一、生成器的几个特点
1、含有yield关键字的函数都是生成器函数。
2、yield和return不能共存。
3、return一般一个函数中只有一个,它会将函数终止,并返回一个值给调用函数的地方。
4、yield在一个函数中可以有多个,它不会终止函数,下次还可以接着从离开它的地方继续执行。使用next()或者__next__()可以获取到yield的生成的元素。
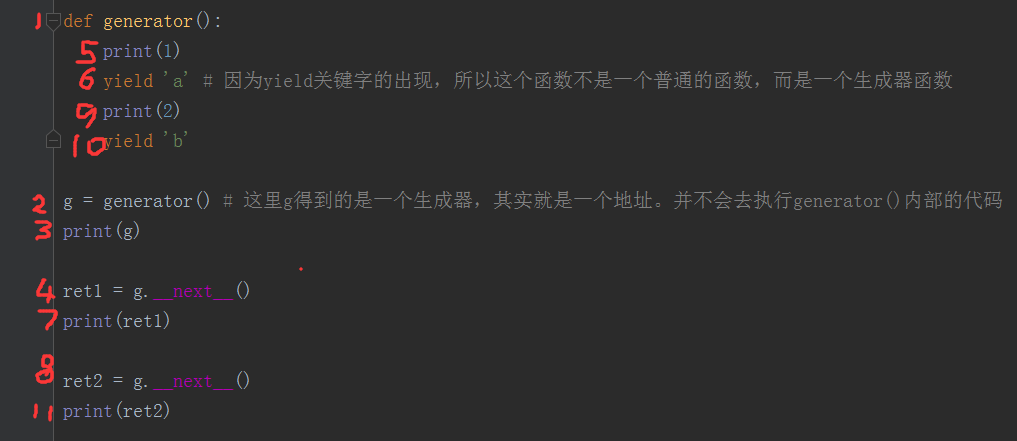
5、生成器函数被调用后,会返回一个生成器。调用时,并不会执行生成器函数内部的代码,如下图,在调用next(g)或者g.__next__()方法的时候才会执行函数内部的代码,遇到yield关键字就不再继续往下执行了。
6、使用生成器的好处就是,可以避免一下子在内存中产生过多的数据,只是在我们需要的时候生成一部分数据就可以了。
7、yield和next是一一对应的,如果next超过了yield的数量,程序就会报错。
1 def produce(): 2 """生产衣服""" 3 for i in range(2000000): 4 yield "生产了第%s件衣服"%i 5 6 product_g = produce() 7 print(product_g.__next__()) #要一件衣服 8 print(product_g.__next__()) #再要一件衣服 9 print(product_g.__next__()) #再要一件衣服 10 num = 0 11 for i in product_g: #要一批衣服,比如5件 12 print(i) 13 num +=1 14 if num == 5: 15 break 16 17 # 运行结果: 18 生产了第0件衣服 19 生产了第1件衣服 20 生产了第2件衣服 21 生产了第3件衣服 22 生产了第4件衣服 23 生产了第5件衣服 24 生产了第6件衣服 25 生产了第7件衣服
二、举例:
公司要做市场推广,需要印刷2,000,000本宣传册,单价15元。可以一次性拿出3000万让印刷厂全部印出来,搬回来找个地方放着,每次推广活动的时候拿一点发出去。
1 def book(): 2 l = [] 3 for i in range(1,2000000): 4 l.append('第%s本宣传册'%i) 5 return l 6 7 book = book() 8 print(book)
这样显然不合理,从经济上讲,不可能一次性拿出3000万去印刷宣传册。从程序设计上讲,一次性生成一个2000000个元素的列表,会占用很大的内存,运行效率低。
如果能跟印刷厂签个合同,比如说2年内购买2000000册,2年内有推广活动时就让印刷厂印出一少部分,这样就完美了。
1 def book(): 2 for i in range(1,2000000): 3 yield '第%s本宣传册'%i 4 5 g = book() 6 print(next(g)) 7 print(next(g)) 8 print(g.__next__()) 9 print(g.__next__()) 10 print(next(g)) 11 12 for i in range(50): 13 print(next(g)) 14 15 for i in range(100): 16 print(g.__next__())
三、send
1、send和next的效果一样,都能获取到yield返回的值。
2、send在获取下一个yield的返回值的同时,给上一个yield的位置传递一个数据。
3、第一次使用生成器的时候,必须使用next回去yield的返回值。
4、最后一个yield不能接收外部传递的值。
def generator(): print(123) ret1 = yield 'aaa' print(ret1) print(456) ret2 = yield 'bbb' print(ret2) g = generator() print(g.__next__()) print(g.send('我是send传过来的值')) # send将值传给了第一个yield # print(g.__next__()) # 这个地方会报错StopIteration,因为前面有一个__next__和一个send了,generator生成器里面只有两个yield
四、举例
1、获取移动平均值
def average(): sum = 0 count = 0 avg = 0 while True: num = yield avg sum += num count += 1 avg = sum / count g = average() g.__next__() ret = g.send(10) print(ret) ret = g.send(20) print(ret)
执行过程:

优化后的生成器,使用装饰器与激活生成器,在调用的时候直接使用send,不用在send之前调用__next__激活生成器了。
def init(func): def inner(*args,**kwargs): g = func(*args,**kwargs) g.__next__() return g return inner @init def average(): sum = 0 count = 0 avg = 0 while True: num = yield avg sum += num count += 1 avg = sum / count g = average() ret = g.send(10) print(ret) ret = g.send(20) print(ret)
执行过程:

