AlexNet
AlexNet从2012年开始到今天,真正的引爆了深度学习的热潮。

2000年之前,最火的机器学习方法应该是核方法。
特征提取 & 选择核函数来计算相关性 & 凸优化问题 & 漂亮的定理。
使用核方法,可以变换这个空间,将这个空间拉成我们想要的样子,通过核函数计算之后就会成为一个凸优化问题。因为是凸优化,所以有比较好的数学定理。核方法最大的特色就是有一套完整的数学定理,这也是最优美的地方。
当然现在SVM还是被很广泛使用,因为它不需要调参(应该说SVM对调参不那么敏感),通常大家闭着眼睛用SVM一点问题也没有。


10年前,机器学习最重要的步骤是特征工程,也就是如何进行特征的抽取。
在深度学习之前,大家不会太关心使用的机器学习是什么(基本默认是SVM),大家关心的都是如何进行特征的抽取。

看对比,数据的增长大概是1000倍,计算的增长是10000倍,也就是其实现在计算的增长速度是大于数据的增长速度的。
不同的数据大小,计算能力也对应不同机器学习方法的发展。
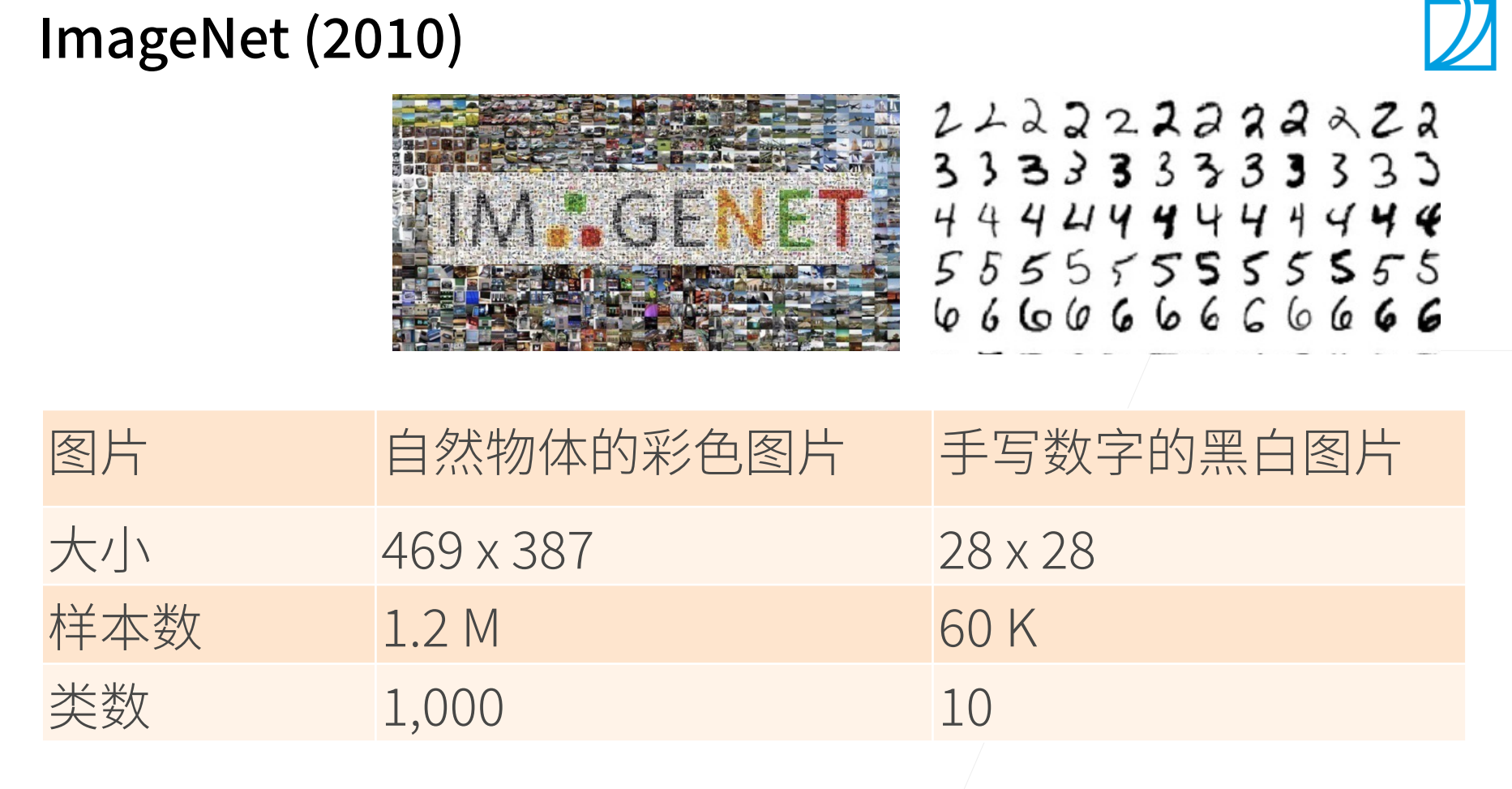
数据是一个非常重要的事情,这次深度学习能够起来,首先数据起到非常重要的作用。
因为有足够的大的数据集,所以允许更深的神经网络来进行特征的抽取。
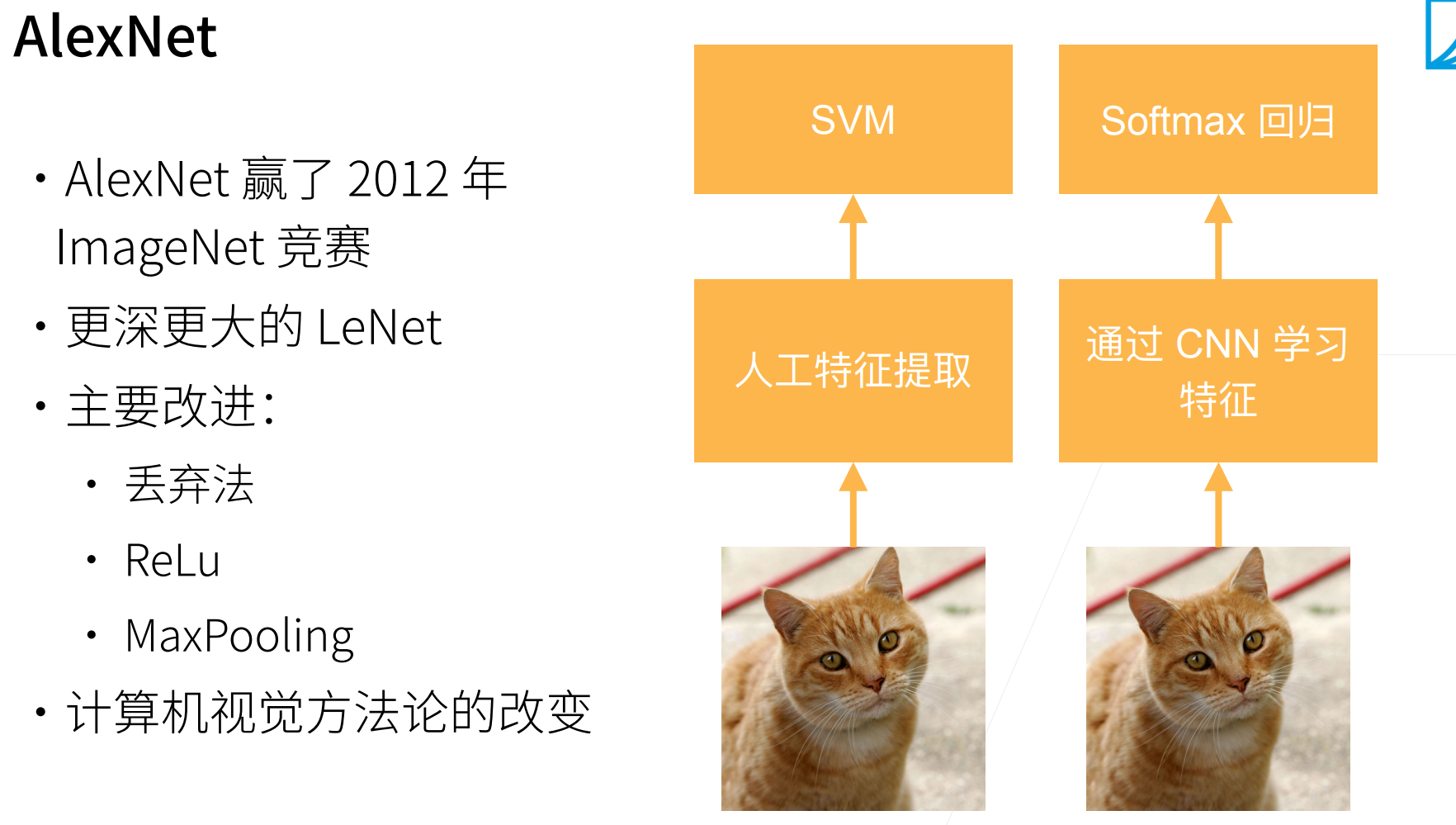
