竞赛总结


我们讲知识,也不可能所有东西都cover到,让大家竞赛不是让大家去学某个特定的知识,而是说大家遇到一个问题,怎么去找一个解决方案。这一次的解决方案和下一次的会不一样,但是问题是你怎么去找这个东西,去问人也行,去搜索也行。
私榜和公开榜是不一样的,大家能看到的都是公榜的(私榜就是为了防止大家刷数据集!)


我们没有讲集成学习,但是集成学习确实是深度学习中一个很成熟的方案,就是不要只训练一个模型,训练多几个模型,然后一起进行预测。
h2o也是用的集成学习,随机森林就是一个集成学习的模型,所以集成学习确实是刷榜经常用的一个方法。当然集成学习的坏处就是它有很多模型,你在预测的时候代价会比较大,但是如果只看训练精度的话,确实集成学习的模型是比较好的。
AutoML会利用多个机器学习包来进行学习。
貌似竞赛中,使用MLP最好的是0.22,但是MLP仔细调的话是可以调的很好的, 在特征的预处理,还有超参数的调节。
我们可以讲一下这个数据的难点:
-
一个房价的大数值,10w~100W,因为数值比较大,所以梯度会比较大,如果学习率没有设置好的话,梯度就会爆了。如果都是比较大的一个正数的话,可以对其取一个log,让数值压到一个比较好的区间,然后再做均值为0,标准差为1都是可以的。
-
第二个比较难是数据有很多文本的特征,这里使用one-hot是非常不明智的,feature_size有10w,使用one-hot会爆内存。比如第二名是使用了transformer,还可以使用word2vec,或者使用稀疏矩阵取处理离散值,当然关于NLP处理的后面会讲。
-
还有就是公榜和私榜的问题,建议就是不要一直对着公榜的成绩调参,因为一直只能是前9个月的数据,其实是说不准后3个月会如何,这也是实际生产中常会遇到的问题。如果说是过分去调整了,那么就很有可能会overfitting。

