多输入输出通道

通道数 channel,这个确实是大家通常回去仔细设的超参数。




我感觉沐神想说的就是下面的说法,一个多通道的卷积核大小可以是((k_h,k_w,input_{channel},output_{channel}))
怎么理解呢?((k_h,k_w))就很好理解了,input_channel就和卷积核的通道数是一样的,沐神说的三维卷积核就是这个,就是输入的通道有几维,那么这个三维卷积核的通道就有几维。
还有就是最后一个output_channel,这个和三维卷积核的个数有关,就是说要x个输出通道,那么就有x个三维卷积核。(输出通道的数量是人工设定的)


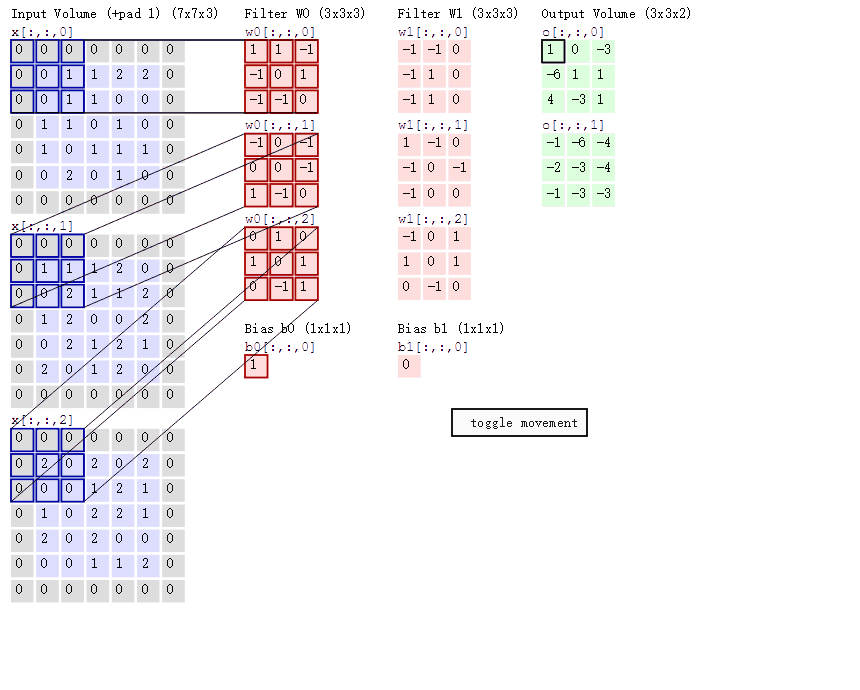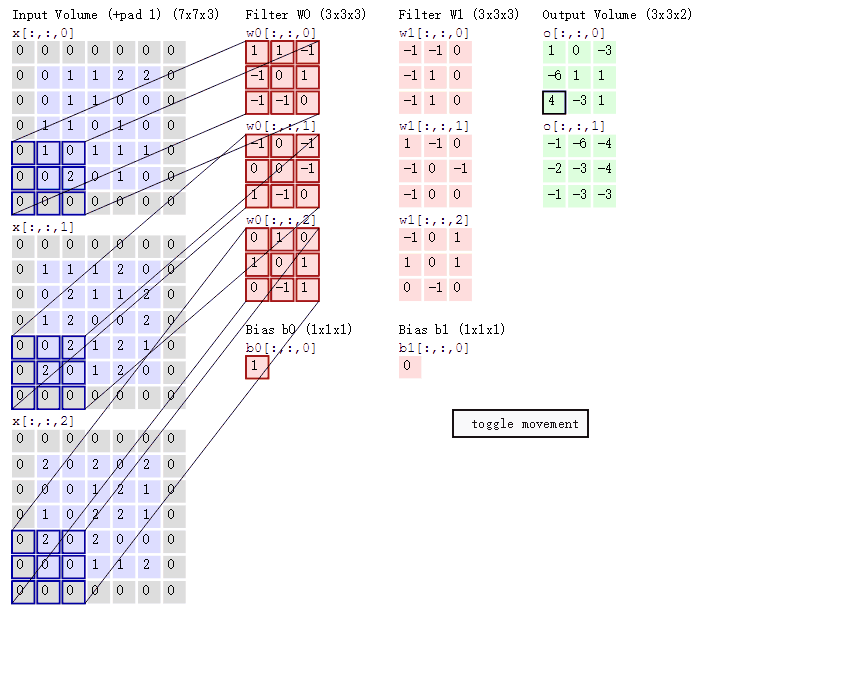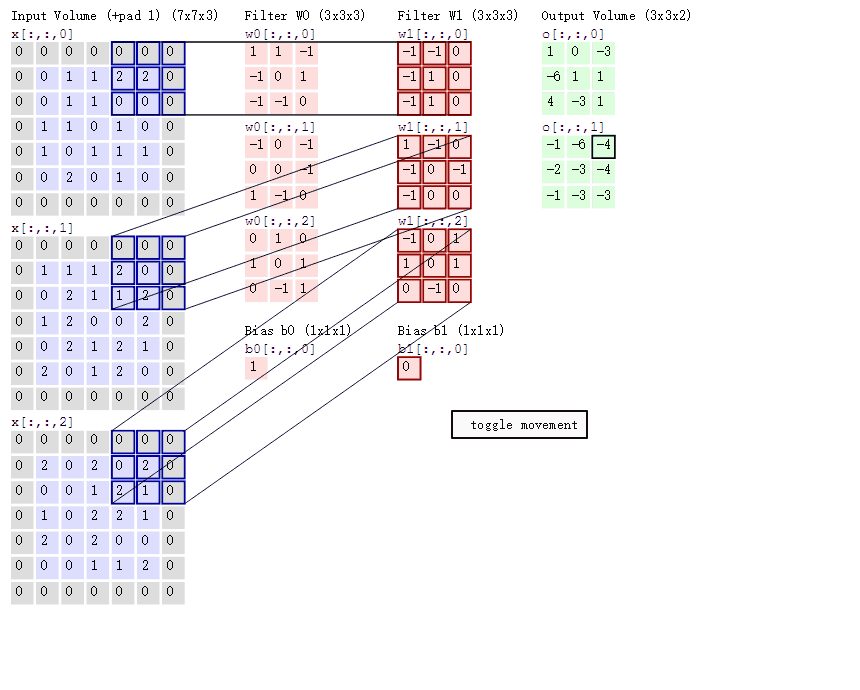