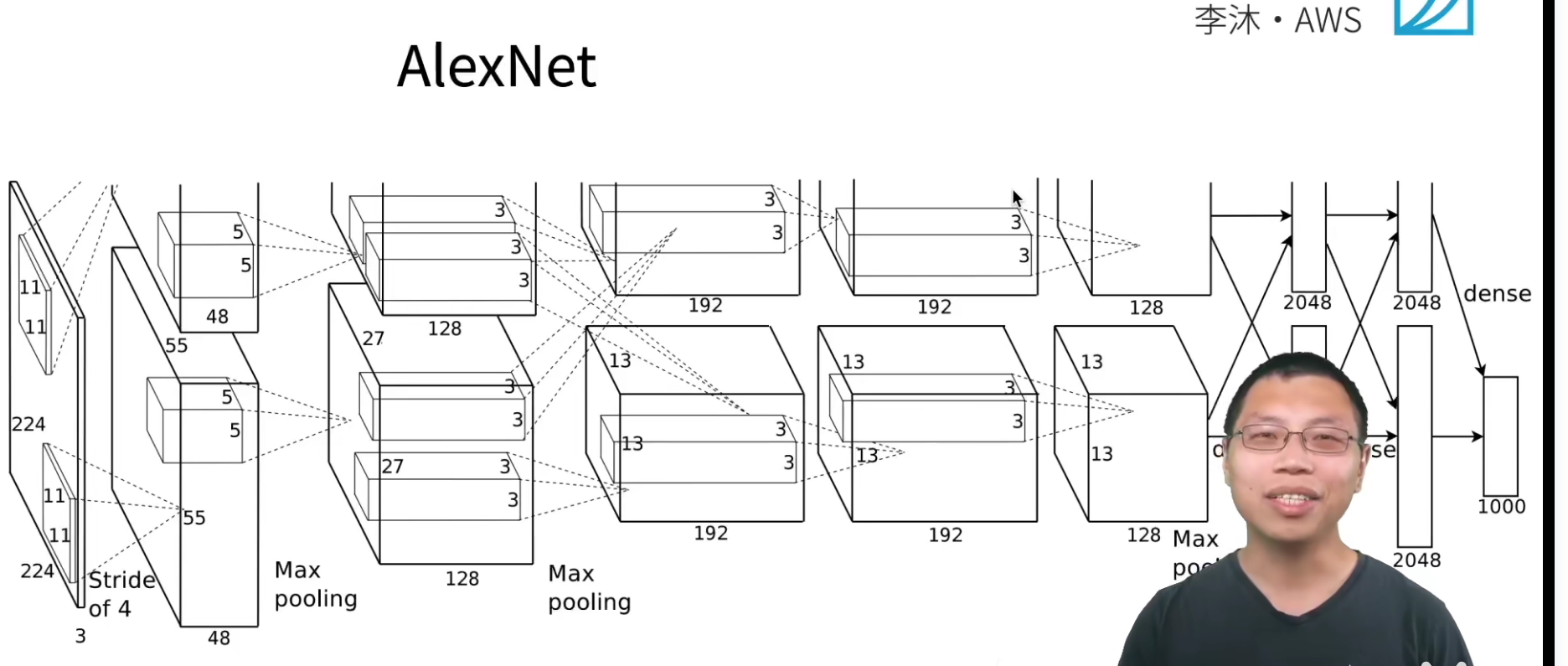
AlexNet本质就是一个更深更大的LeNet,它和LeNet没有本质的差别。
主要改进:dropout & ReLU & MaxPooling
MaxPooling 让输出更大,也就是让梯度更大,更加好的进行训练。
dropout控制了模型的大小。
ReLU是更好的,计算的更快的激活函数。
要清楚,传统的机器学习,对数学的要求,特征提取(要求对计算机视觉、时序数据)都有一个比较深的理解,而深度学习只要能够搭建模型即可。
