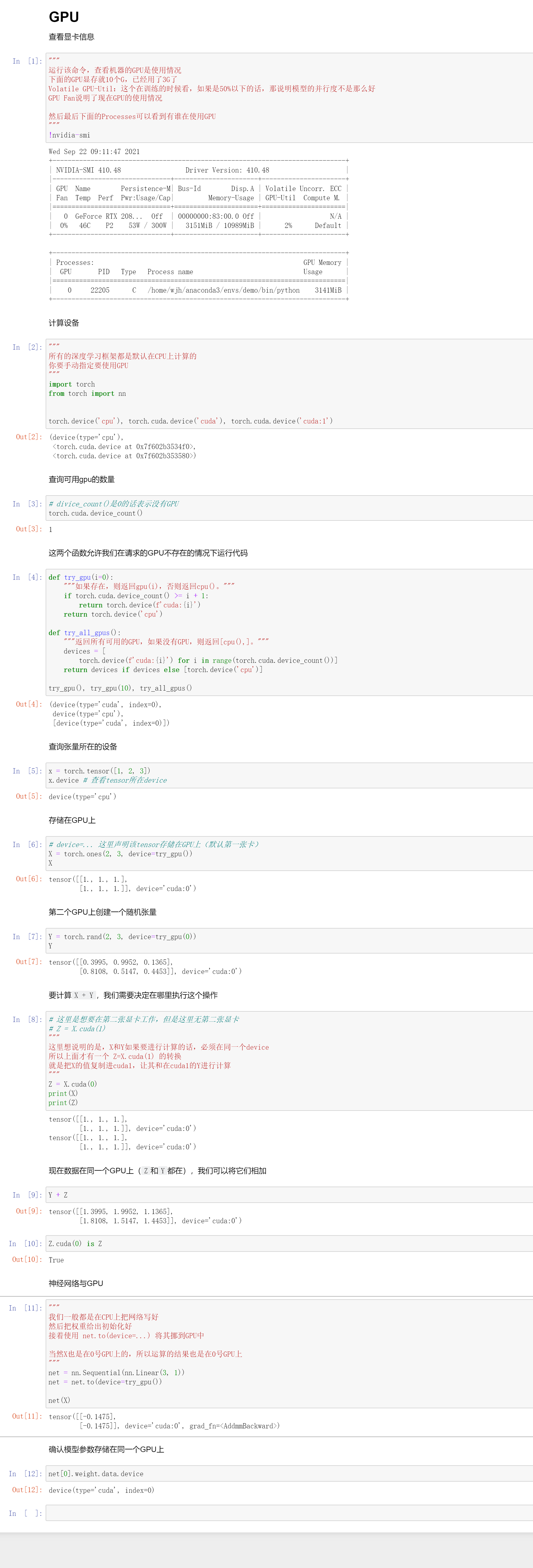
使用GPU
其实如果没有钱买GPU的话,使用Google Colab也是一个不错的选择,大概是10 dollar一个月。
算力其实是很贵的... 利用好算力是一件很重要的事情!
关于Nvidia Driver too old的问题,如果是服务器的话,这里不要盲目的去更新显卡驱动,这样子会把别人的环境搞坏的。
正确的方式应该是去安装适合自己驱动的版本的框架。
# 下面命令来确认cuda的版本,然后在进行相应cuda的下载
cat /usr/local/cuda/version.txt
使用GPU是简单的,只要把权重copy到GPU上,在把输入copy到GPU上,就可以在GPU上进行运算了。
购买GPU
GPU的性能主要由以下3个参数构成:
-
计算能力。通常我们关心的是32位浮点计算能力。16位浮点训练也开始流行,如果只做预测的话也可以用8位整数。
-
显存大小。当模型越大或者训练时的批量越大时,所需要的显存就越多。
-
显存带宽。只有当显存带宽足够时才能充分发挥计算能力。
当然只推荐消费类的GPU(GTX、RTX),对于企业类的GPU这是不推荐的,一般会贵5~6倍。
显卡尽量要买新的,因为工艺在进步,新一代对比旧一代,同样的计算性能,价格会便宜。(电子设备都是如此,买新不买旧)
整机配置
通常,我们主要用GPU做深度学习训练。因此,不需要购买高端的CPU。至于整机配置,尽量参考网上推荐的中高档的配置就好。不过,考虑到GPU的功耗、散热和体积,在整机配置上也需要考虑以下3个额外因素:
- 机箱体积。显卡尺寸较大,通常考虑较大且自带风扇的机箱。
- 电源。购买GPU时需要查一下GPU的功耗,如50 W到300 W不等。购买电源要确保功率足够,且不会造成机房供电过载。
- 主板的PCIe卡槽。推荐使用PCIe 3.0 16x来保证充足的GPU到内存的带宽。如果搭载多块GPU,要仔细阅读主板说明,以确保多块GPU一起使用时仍然是16倍带宽。注意,有些主板搭载4块GPU时会降到8倍甚至4倍带宽。
QA
- 如果买GPU的话,显存是越大越好吗?还有什么评价指标吗?
