表的横向拼接
表的横向拼接就是在横向将两个表依据公共列拼接在一起。
在Excel中实现横向拼接利用的是vlookup()函数,关于vlookup()函数这里就不展开了,相信大家应该都很熟悉。
在 Python 中实现横向拼接利用的 merge()方法,接下来的几节主要围绕 merge()方法展开。
连接表的类型
连接表的类型关注的就是待连接的两个表都是什么类型,主要有3种情况:一对一、多对一、多对多。
一对一
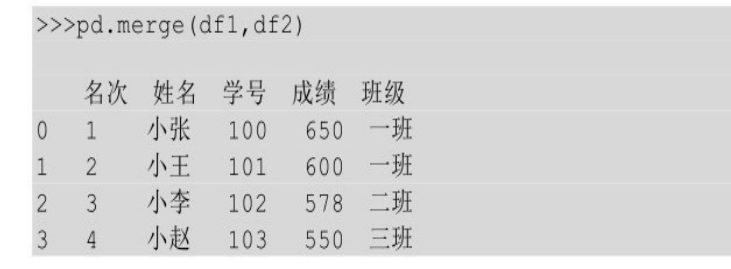
一对一就是待连接的两个表的公共列是一对一的,例子如下所示。

如果要将df1和df2这两个表进行连接,那么直接使用pd.merge()方法即可,该方法会自动寻找两个表中的公共列,并将找到的公共列作为连接列。
上面例子中表 df1和 df2的公共列为学号,且学号是一对一的,两个表运行 pd.merge()方法以后结果如下:
多对一
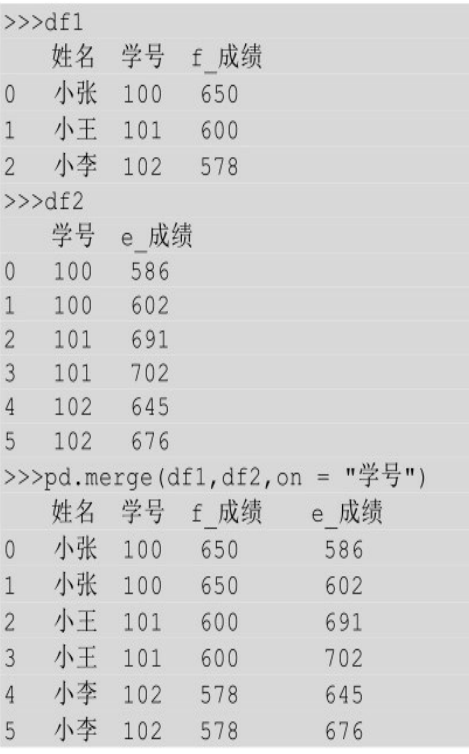
多对一就是待连接的两个表的公共列不是一对一的,其中一个表的公共列有重复值,另一个表的公共列是唯一的。
现在有一份名单 df1,其中记录了每位学生升入高三以后的第一次模拟考试的成绩,还有一份名单df2记录了学号及之后每次模拟考试的成绩。要将这两个表按照学号进行连接,由于这两个表是多对一关系,df1中的学号是唯一的,但是 df2中的学号不是唯一的,因此拼接结果就是保留df2中的重复值,且在df1中也增加重复值,实现代码如下:
多对多
多对多就是待连接的两个表的公共列不是一对一的,且两个表中的公共列都有重复值,多对多连接相当于多个多对一连接,看下面这个例子:

连接键的类型
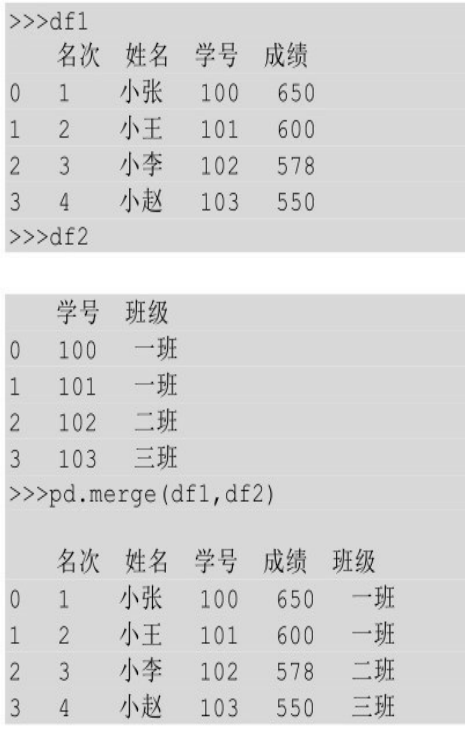
默认以公共列作为连接键
如果事先没有指定要按哪个列进行拼接时,pd.merge()方法会默认寻找两个表中的公共列,然后以这个公共列作为连接键进行连接,比如下面这个例子,默认以公共列学号作为连接键:
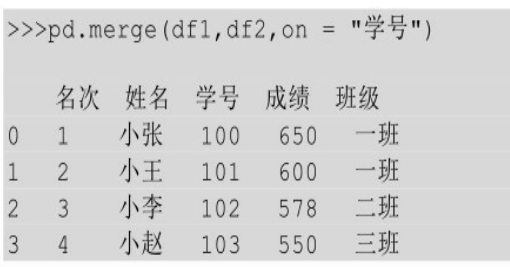
用on来指定连接键
也可以用参数on来指定连接键,参数on一般指定的也是两个表中的公共列,其实这个时候和使用默认公共列达到的效果是一样的。
公共列可以有多列,也就是连接键可以有多个,比如下面这个例子用学号和姓名两列做连接键:

分别指定左右连接键
当两个表中没有公共列时,这里指的是实际值一样,但列名不同,否则就无法连接了。
这个时候要分别指定左表和右表的连接键,使用的参数分别是left_on和rigth_on, left_on用来指明左表用作连接键的列名,right_on用来指明右表用作连接键的列名,例子如下:

把索引列当作连接键
索引列不算是真正的列,当公共列是索引列时,就要把索引列当作连接键,使用的参数分别是 left_index 和 right_index,left_index 用来控制左表的索引,right_index用来控制右表的索引,下例中的左、右表的连接键均为各自的索引。
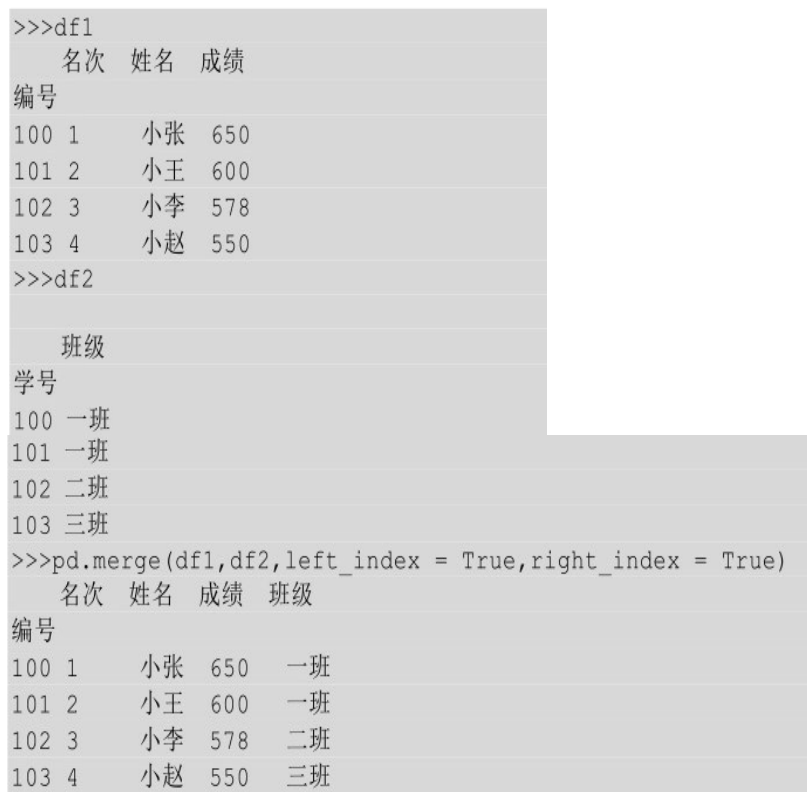
在上面的例子中,左表和右表的连接键均为索引。
还可以把索引列和普通列混用,下列左表的连接键为索引,右表的连接键为普通列。

连接方式
前两个小节举的例子比较标准,也就是左表中的公共列的值都可以在右表对应的公共列中找到,右表公共列的值也可以在左表对应的公共列中找到,但是现实业务中很多是互相找不到的,这个时候该怎么办呢?这就衍生出了用来处理找不到的情况的几种连接方式,用参数how来指明具体的连接方式。
内连接 inner
内连接就是取两个表中的公共部分,在下面的例子中,学号100、101、102是两个表中的公共部分,内连接以后就只有这三个学号对应的内容。

