语言模型
一只猴子打字,就算是打到宇宙毁灭,他也打不出莎士比亚的文章。


语言模型的核心是估计联合概率(p(x_1,...,x_t)),序列模型的核心其实也就是预测整个文本序列出现的概率。

我们使用一个最简单的计数模型来进行建模。

一元只有一个变量,也就是自己,那么就可以认为每个变量都是独立的..


这是一个很现实的问题,就是序列太长不能被一次读入内存中应该如何处理?
两种方式:随机采样 & 顺序分区
随机采样就是随机丢弃前面k个数据,k属于([0,num_step-1])。
随机采样的话,每一个batch的子序列之间都可以认为是独立的。

随机采样的话,相邻的两个batch的子序列是连续的。
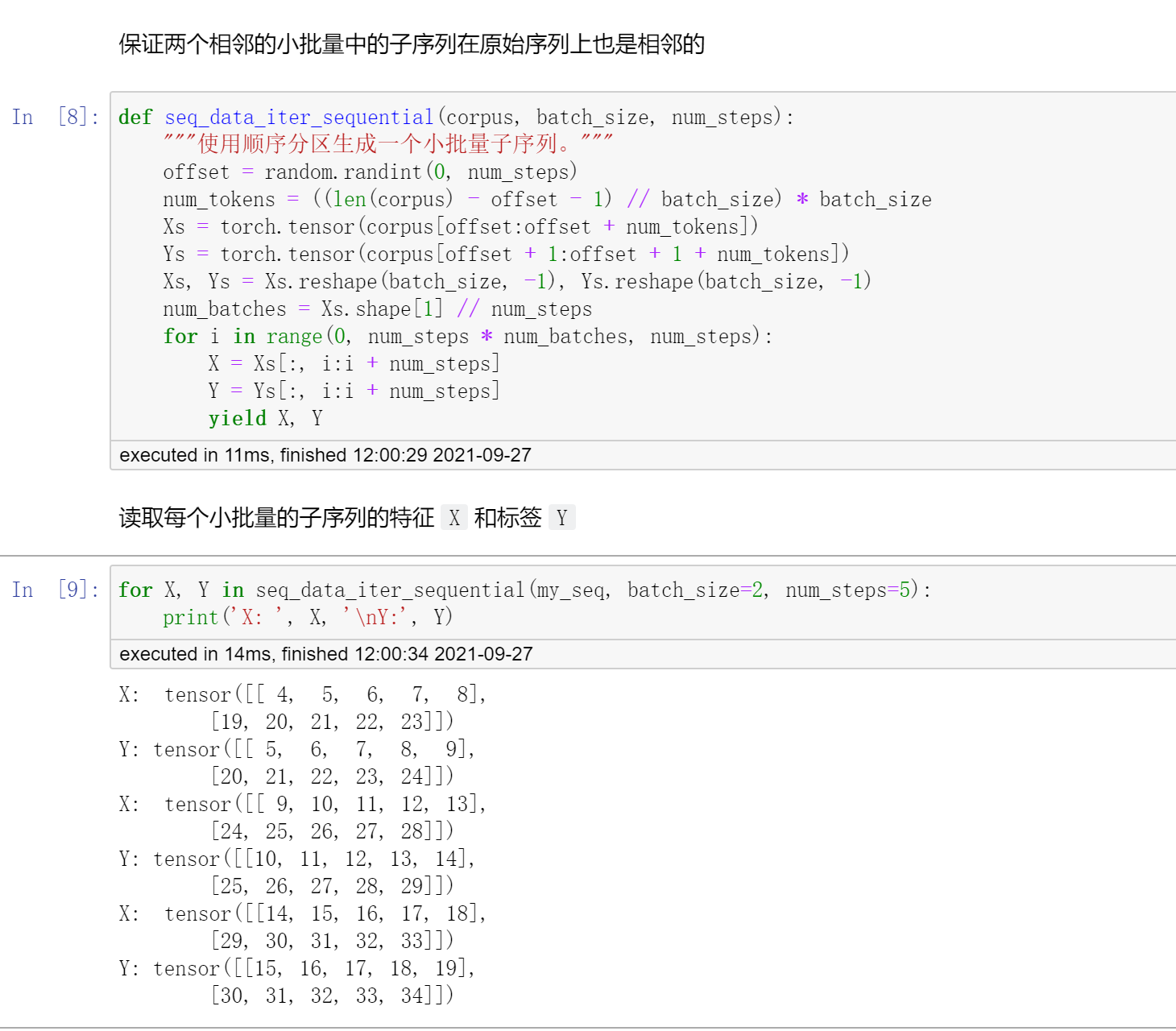

代码
代码展示的是时序序列的语言模型是如何读取数据以及生成mini_batch的。

QA
- 在文本预处理中,所构建的词汇表把文本映射成数字,文本数据量越大,映射的数字也就越大,这些数字还需要做预处理吗?例如归一化处理等,是否模型有影响?
这些数字使用做成embedding层用的,它不会真的作为一个数字传给RNN模型,这些数字在这些地方只是一个id,后面会具体介绍这些数字具体是如何使用的。
- 语言sequence sample(token是word)的时间跨度T大概设成多少比较好?如果是中文的话一般又是多少?
这个东西取决于你一句话有多长,取决于你是想对一句话建模还是对一段话建模。这个T取16,32,64,128,长一点512也是有的。沐神认为32是一个不错的选项,当然越长计算量越大,收敛也会变得慢,当然不是所有模型都能够去处理很长的序列。