深度学习可以看作是一个端到端的输出,也就是原始的数据输入到最终的答案输出,其实中间可以看作是一个黑盒。

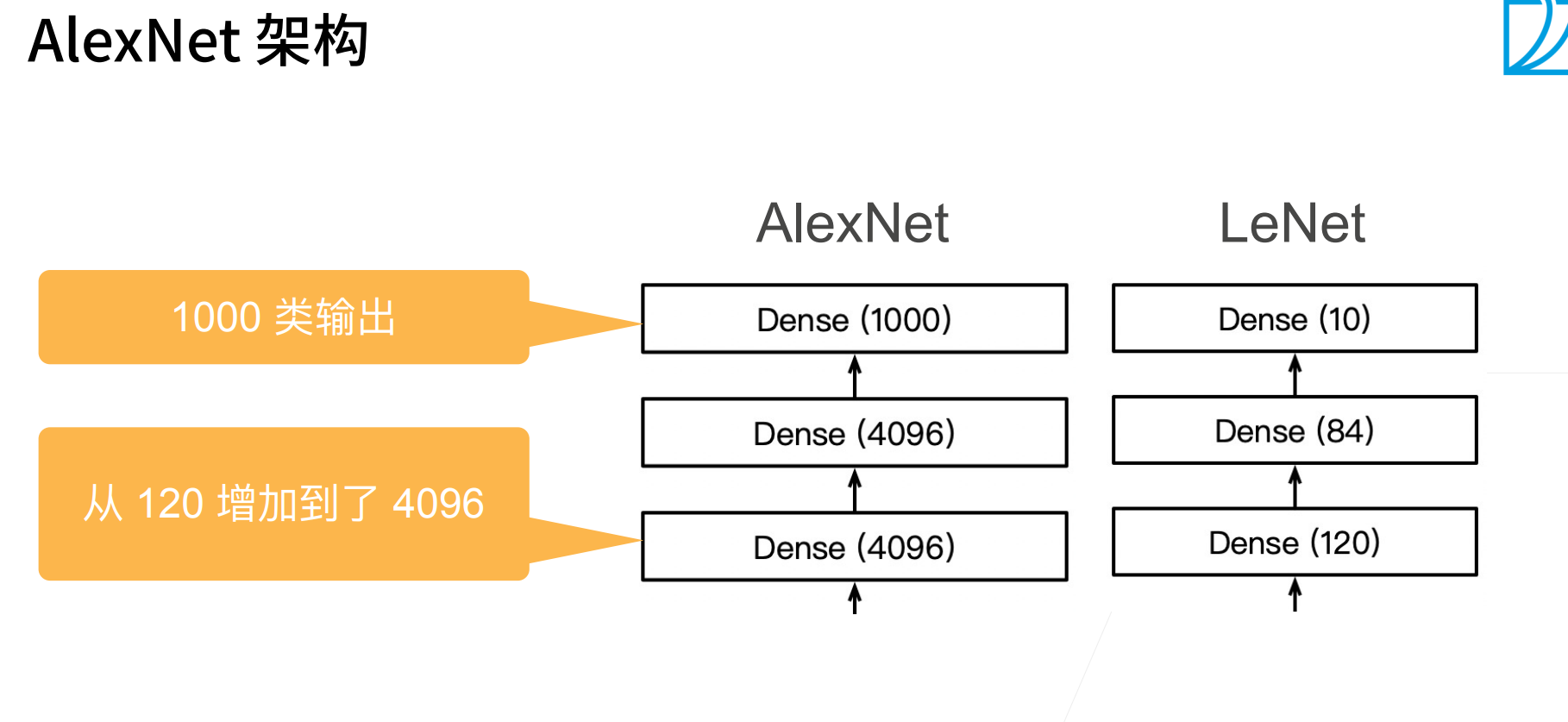
AlexNet其实就是一个更深、更大的LeNet。
AlexNet的stride=4,其实也是受限于当时的GPU计算性能,当初的GPU显存也只有2G,计算能力也没有现在那么好。
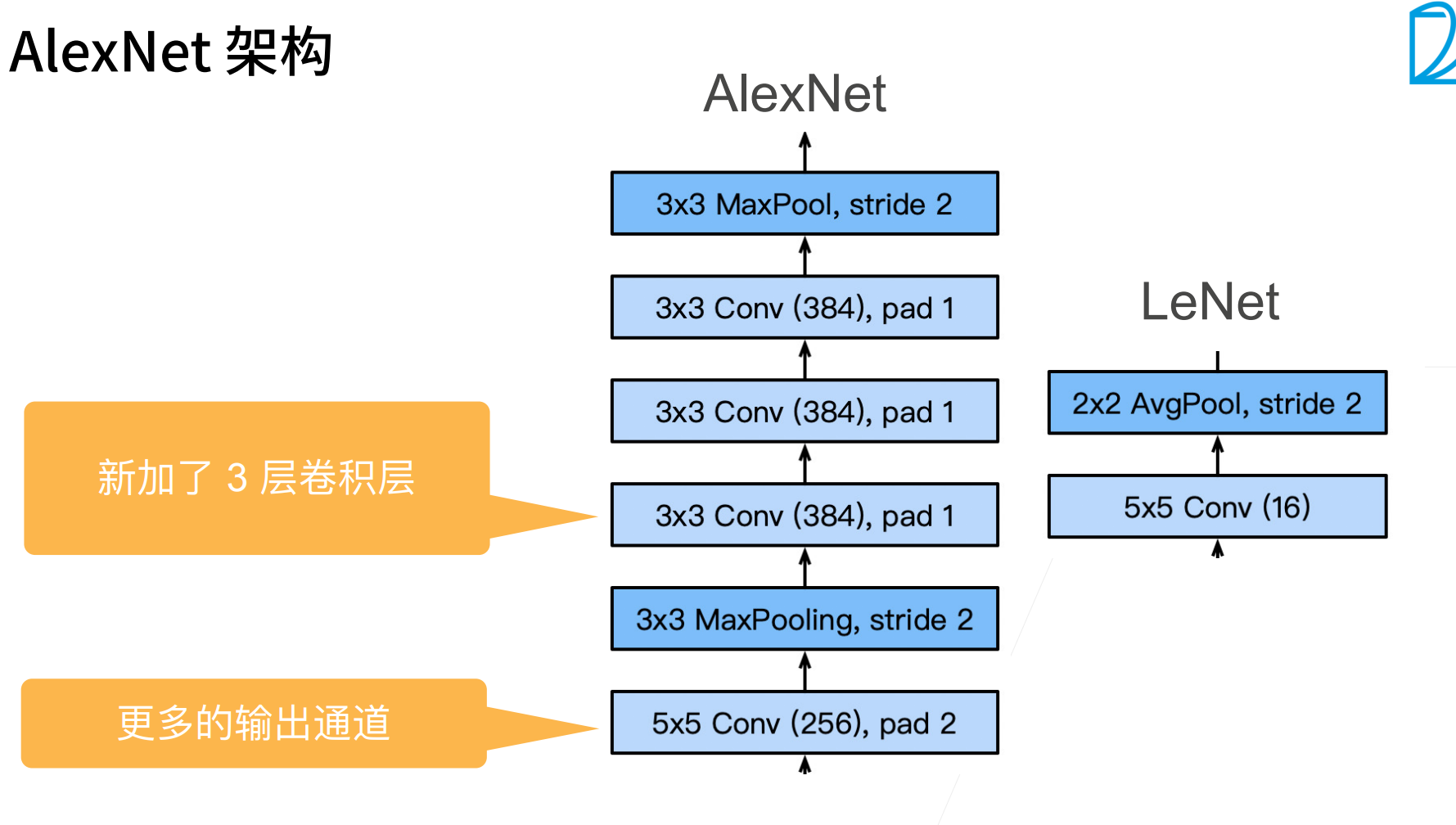
AlexNet的输出通道相对于LeNet的输出通道更多,也就意味着识别了更多的模式。

这里非常重要的是进行了数据增强,就是它觉得1,2M张图片还不够多,对图片进行随机截取,亮度的调节,调节图片的色温等。