如果不指明连接方式,则默认都是内连接。
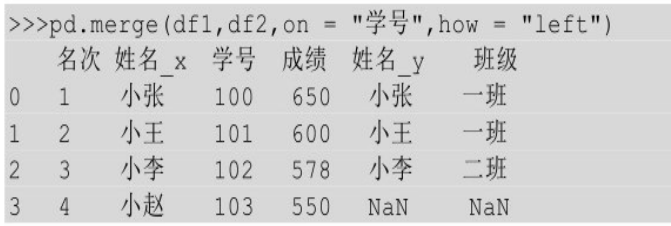
左连接 left
左连接就是以左表为基础,右表往左表上拼接。下例的右表中没有学号为103的信息,拼接过来的信息就用NaN填充。
右连接 right
右连接就是以右表为基础,左表往右表上拼接。下例的左表中没有学号为104的信息,拼接过来的信息就用NaN填充。

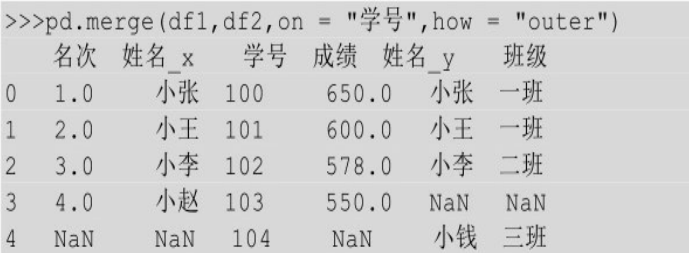
外连接 outer
外连接就是取两个表的并集。下例中表df1中学号为100、101、102、103,表df2中学号为100、101、102、104,因此外连接取并集以后的结果中应包含学号为100、101、102、103、104的信息。
重复列名处理
两个表进行连接时,经常会遇到列名重复的情况。
在遇到列名重复时,pd.merge()方法会自动给这些重复列名添加后缀_x、_y或_z,而且会根据表中已有的列名自行调整,比如下面这个例子中的姓名列:

当然我们也可以自定义重复的列名,只需要修改参数 suffixes的值即可,默认为["_x","_y"]。

表的纵向拼接
表的纵向拼接式与横向拼接相对应的,横向拼接是两个表依据公共列在水平方向上进行拼接,而纵向拼接是在垂直方向进行拼接。
一般的应用场景就是将分离的若干个结构相同的数据表合并成一个数据表,比如下面是两个班的花名册,这两个表的结构是一样的,需要把这两个表进行合并。

在Excel中两个结构相同的表要实现合并,只需要把表二复制粘贴到表一的下方即可。
在Python中想纵向合并两个表,需要用到concat()方法。
普通合并
普通合并就是直接将待合并表的表名以列表的形式传给pd.concat()方法,运行代码,即可完成合并,例子如下:

这样就把一班的花名册和二班的花名册合并到了一起。
索引设置
pd.concat()方法默认保留原表的索引,合并后的索引列编号就显示为12341234,但是这样看着很不顺眼。
我们可以通过设置参数ignore_index的值,让其等于True,这样就会生成一组新的索引,而不保留原表的索引,如下所示。

重叠数据合并
前面的数据都是比较干净的数据,现实中难免会有一些错误数据, 比如一班的花名册里写进了二班的人,而这个人在二班的花名册里也出现了,这个时候如果直接合并两个表,肯定会有重复值,那么该怎么处理呢?
前面讲过的重复值处理是不是可以处理这种情况呢?答案是肯定的,具体实现如下所示。

经过删除重复值以后,“葛颜”就只出现一次了。
小结
表的横向拼接
pd.merge() pd.merge(df1,df2,left_on="学号",right_on="编号",how="inner")
连接表 连接键的类型
参数 on 声明连接的字段(两个表的字段名相同)
参数 left_on 左表连接字段 rigth_on 右表连接字段 (两个列名不同,但是值是一样的)
参数 left_index right_index (True/False) 左右表使用索引来进行表的连接 (也可以一个表用索引,一个表用普通列)
连接方式
参数 how
left right inner outer
表的纵向拼接
pd.concat([df1,df2,..]) pd.concat([df1,df2],ignore_index=True).drop_duplicates()
参数 ignore_index 不要原来的索引 索引重新从0开始
一般合并后会去重 drop_duplicates()