感知机

1960年的“物理感知机”。
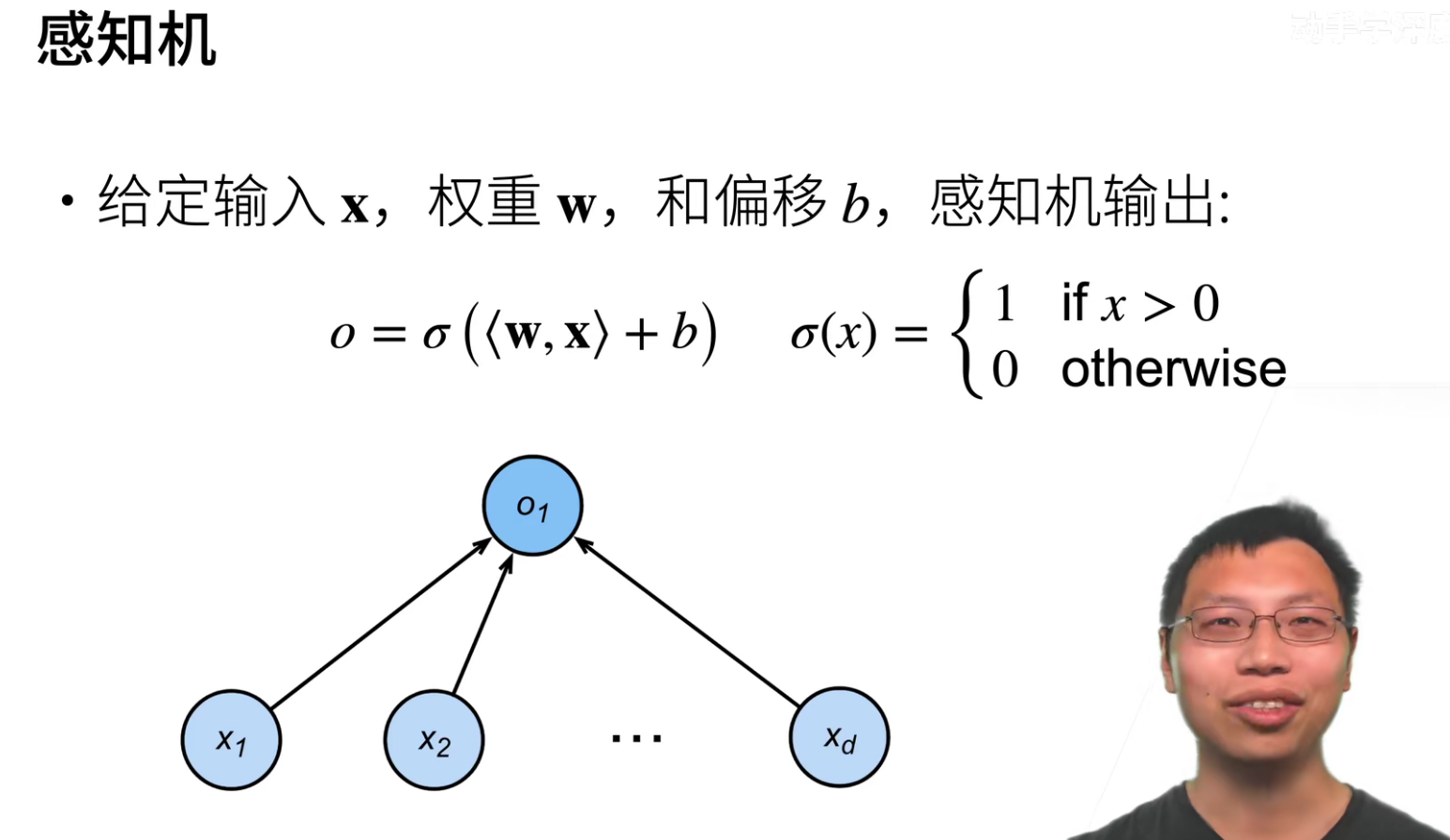
感知机是人工智能最早最早的一个模型。

感知机就是线性回归套了一层激活函数。
因为感知机的输出只有一个元素,所以只能做为一个二分类的问题。

