填充和步幅

先将两个控制卷积层输出大小的超参数:填充 & 步幅。

上面是一个例子,如果是一张(32*32)的图片,使用一个(5*5)的kernel来进行卷积,那么在第7层的时候图片大小会变成(4*4),那么就不能在进行卷积了,换句话说就是,卷积层最多只能进行7层。
那如果要做深应该怎么办?(其实深度学习就是要做深!)
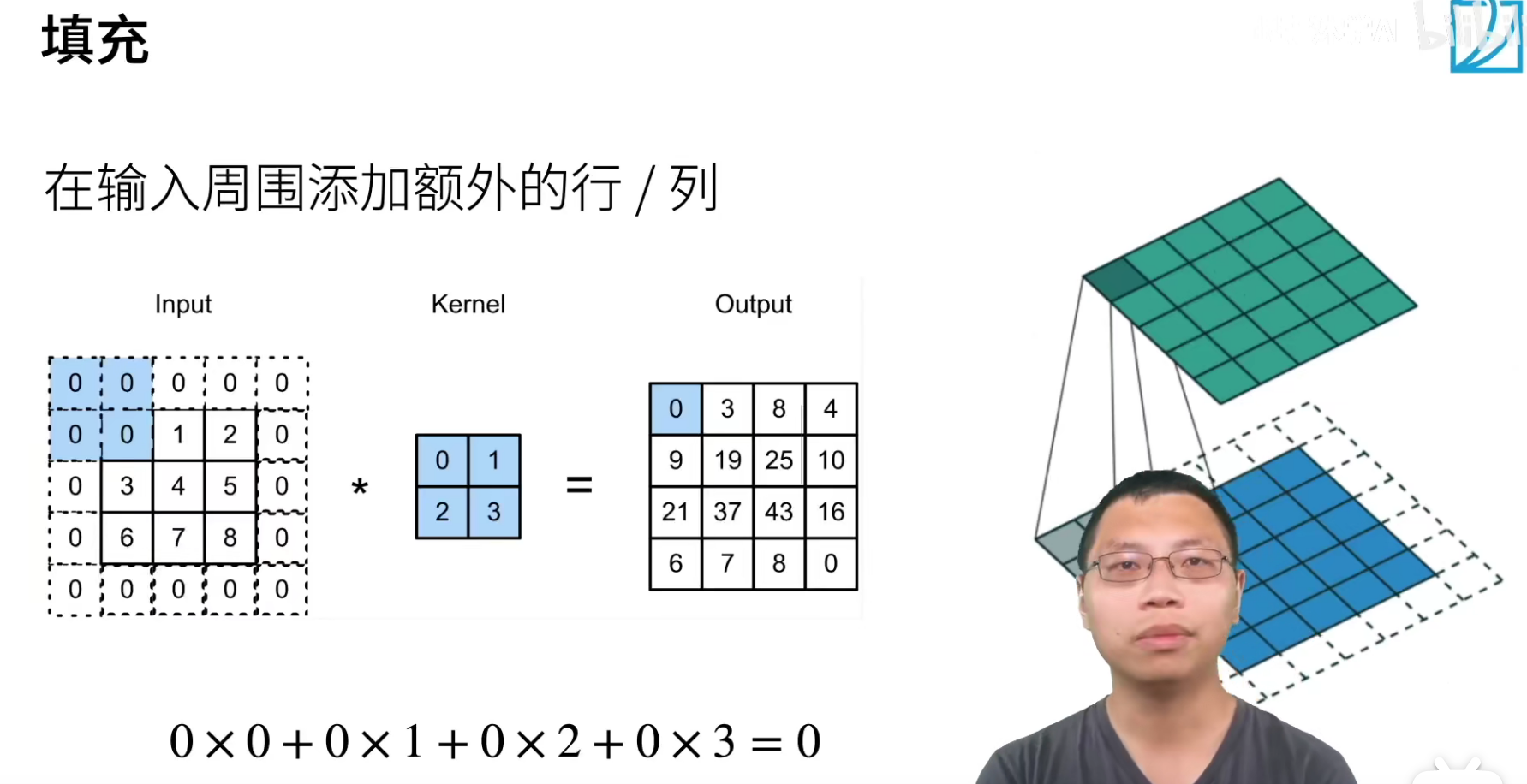
解决feature_map不断缩小的第一个方法就是填充,就是我们在四周加入额外的行和列,达到说我们的输出可以比以前更大。

一般填充(p)大小,通常取值(p=k-1),这样做是为让卷积后feature_map的size可以保持不变。
结论:一般很少使用偶数的卷积核,都是使用奇数的卷积核。

