Seq2Seq

seq2seq,从一个句子翻译到另外一个句子。
封面是一个基因转录,这个也是一个seq2seq的过程。

seq2seq最早是来做机器翻译的,不过现在基本都使用bert。(听说google的翻译和搜索都使用了bert)

seq2seq是一个encoder-decoder的架构。
- encoder是一个RNN,读取输入句子(可以是双向的)
encoder就是给一个句子,比如"hello world",然后需要翻译成法语的句子。
把最后时刻的隐藏状态传递给解码器,可以认为最后时刻的隐藏状态包含了整个句子的信息。
encoder的RNN可以是双向的,双向的RNN可以做encoder,但是不能做decoder。encoder是不需要预测的,所以可以看到完整的句子,可以正着看,反着看,encoder经常会使用双向RNN。
- decoder使用另外一个RNN来输出
隐藏状态一过来,先给一个<bos>说明句子开始了,然后把上一个时刻的翻译做为下一个时刻的输入,当然隐藏状态也是向下传递。这样对长度是可以变化的,知道输出<eos>才结束预测,这样就不管源句子有多长,target句子有多长,不用关系如何让二者的长度一样,就按照时刻往前走,走到停为止。
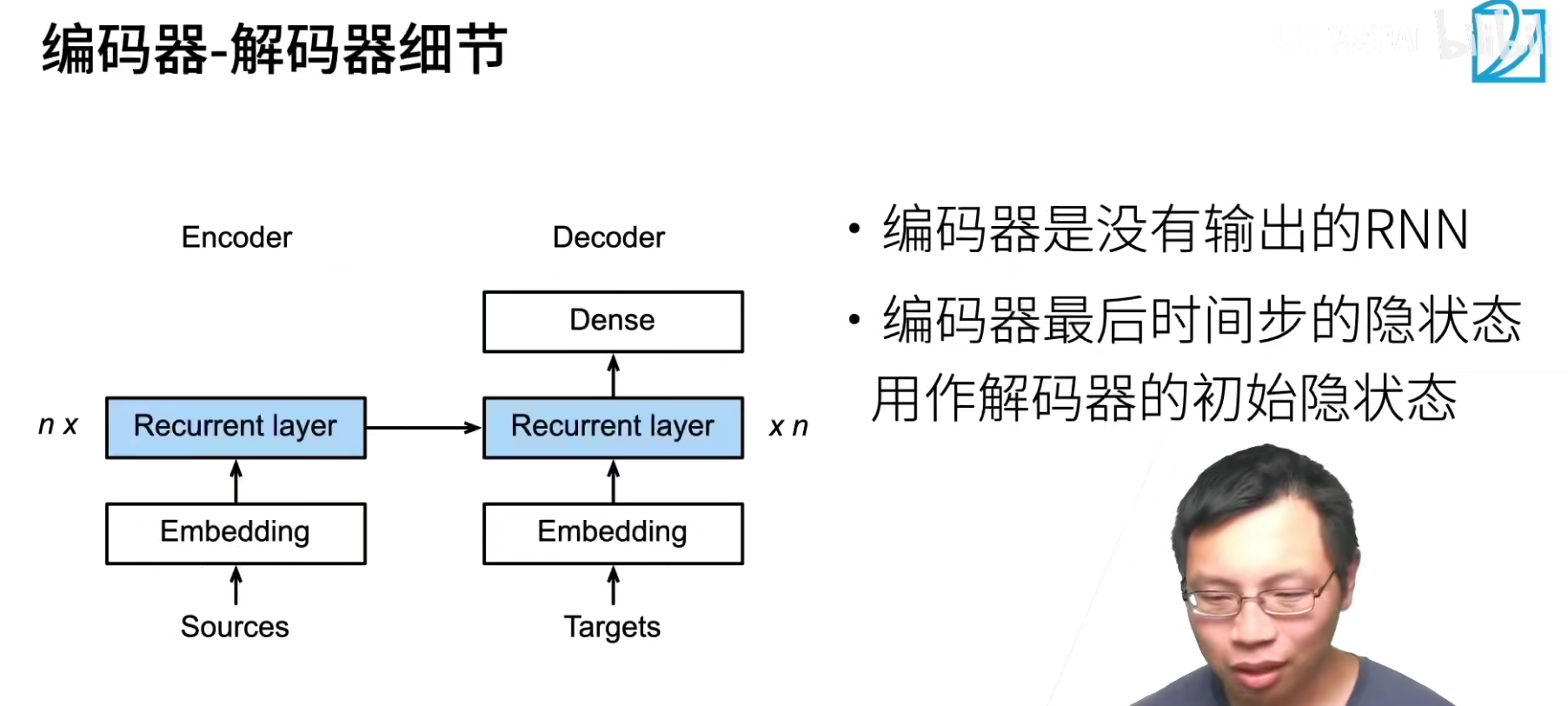
encoder最后一层的最后时刻的输出,将放到和decoder的input一起输入。