可以理解为感知机使用了(l(y,x,w)=max(0,-y<w,x>))这个损失函数。(只预测正确的)


多层感知机

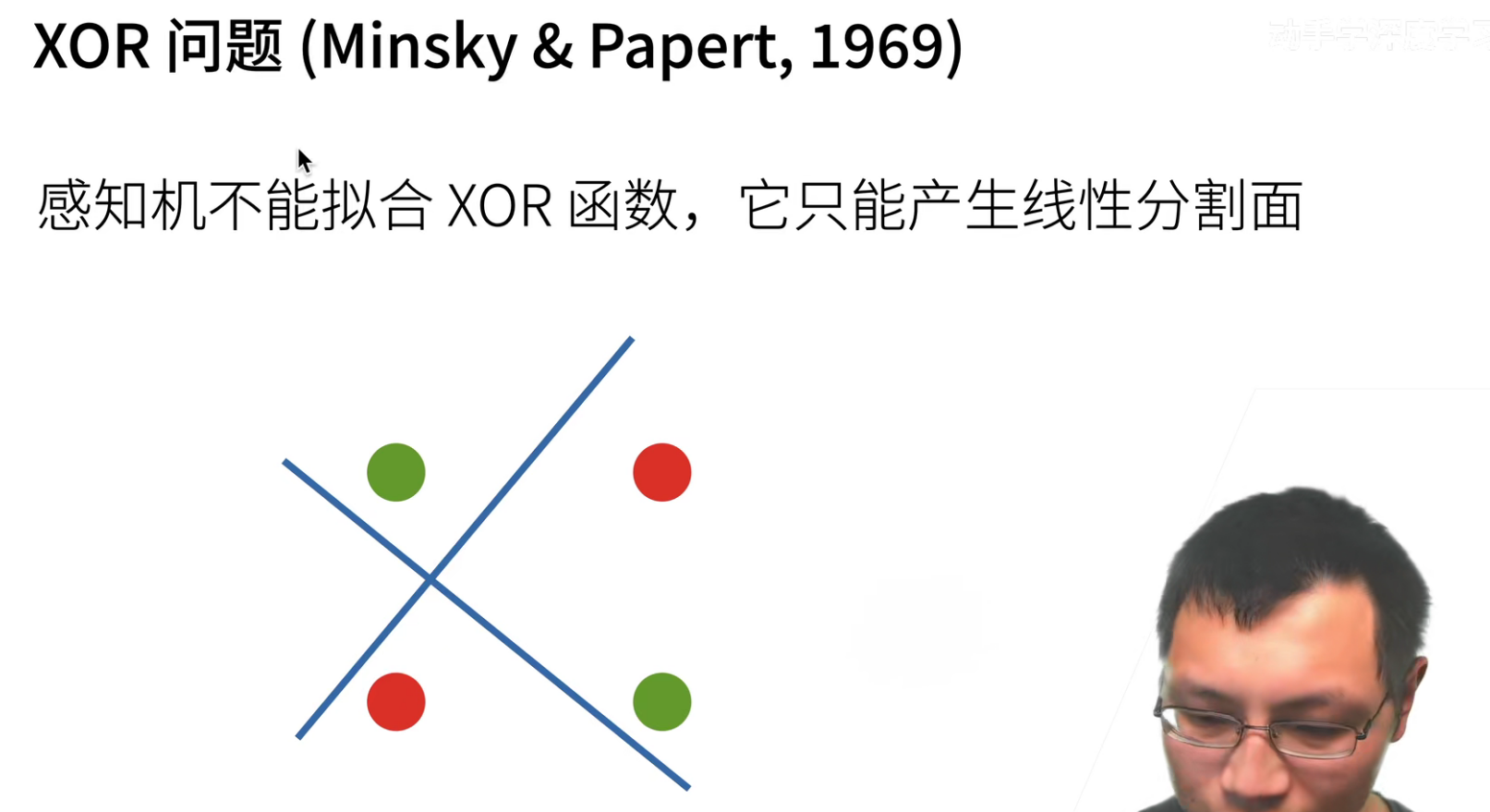
多层感知机如何解决XOR问题呢?