卷积网络对图片比较敏感,那么如何让卷积网络不敏感呢?那么就是给网络输入很多“奇奇怪怪”的图片,就是在训练的时候模拟这种可能出现的各种变化。神经网络最擅长的就是“记住”数据,那么给同一张图片的不同形式,其实是可以降低网络对这张图片的“记忆能力”的。
后面会有一次课专门讲解数据增强,因为这在计算机视觉实在是太重要了。
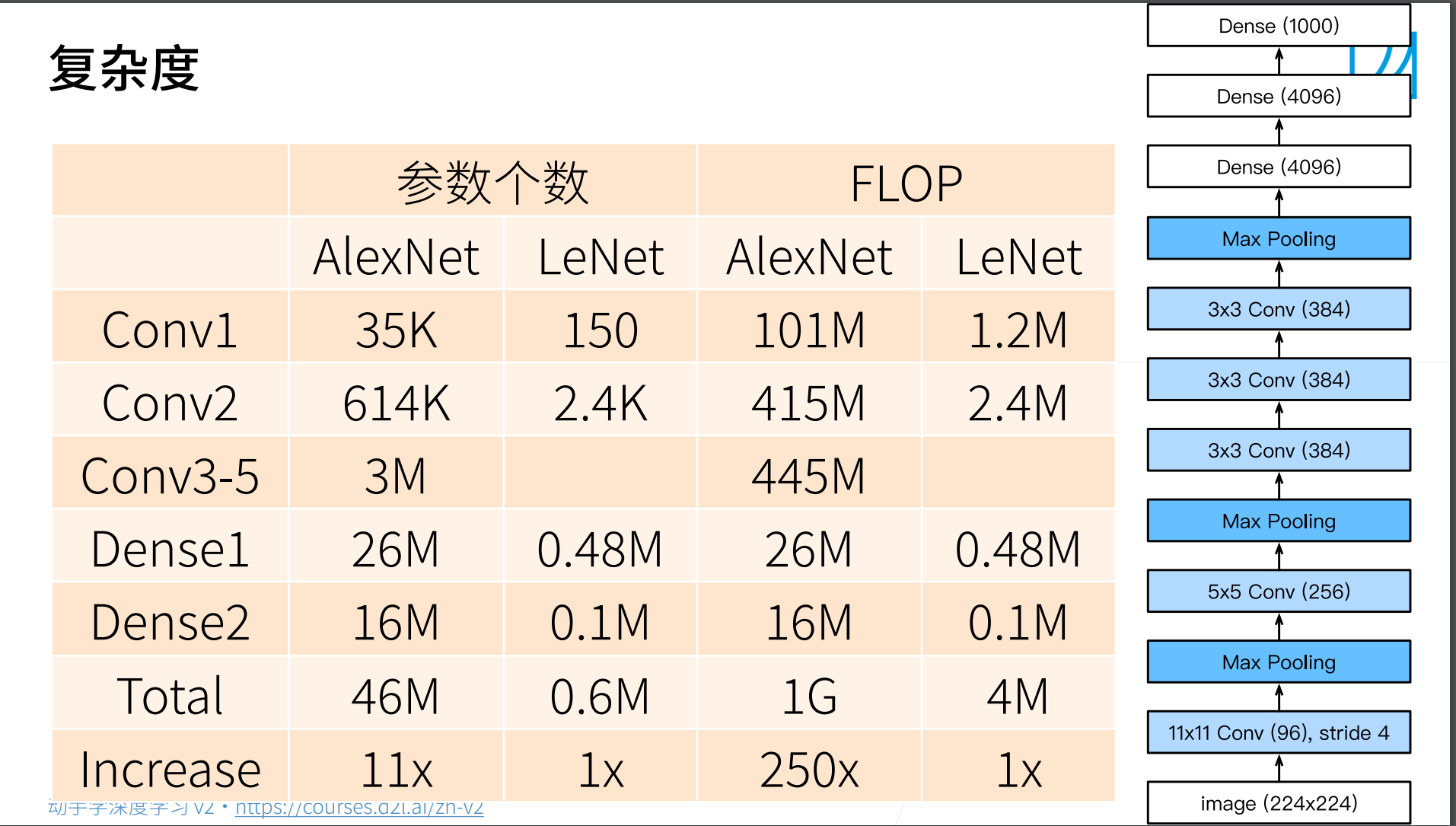
这里是AlexNet和LeNet的复杂度对比。

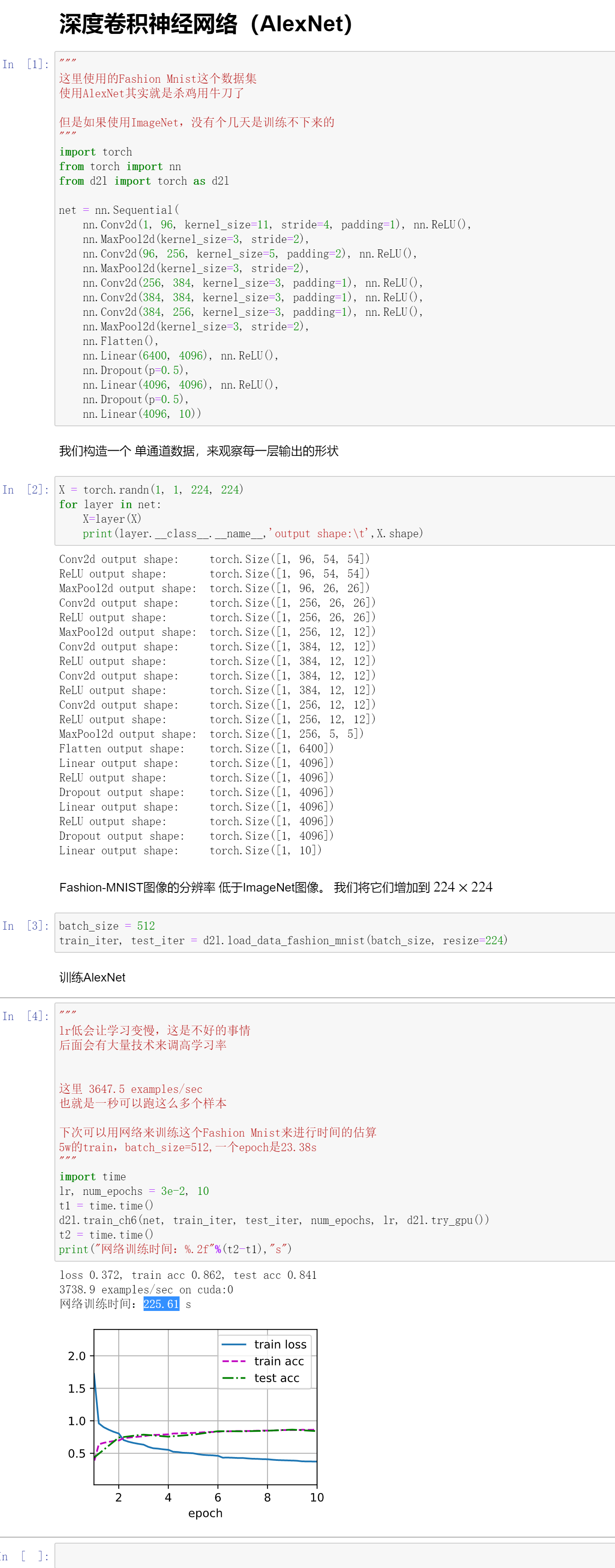
代码
QA