((224-4)/4=55)
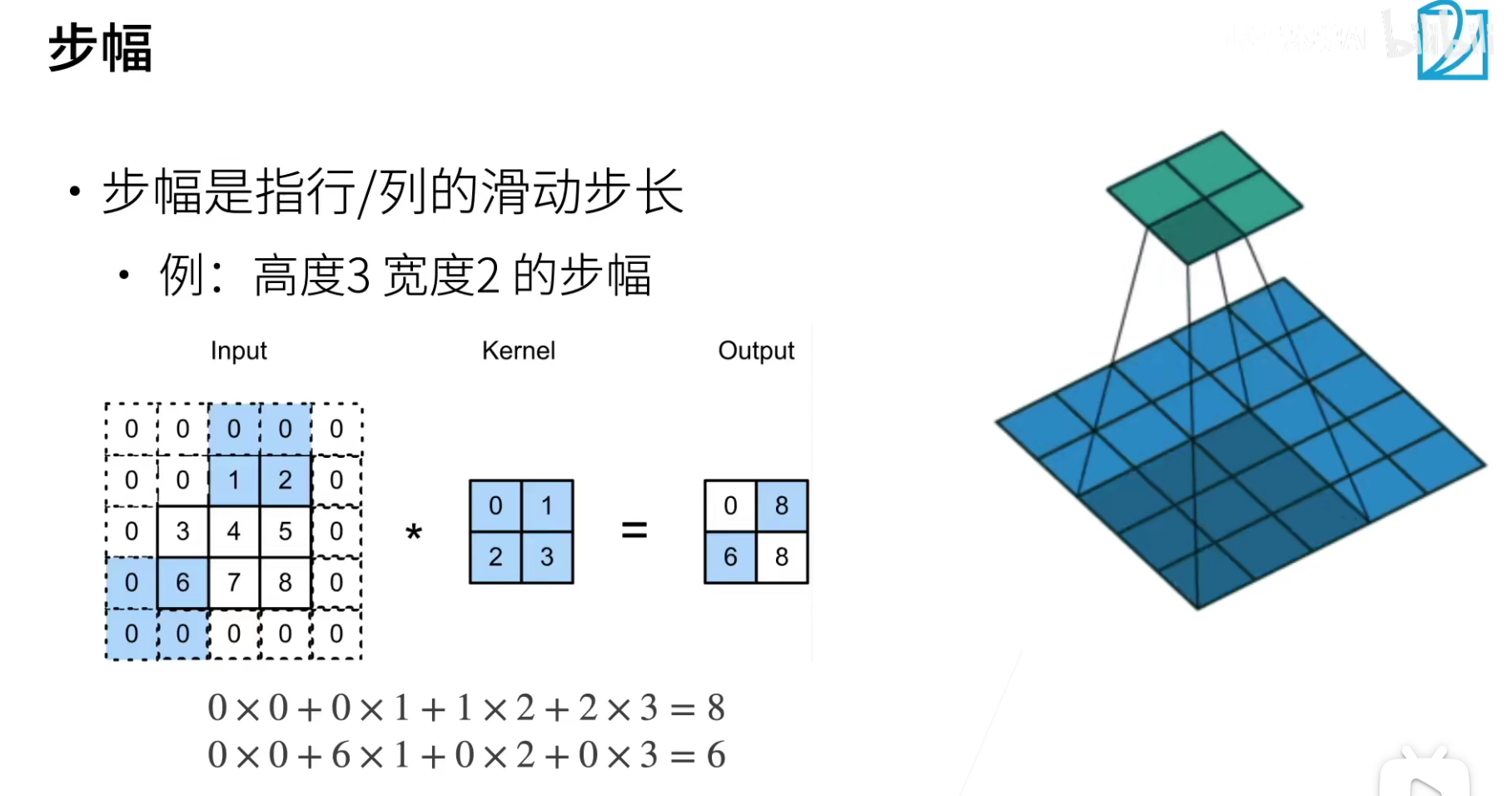
下图是步幅为2的走法。


通常步幅就是取2,这样每次的feature_map的size会减少一半。

代码实现

QA
- 这几个超参数的影响重要程度排序是怎么样的?核大小,填充,步幅。
- 核大小:核大小当然是最重要的,一般都是使用(3*3),最大不会超过(7*7)而且都是奇数
- 填充:padding一般就是取(k-1),就是为了保证feature_map不变,但是注意,pytorch中的padding是both sides。
- 步幅:strides一般是取2,每次减半。当然能够取1是最好的,因为可以看到更多的信息,但是我们一般最终就是要把一张图片缩小成(5*5),最大不超过(7*7)的样子,stride=1计算太慢了(要有很多个卷积层),使用stride=2就是为了减少计算量。所以stride什么时候取2,纯粹看我的计算复杂度是什么需求,一般做法就是把stride=2的层均匀的插入网络中。
- 为什么卷积核的边长一般选奇数?
一般都是选(3*3),一个好处是好对称,还有就是可以保留一定的空间信息。
但是有论文也说过其实(2*2)的卷积核效果也差不多。
- 一般卷积处理完,输出维度都要减半,为什么这里要提出输入输出保持不变?
就是为了能够把卷积网络做深啊!比如224,如果不保持不变,做不了几层的。
- 现在已经有很多经典的网络结构了,对于各种任务有各种结构,我们平时使用的时候,自己设计卷积核大小的情况多吗?还是直接套用经典结构?
我们一般都是使用经典的网络结构。或者更简单来说,你就用ResNet,ResNet是有一个系列的,18层、34层、50层、152层都是可以的。
一般来说大家都不会去手写神经网络,除非除非你的输入是一个非常不一样的情况。一般都是直接套用经典结构或在经典的结构上稍微做一些调整。
- 为什么要用(3*3)的卷积核,(3*3)的视野很小
(3*3)是因为多个(3*3)串联,可以等效大的卷积核,而且计算代价低。比如两个(3*3)串联可以对应一个(5*5)的感受野。如果最后输出的的大小是(1*1)的话,并且stride不是特别大,那么这个(1*1)是一定可以看到整个大小的图片。