假设一次做不了,那么先学一个简单的函数,再学一个简单的函数,再用一个函数将两部分进行组合,那么就从一层变成了多层,这就是多层感知机干的事情。
下图是从感知机(一个神经元)到多个神经元的感知机,虽然隐层只有一层,但是不同的神经元可以学到不同的特征,然后进行组合,就可完成非线性的拟合。

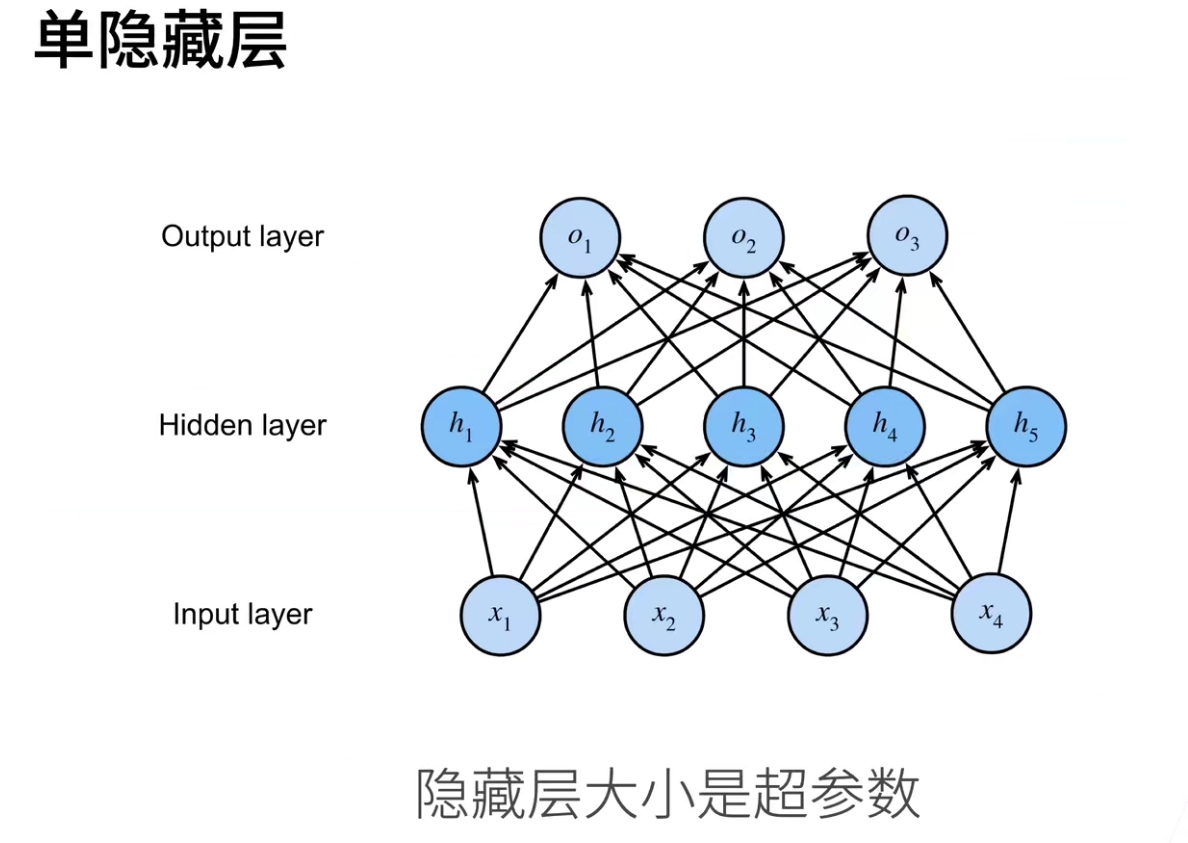
为什么隐藏层大小是超参数?因为inputs是不能改的,outputs基本也是固定的,那么可以进行修改的就是隐藏层。


如果不是非线性的激活函数,其实也没有意义,因为如果是线性的激活函数,基本加了和没加是一样的。


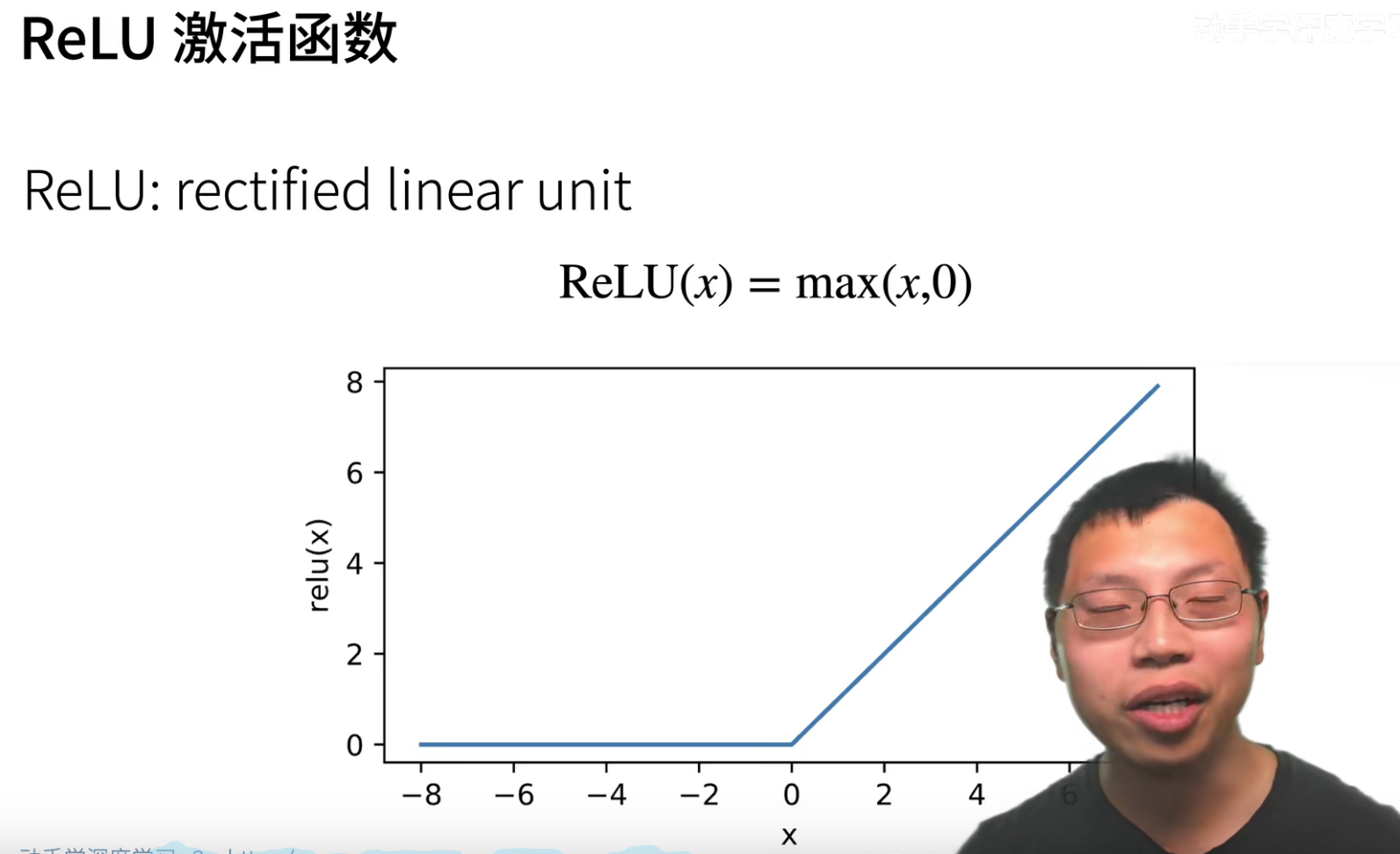
ReLU的唯一好处就是算的特别快,前面的sigmoid和tanh都要进行指数运算,指数运算是一件很贵的事情,一次指数运算可以抵得上100次乘法运算的计算开销。