- 如何估算网络说需要的训练时间?
如果是CV的话,可以使用网络先在一个小的数据集上跑,然后等比例进行换算,大概就是估算出一个训练时间。
- 在其他学习资料中,讲到AlexNet会提及Local Response Normalization,但没太看懂。
LRN其实后面证明是没有什么作用的。
基本上整个神经网络,大家就是去看谁有用,谁没用。发现者一开始可能没有多想,可能觉得好用就这样了,后面的人会去看每个东西到底有没有用,这是这也是 AB Test(消融实验)。
- 为什么AlexNet最后要有两个相同的全连接层Dense4096,一个行吗?
一个还真不行,沐神说他之前试过,一个效果会差,两个4096的全连接是非常厉害的一个模型。
可以理解为全面的卷积特征抽取的不够好,不够深,所以后面需要两个大的dense来补。
- 没太明白为什么LeNet不属于深度卷积神经网络?
这是一个很意思的问题,那帮搞深度学习的人,其实最厉害的不是调参,而是包装。
其实15年之前基本认为是没有新东西的,只是把原来的这些东西做深,换新名字。
- 网络要求输入的size是固定的,实际使用的时候图片不一定是要求的size,如果强行resize层网络要求的size, 会不会最后的效果要差?
其实resize也是会保证高宽比的,所以其实效果不会那么变差,不用太担心这个问题。