RNN从零开始实现

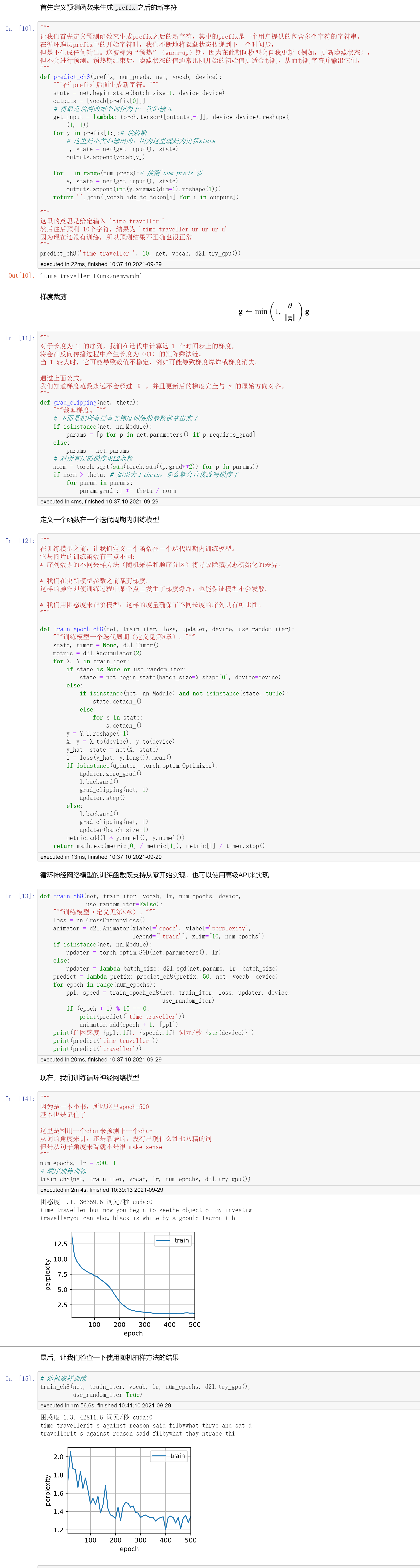
简洁实现

QA
- num_step是做什么用的?
就是那个T,那个时间维度。
比如下面"你好,世界!",输入这个句子有6个字符,那么这里的num_step/T=6。反过来可以认为这是一个6个样本的分类问题,就是每一个词都是要进行下一个词的预测。这是一个多分类问题,T=6,所以要做到6次分类。所以可以等价于一个6个样本的MLP。
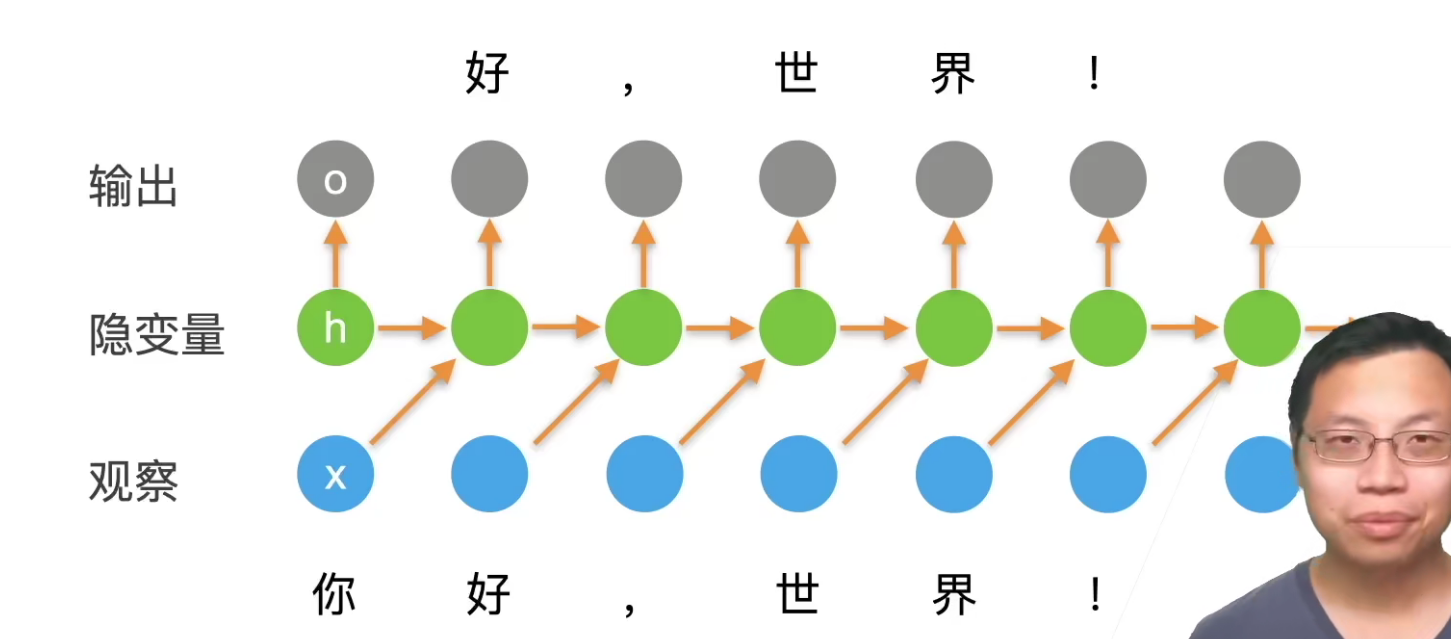
- H是一个batch更新一次吗?看刚刚的diamanteH好像是每个batch会覆盖一次,但是H难道不是应该每个step都在变化吗?
应该说一个句子,时间长度为T,那么H会被更新T次。
只是说根据当前采样的不一样,当前这个batch的H要不要丢给下一个batch,如果是接在一起的,那么久可以进行传递。
- batch_size=1是指一个文本吗?
是的,就是输出的时候只输入了一个句子。
- batch_size和time的区别是什么?
time:句子的长度
batch_size:一个batch有几个句子(可以认为是优化算法的东西)
- 预测这段代码里对于prefix的处理好像是直接放到output里,没有把他拿过来再做训练。是不是可以把prefit也用起来,训练一下会比较好?
一般为什么不这么做呢?预测的时候都不会说要进行模型的更新。
当年微软的小冰会说脏话,也是因为使用了用户数据来训练模型。模型上线了,是不可以随意再修改的。
- num_step可以理解为隐藏的层数吗?
不是的,从模型角度,num_step就是T。但是反向传播的时候,可以这么认为,因为后一个词的预测是依赖于前面的所有“积累”。
- 关于num_step的取值?
RNN并不能处理很长的序列,35一般都算不错了。
后面会将LSTM如果处理更长的序列,还有transformer可以处理更加长的序列。
- 批量随不随机取,应该要看批量之间有没有时间关联吧?要有关联就不能随机取吧?
不是的,RNN一般都是随机取的,如果太有关联的话,就容易overfitting。随机性可以让模型不那么容易overfitting。
还有一个就是,其实batch之间有关联是好事,但是RNN是不足以去记住全部的隐变量。
- 为什么是预测字符而不是预测单词呢?
因为简单。用字符预测的话,vocab大小只有28,但是如果用单词的话,那么大小至少都是上千的。
我们这个文本就几千个词,文本太小了。几千个词要做几千个分类是做不了的。
- RNN处理不了长序列的原因是?
RNN的序列信息是通过隐变量来进行存储的,隐变量的长度就那么多(参数太多,数据太多,脑容量不够)是很难将全部时序信息给记住的。