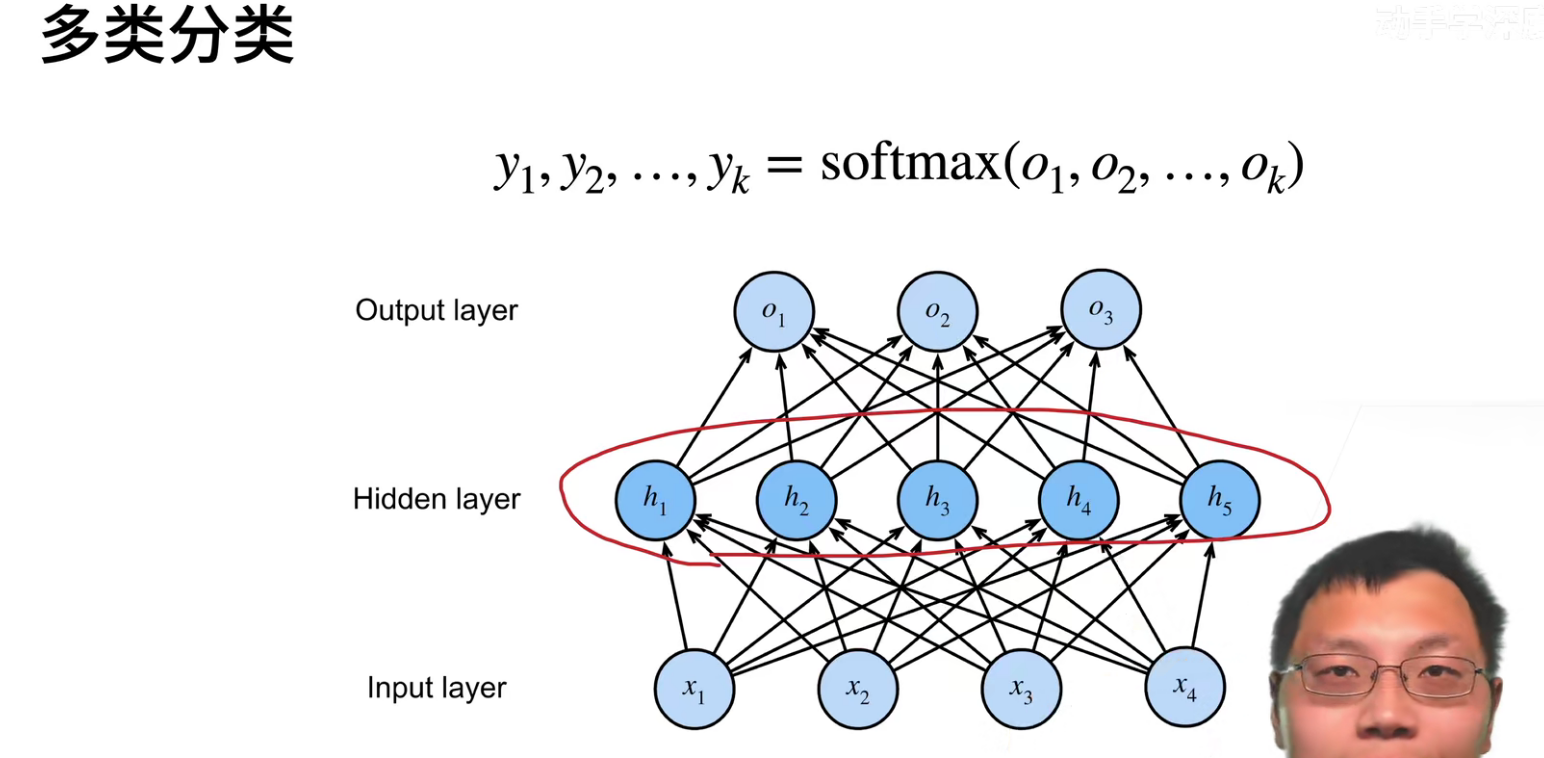
其实如果没有中间这个隐层的话,实际上和softmax回归是没有差别的。

这里只是把单个输出变成了k个输出。
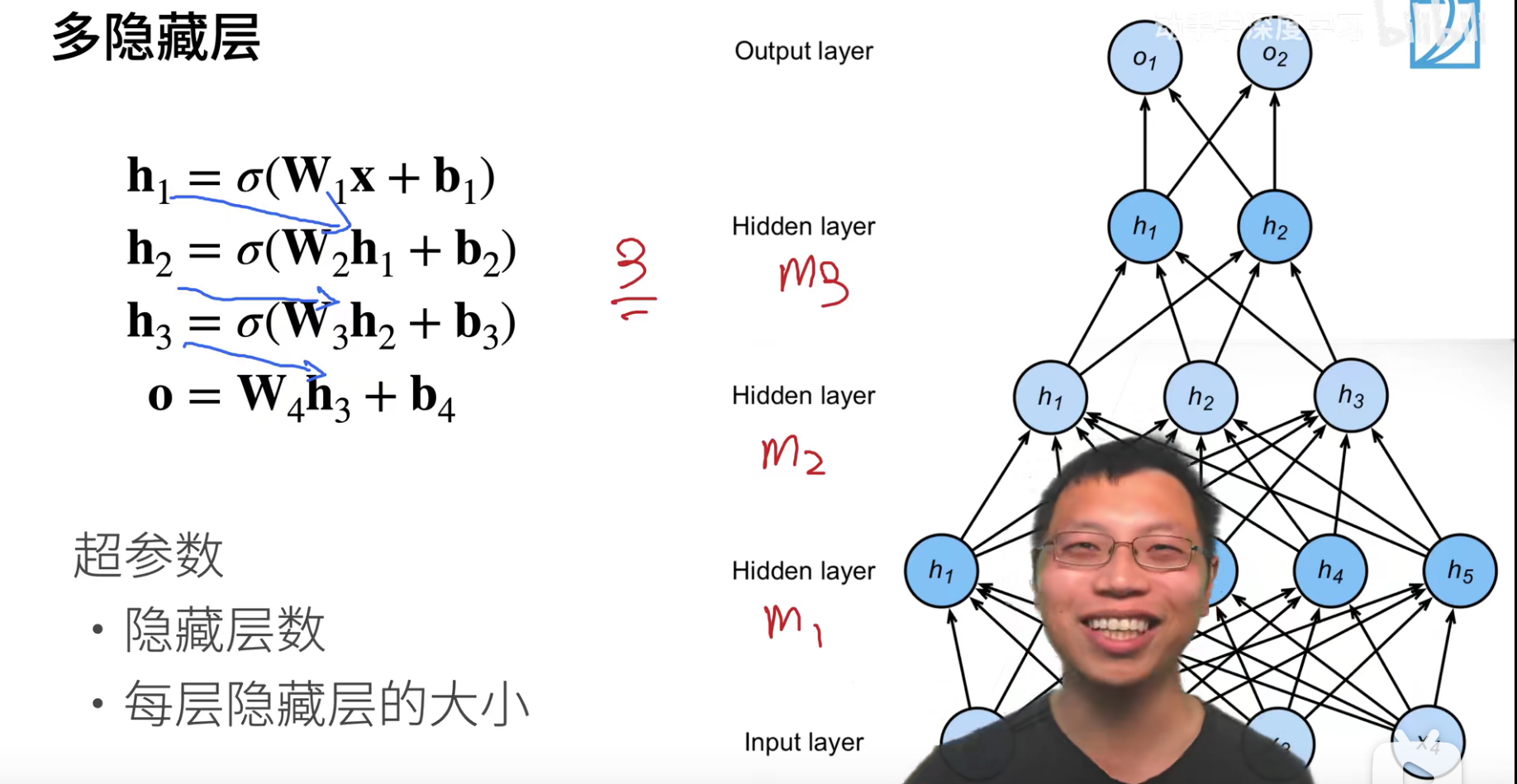
多层感知机是可以把层数做深的。
在隐层中,每一层的激活函数都不能少,如果少了,就相当于层数减一。输出是不用激活函数的。
超参数:
- 隐藏层数
- 每层隐藏层的大小
怎么设置隐藏层的数量和每层的大小呢?其实是有工程经验的。
从有种角度来说,深度学习就是在做压缩,把输入很多的数据,最后输出成几个简单的类别,这个本质上就是对数据进行压缩。所以其实第一隐层是可以适当大一些的,比如输入是128,那么可以先扩展到256,然后后面再进行加深,进行数据的压缩。所以隐层一般都是“先肥后窄”,一般都不会反过来,如果反过来的话,过度压缩的话就会损失很多信息。