当然是越大越好,但是显存是一个很贵的事情,显存比CPU的内存贵。
GPU的显存是越大越好的,但是越大越贵,所以你要在你的承受范围能力买。
后面会讲解CPU和GPU的工作原理的不同,也就是为什么说GPU显存越大越好。
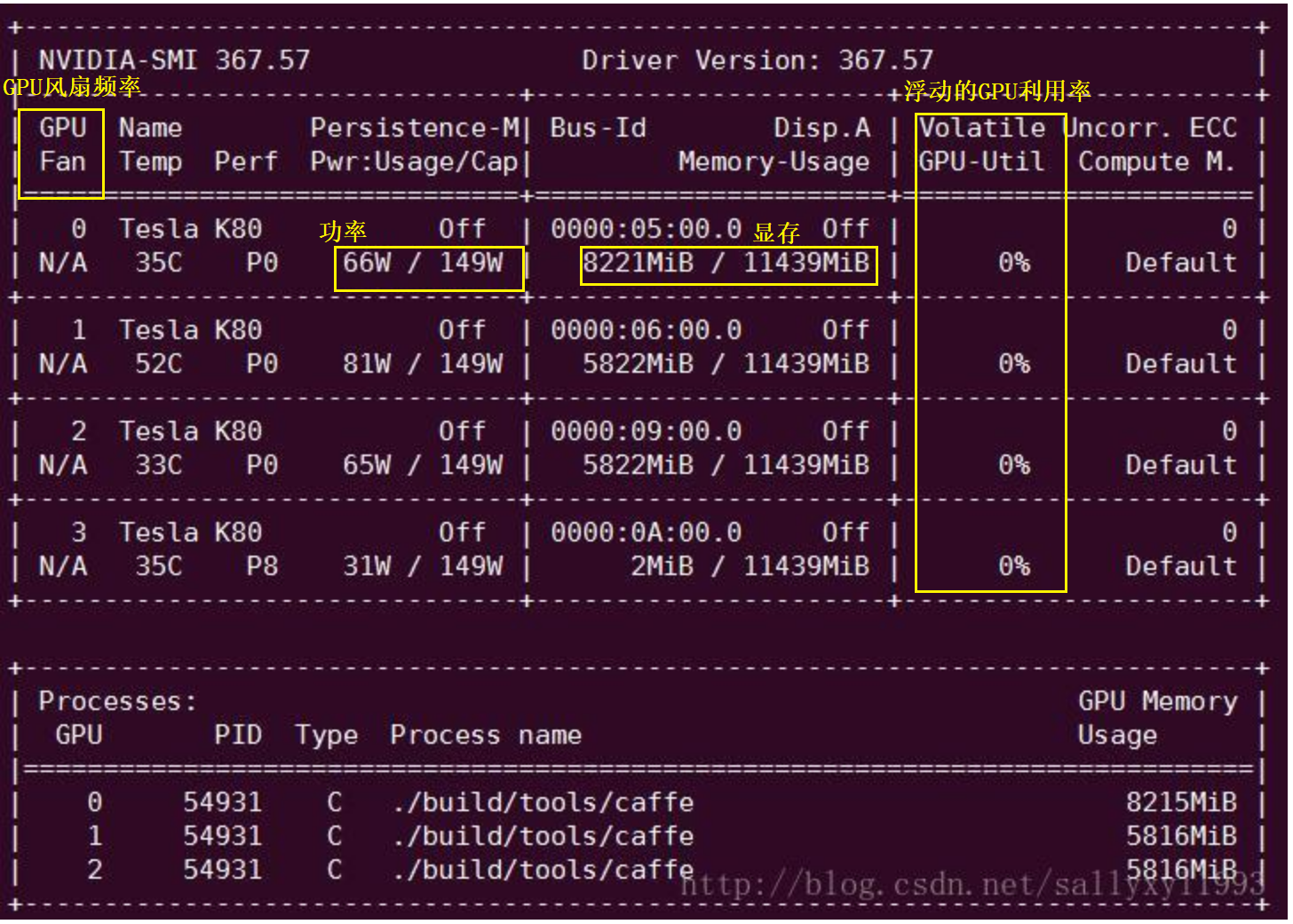
- 跑项目的时候显存不够怎么办,如果把batch_size调小,显存够用了但是cuda占用一直很低怎么办?
如果是显存不够用的话,那么只有把batch_size给调小。
但是如果把batch_size调小的话,那么Volatile GPU-Util(GPU计算单元的利用率)不高。
那么这里给的建议就是把模型给调小一点,比如如果是使用ResNet152的话,这里就建议修改成ResNet50。
- GPU使用率是不是越高越好,长时间满负荷是不是对显卡不太好?
满负荷对GPU是没有问题的,唯一的问题是温度不要过热!最好建议就是不要超过80度,90度太久。
沐神说他是烧过很多块卡的... 满负荷是没有问题的,但是就是要注意温度!温度是一个很重要的事情。
- 一般使用gpu训练,data在哪一步to gpu比较好?
一般是在最后network train的时候。
因为很多数据的变化,做data preprocess在GPU上不一定支持的比较好,如果data在GPU上做的比较好,那么可以往前走,比如很多时候在GPU上做一些图片的处理。
- tensor.cuda() 和 to(device)有什么区别?
都是将tensor挪到GPU上,但是to(device)是讲module,也就是模型挪到GPU上。
- 使用GPU后加速效果不明显有哪些可能的原因?运行GPU使用率在60%~70%。
其实60~70%的使用频率已经不低了,看看能不能优化下网络。
对于CNN的话,GPU的使用率很容易到80%以上。
- 怎么评价apple M1 gpu和cpu共用内存?
集成显卡基本都是个cpu共用内存的,而且共不共用内存不是关键,而是要看内存的带宽,其实M1的内存带宽还行。
- cuda和GPU到底是什么关系?
GPU是硬件,cuda可以认为是开发的一个SDK。
- 自定义的block被放在同一个Sequential内的不同layer,但是不想共享参数,该怎么做?
只要new新的对象就可以了,传入的也是对象,如果不是同一个对象,默认是不会共享参数的。