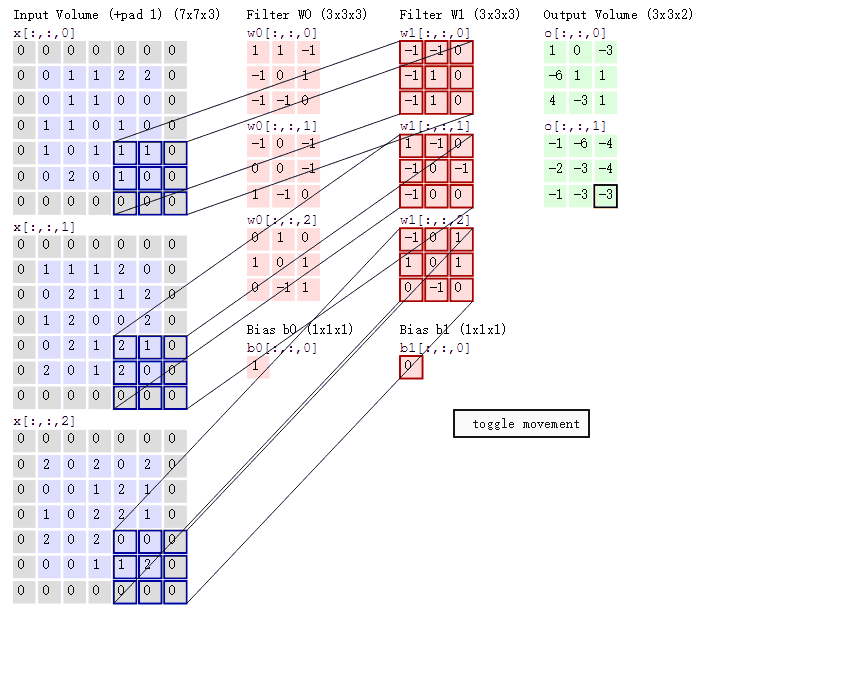

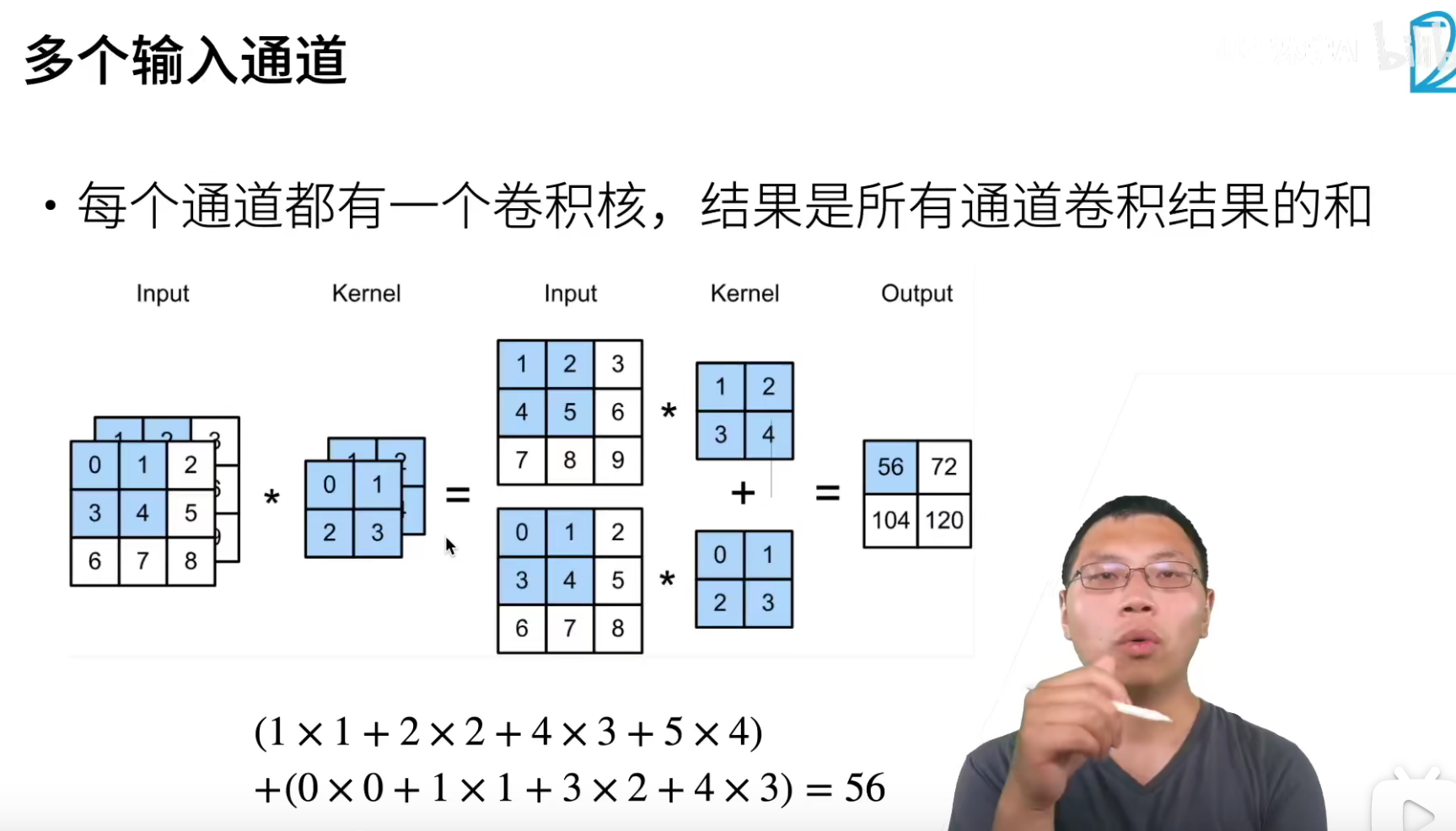
多输出通道(多个三维卷积核):可以认为每个通道都在识别特定模式。
多输入通道:将多通道输出进行加权相加,得到一个组合的模式识别。比如说A通道识别的猫头,B通道识别的胡须.... 最后希望在高层将这些识别的特征进行组合, 最终能够正常识别出一只猫
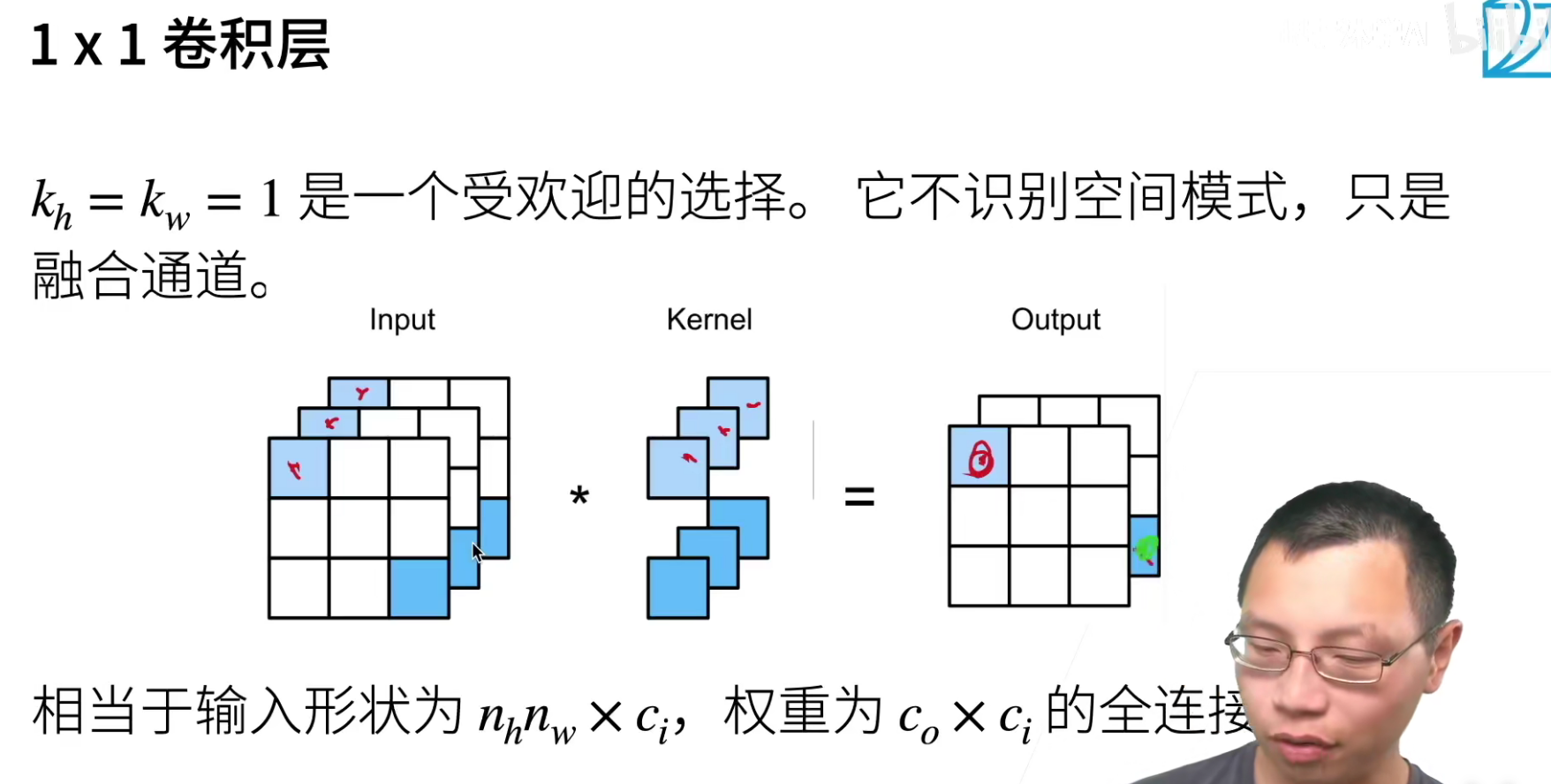
(1*1)卷积融合不同通道的数据,可以把(1*1)卷积就认为是一个全连接(加权组合),比如上面的channel从3变成了2,chanell数减少了,但是信息进行了融合。