五、yield from
def gen(): s = 'abcd' for i in s: yield i for j in range(4): yield j g = gen() for i in g: print(i)
def gen(): s = 'abcd' yield from s yield from range(4) g = gen() for i in g: print(i)
六、列表推导式
# 列表循环 l = [] for i in range(5): l.append('鸡蛋%s'%i) print(l) # ['鸡蛋0', '鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4'] # 列表推导式 print(['鸡蛋%s'%i for i in range(5)]) # ['鸡蛋0', '鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4']
# 列表循环 s = 0 for i in range(5): s += i**2 print(s) # 列表推导式 print(sum([i**2 for i in range(5)]))
七、生成器表达式
和列表推导式相比,只要把列表推导式中的[]换成()就变成一个生成器表达式。
print(x for x in range(5)) # <generator object <genexpr> at 0x009943B0> print(sum(x for x in range(5))) # 10
# 注意:这两个东西的返回值,第一个输出的是生成器,第二个输出的是sum的结果
八、各种推导式
1、列表推导式
print([i for i in range(31) if i%3 == 0]) print([i*i for i in range(31) if i%3 == 0])
2、字典推导式
# key和value互换 dic = {'a':10, 'b':20} print({dic[item]:item for item in dic}) # {10: 'a', 20: 'b'} # 将key相同的value值合并(忽略key的大小写),并将key都改成小写 dic = {'a':10, 'b':20, 'A':30, 'B':40} ret = {k.lower():dic.get(k.lower(),0) + dic.get(k.upper(),0) for k in dic} print(ret) # {'a': 40, 'b': 60}
3、集合推导式
print({i**2 for i in [1,-1,2,-2,4]}) # {16, 1, 4}
九、面试题
面试题一:
def demo(): for i in range(4): yield i g=demo() g1=(i for i in g) # 这一句在list(g1)在执行时才会被调用 g2=(i for i in g1) # 这一句在list(g2)在执行时才会被调用 print(list(g1)) # [0, 1, 2, 3] print(list(g2)) # [] 结果解析: 为什么是这个运行结果? 生成器有一个特点,那就是如果生成器里面的值被取完了,再取就取不到了。 在上面的题目中,g1=(i for i in g)和g2=(i for i in g1)在开始的时候并没有执行,只有在执行到list(g1)和list(g2)的时候才会执行。因为生成器表达式和生成器函数一样只返回一个生成器,并不会执行里面的代码。 在执行list(g1)的时候,会强制将生成器g1的值转换成list,g1又会从生成器g中取值。所以list(g1)执行后,生成器g1里面的值已经被全部取出来了。 在执行list(g2)的时候,会强制将生成器g2的得转换成list,g2这时会从g1去取值,因为g1里面的值已经在前面被取完了,所以list(g2)就取不到任何值了。 如果将print(list(g1))这一段代码注释掉,print(list(g2))就会能取到值,返回[0, 1, 2, 3]
面试题二:
def add(n,i): return n+i def test(): for i in range(4): yield i g=test() for n in [1,10]: g=(add(n,i) for i in g) ret = list(g) print(ret) # [20, 21, 22, 23] # 上面的程序似乎看不明白,可以把上面的for循环拆开来看就比较容易了,如下: def add(n,i): return n+i def test(): for i in range(4): yield i g=test() n = 1 g=(add(n,i) for i in g) n = 10 g=(add(n,i) for i in g) # 到这里为止,上面的代码都不会执行,在list(g)被执行的时候才会去从生成器g中取值 ret = list(g) print(ret) # [20, 21, 22, 23]
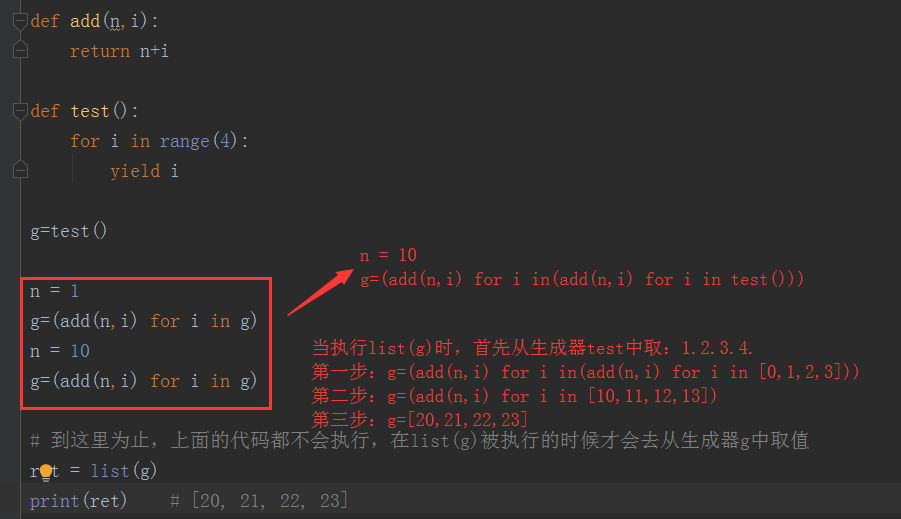
思考下面的题目,为什么输出的是:[15, 16, 17, 18]
提示,将for循环也拆开来看
def add(n,i): return n+i def test(): for i in range(4): yield i g=test() for n in [1,10,5]: g=(add(n,i) for i in g) ret = list(g) print(ret) # [15, 16, 17, 18]