当然后面CNN有些模型是先压缩,后面再扩展的,这个后面会讲到。(没有太多科学可以讲,纯粹靠手感.. 深度学习目前是工程走在理论研究的前面了)

常用的激活函数,如果没有想法,使用ReLU就可以了,因为ReLU简单,算的快。
多层感知机从零开始实现
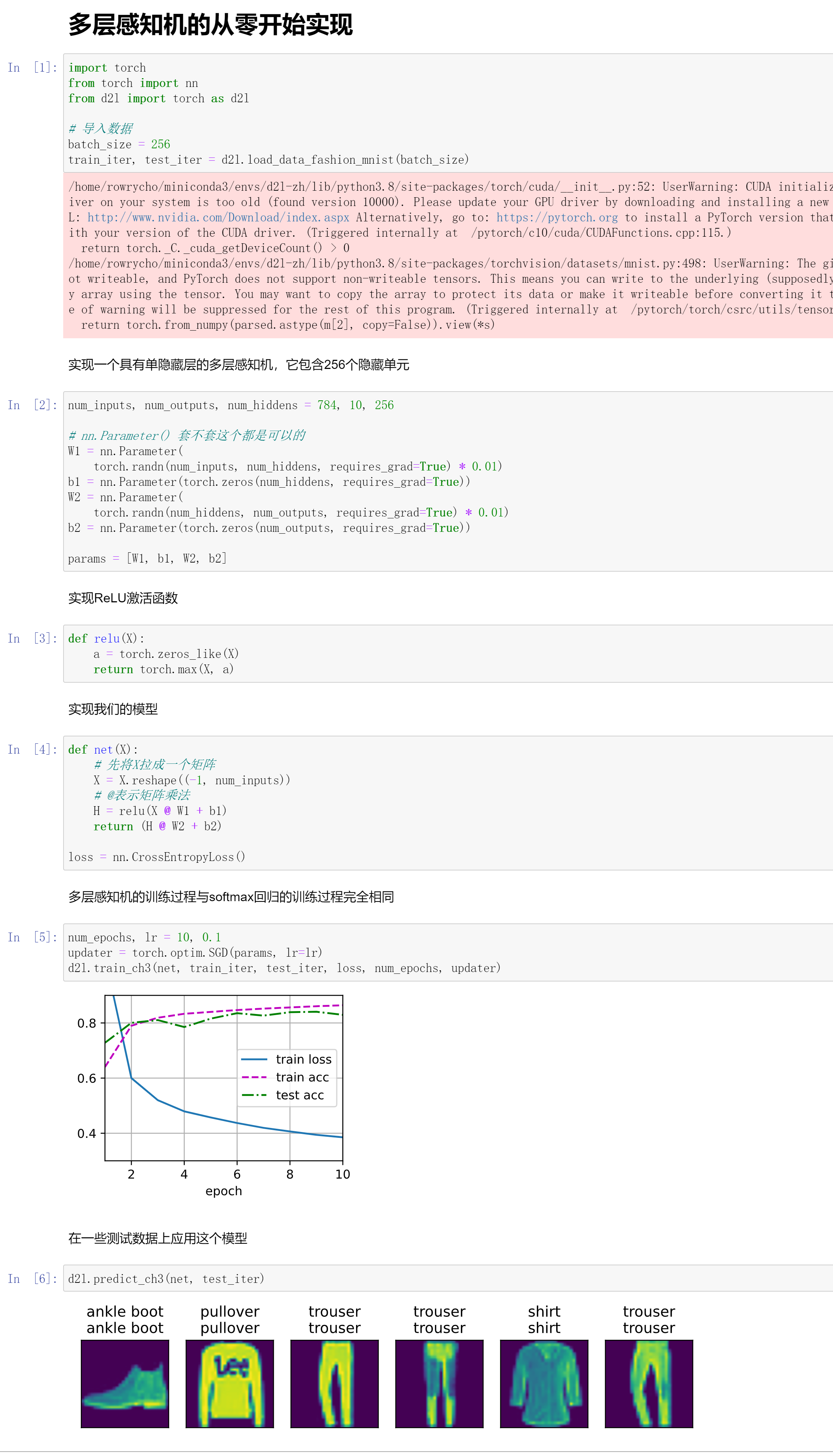
操作总结
# 导入数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 设置层数的数目
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# nn.Parameter() 套不套这个都是可以的
W1 = nn.Parameter(
torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(
torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
# 实现ReLU的激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
# 先将X拉成一个矩阵
X = X.reshape((-1, num_inputs))
# @表示矩阵乘法
H = relu(X @ W1 + b1)
return (H @ W2 + b2)
loss = nn.CrossEntropyLoss()
# 训练过程
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
多层感知机简洁实现
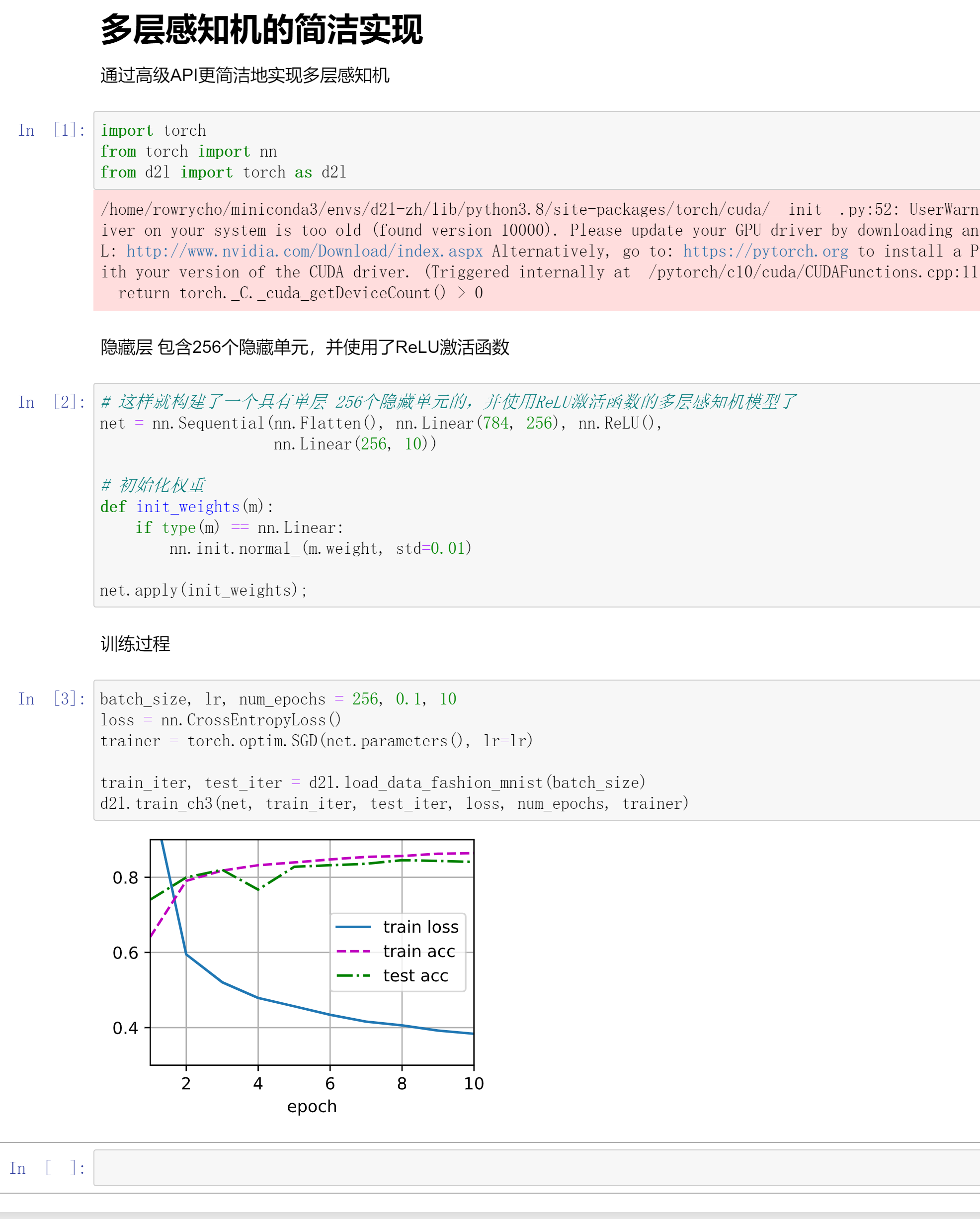
操作总结
# 这样就构建了一个具有单层 256个隐藏单元的,并使用ReLU激活函数的多层感知机模型了
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),nn.Linear(256, 10))
# 初始化权重
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
# 训练过程
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
QA
- 多层感知机和纯softmax模型相比,loss是下降了,但是精度并没有提升。
可以解释为因为模型更大了,所以数据拟合性更好,所以loss在下降。
- MLP和SVM
现在基本都是使用的MLP,因为MLP要改动的代码其实不多,输入和输出基本都不用变,只要把中间部分进行更换即可。
但是SVM就不是了,需要调整的东西会比较多。
- 神经网络中一层是怎么看的?