因为使用了最小窗口,1×11×1 卷积失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力。 其实 1×11×1 卷积的唯一计算发生在通道上。


当然沐神的说法是可以说为了得到(mh,mw),需要多少的计算量。
卷积要存的参数,现对于MLP是少很多的,但是卷积的计算量也并不小,但是卷积的模型存储是不大的。
上面大概估算了一下计算开销,ImageNet的样本就是100w,单扫一次是14min,那么反向运算再来14min,也就是一个epoch就要28min。那么就算训练100个epoch吧 ,大概也是需要30个小时。

代码实现
QA
- 全卷积能解决输入大小变化的情况,有什么方法能解决channel动态变化的情况吗?只能下采样?
这个问题没太看懂。
输入和输出不变的情况下,通常是不会去动这个通道数的。
如果把输入和输出的高宽都减半的情况下,输出通道数要翻倍。意思就是把空间信息压缩了,然后把这些压缩的信息,更多在通道中存储下来。下采样后通道拓宽一倍。
- 关于多输出通道数量是如何控制呢?
输出通道的数量是人为控制的,然后输出通道的数目和三维卷积核的数量是一样的,因为一个三维卷积核的卷积结果就是一条输出通道。
也就是说,你设计几条输出通道,你就要设计多少个三维卷积核。
- 网络越深,padding 0 越多,这里是否会影响性能?
计算性能会稍微有点影响,但是模型性能是不会影响的。
- 每个通道的卷积核都不一样吗?同一层不同通道的卷积核大小必须一样吗?
每个通道的卷积核是不一样的,不同通道的卷积核大小是一致的。
你可选择不同大小的卷积核,GoogLeNet就是这么用的,如果大小不一致的话,要写成两个卷积操作。不同通道保持核的大下一致,这是出于方便计算的角度考虑。
- 计算卷积时,bias的有无,对结果影响大吗?bias的作用怎么解释?
其实bias的作用就是当数据偏离均值的时候,bias就是那个偏离均值的负数。
但是实际上我们会做大量的均匀化的操作,所以bias实际来说没有那么大的影响,但是其实bias对计算性能其实并没什么影响,所以加上还是可以的。
- 核的参数怎么选?
注意,卷积核的参数是学出来的,不是选出来的。
- 老师,如果是一个rgb图像,加上深度图,相当于输入是四个通道,做卷积是和rgb三通道同样做法吗?
不是的,这个深度信息是另外一个维度,这里要用到conv3-d,我们讲的对图片图例都是conv-2d。
- 卷积能获取位置信息吗?感觉卷积就是把网络信息提取出来便于函数拟合。
卷积是可以有位置信息的,卷积是对位置非常敏感的,(i,j)那个位置,就对应了原图(i,j)周围的那一块。
我们后面会讲如何通过池化层,让卷积对位置信息不要那么敏感。
- 关于编译器的选择?
沐神说他是没有用PyCharm,使用的是jupyter和vs code