训练:
decoder在训练的时候是知道真正的目标句子的,就是正常的进行RNN的训练。(这里是没有利用上一时间刻的预测结果的
推理:
因为没有正确的答案,所以只能不断利用上一时刻预测的结果作为下一个时刻的输入,不断地向前预测。
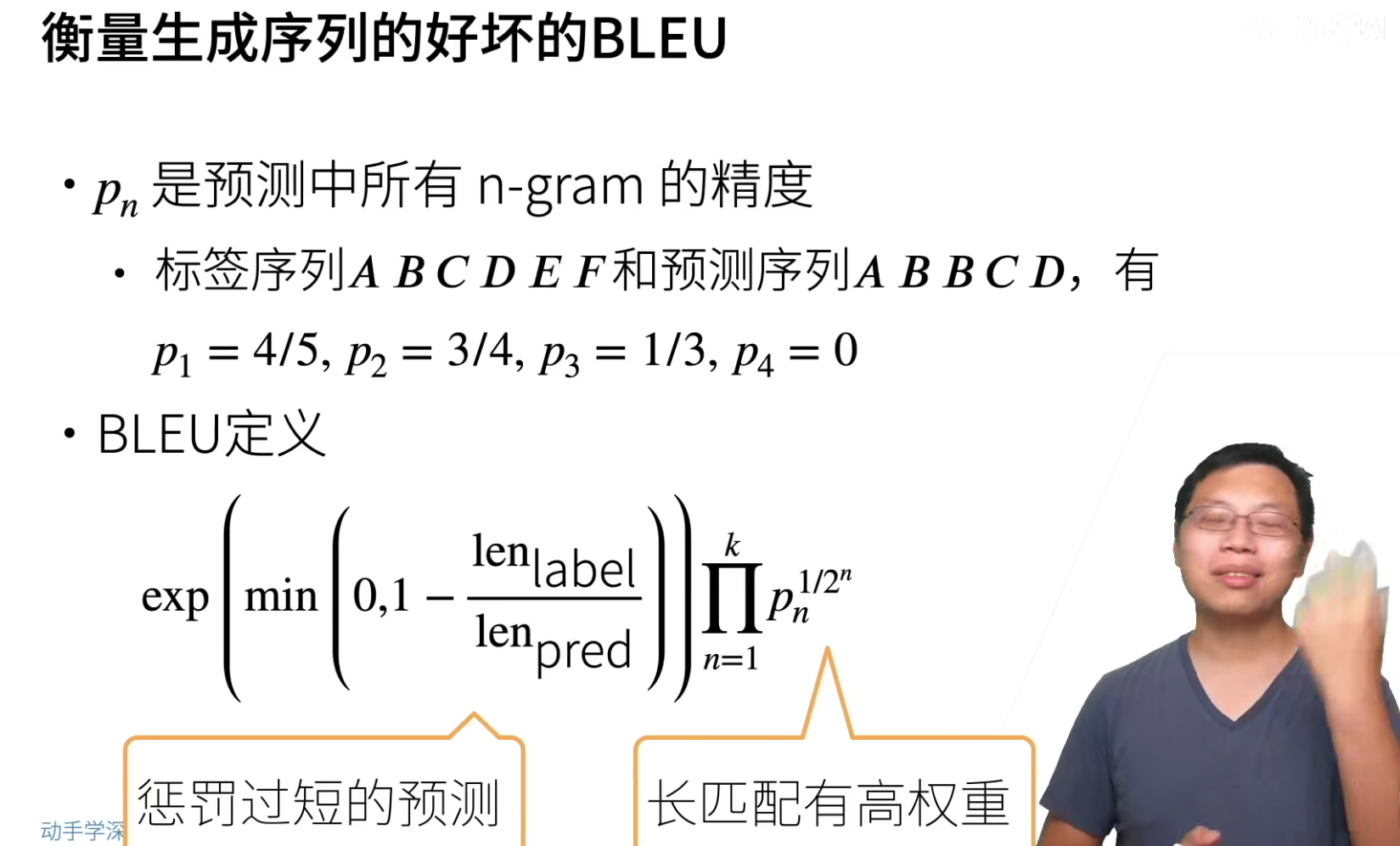
BLEU完美是1,然后越小越差。
如果label很短,但是pred很长,这样会命中很多,所以要进行惩罚(min(0,1-frac{len_{label}}{len_{pred}} ))

代码


QA
- encoder输出和decoder输入,concat和按位相加起来有什么区别吗?
它们可能长度不一样,所以是不能相加的,这里只要保证他们的隐藏单元数量相同(列宽相同),就可以进行拼接操作。
- embedding层是word2vec吗?
不是的,而且现在也不打算将word2vec,因为现在也用的很少,现在基本都是用bert。
而且演示代码中也没有使用预训练的embedding,这里是是随机初始化,然后重头开始训练的。
- vaild_length是怎么选择的?
vaild_len不是选择,就是实际的法语句子有多长,要把vaild_len存下来,后面计算loss的时候,valid_len后面的padding的mask都是不要计算的。
- 现在seq2seq好像都用transformer实现了,RNN,LSTM还有什么使用场景吗?
现在是潮流,说用transformer不用RNN了,但是可能过几个月大家又说RNN好。
深度学习就是一波又一波...
- 实际句子的长度超过了设定的句子长度,是直接截掉不用了还是放到下一个句子?
是直接截掉不用,不能放到下一个句子。
所以要选一个差不多的长度,不要截取掉太多。