一层主要只可以学习的参数,比如下图,就是有两层(输入层不算做一层)
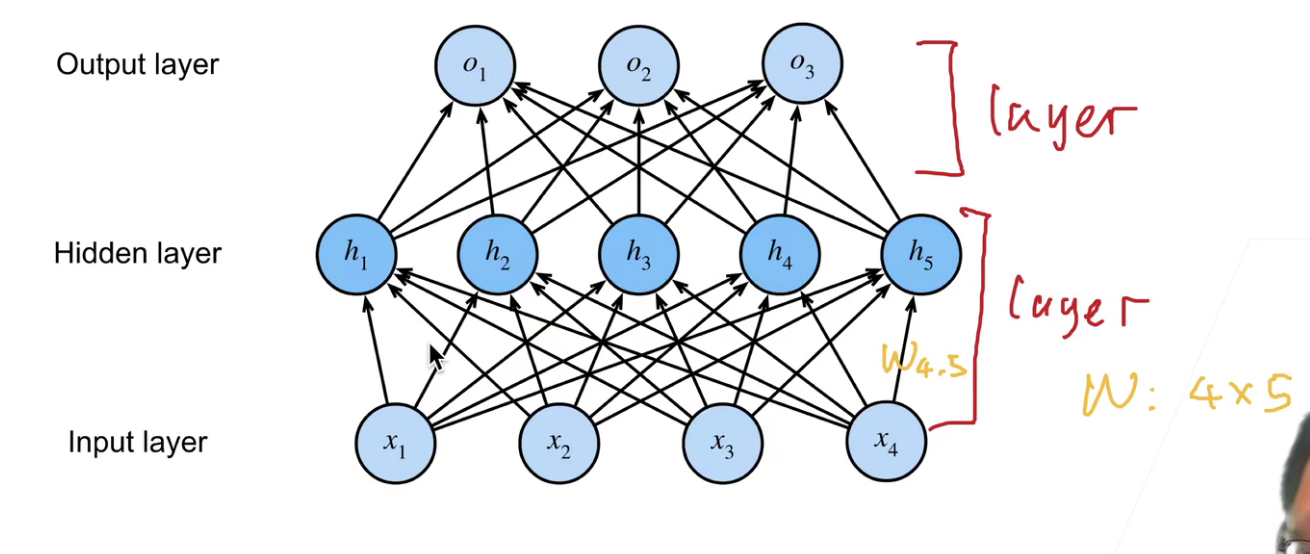
有几层参数需要学习,就可以认为是几层,当然在隐层之间可以认为激活函数是一个分界。
- 为什么神经网络要增加隐藏层的层数,而不是神经元的个数?
其实增加深度效果会更好,如果只是增加宽度的话,因为神经元是并行的,并不能很好的进行特征的提取。如果是深层的话,可以第一层先提取一点,第二层再提取其他的....
其实增加网络的宽度和深度都是有用的,但是增加网络的深度效果会更好。
(可以认为2014年之前,深度学习基本都是没有什么突破的东西,和20,30年前做的东西是一样的,只是把网络做的更深)
- 不同任务下的激活函数是不是都不一样?也是通过实验来确认的吗?
激活函数远远没有选择隐藏层那些大小和数量来的重要,所以就用ReLU吧...就是你可以选,但是本质上没有太多的区别。