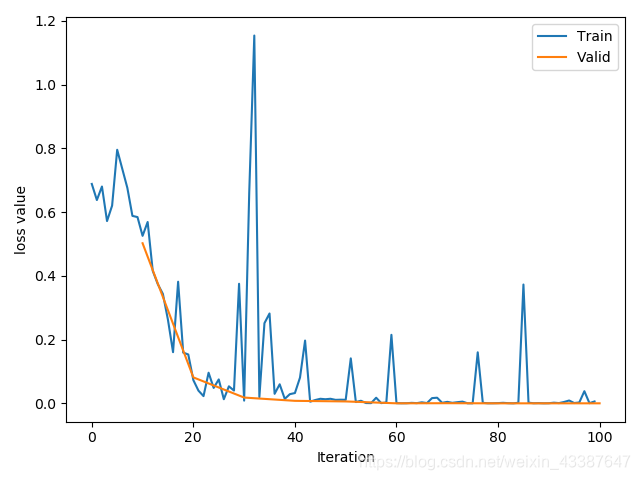
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val)
print("Valid: Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
img_tensor = inputs[0, ...] # C H W
img = transform_invert(img_tensor, train_transform)
plt.imshow(img)
plt.title("LeNet got {} Yuan".format(rmb))
plt.show()
plt.pause(0.5)
plt.close()