总结:
-
AutoGloun(AutoML)在合理的计算开销下得到还不错的模型
-
虽然AutoML可以做自动特征抽取,但适当加入一些人工数据预处理,还是一个不错的方法
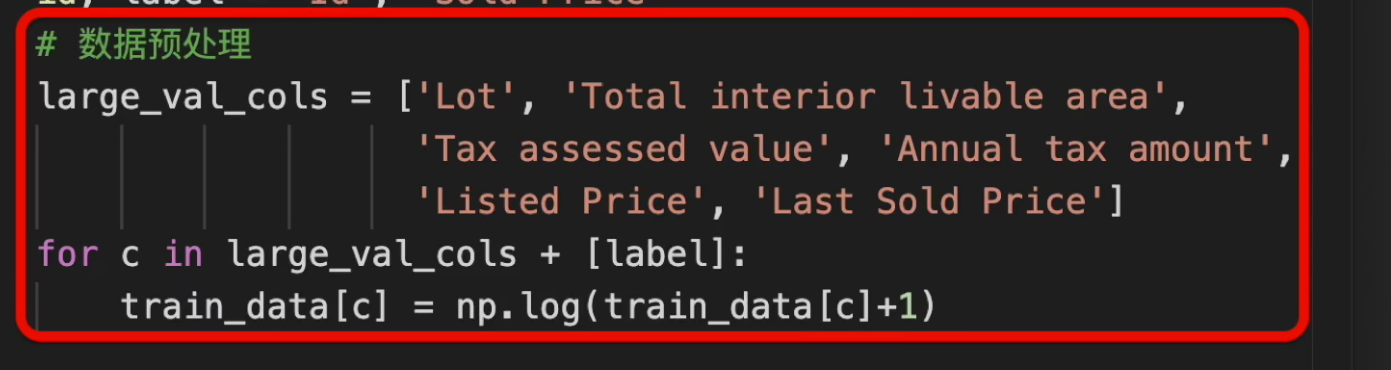
数据中有比较大的数值,而且样本之间的数值变化比较大,比如房子的卖价,纳税的价格等,我们对这些数值取log,其余和之前是完全一样的。
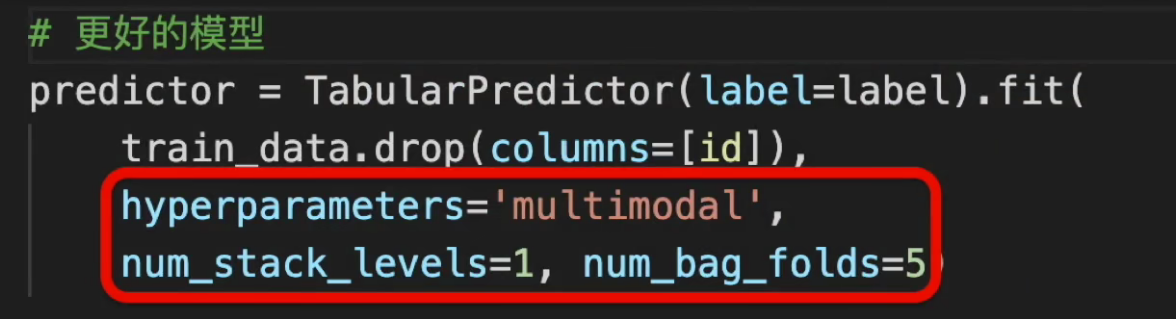
数据中包含房子的介绍,是大段的文本,可以使用multimodal这个选项用transformer抽取特征,并做多模型融合,注意,这个需要gpu才能跑得动。
然后我们做了多层模型ensemble来得到更好精度。
- 对于比较大的数据集,计算开销仍然是瓶颈,我们需要使用GPU,甚至是多台机器来做分布式训练。
QA
- 为了避免overfit,是调参好,还是不调参好,或者是只调什么方面?有没有什么经验分享?
其实如果是实际应用的话,参数调整并不是说最重要的。但是如果是竞赛的话就是另外一回事了。
关于竞赛的话,集成学习是一个不错的方法。
但是竞赛其实很多时候都是一个运气,公榜和私榜差了那么多,可能拿第一和拿第二的同学真的理解了什么,很多时候可能就是运气。
- 为了什么说80%的时间是找数据、清理数据这些?数据搭建pipeline不就好了吗?为什么改进模型等等不占主要时间?
其实对于实际的业务需求,找到数据是最重要的,比如要你预测比特币价格,哪里来的数据?数据是否有效?这都是需要考虑的。
但是对于科研的话,大部分都是已经给提供了数据集的,所以找数据的部分就不用过多进行投入,而是应该把精力花费在模型的改进上。
- autogulon和pytorch结合做NAS能不能讲demo?
NAS就是去搜索一整个网络的架构,但是我们并不打算去讲这个东西,因为对大家用处不大,除非你就是做这个research的。NAS是一个用有钱人玩的游戏,一个NAS实验,如果是用云的话,分分钟几十万美金就没了。所以如果你只是做这个research的话,我们可以讨论,但是你要用的话,我觉得NAS还不够成熟。
- MLP有值得精细调参的价值吗?不是说2层的feedforward已经有拟合任何非线性函数的能力了吗?
理论上你用一根铁丝可以biao出任意一种钥匙,但实际上很难操作。
理论上我也有成为世界首富的可能,但实际做不到。
MLP还是有精细调参的价值的,MLP是一个很强的模型,CNN可以认为是一个特殊的MLP,卷积就是一个有结构化的MLP,最近在火的transformer,bert其实里面有很多MLP的东西在里面,而且其实大家怀疑里面真正其中起作用的也是MLP的东西。
- 用MLP做股票预测时,预测值发生滞后,预测值曲线就像是真实值曲线往后平移了的效果,有什么好的解决方法?
不要做股票预测,是做不赢的,华尔街实力一点也不弱,也是做不赢。沐神说他所见过的所有做股票预测的,最终也都失败了。(股票根本根本就不是一个理性的东西)