数据分组
数据分组就是根据一个或多个键(可以是函数、数组或df列名)将数据分成若干组,然后对分组后的数据分别进行汇总计算,并将汇总计算后的结果进行合并,被用作汇总计算的函数成为聚合函数。
数据分组的具体分组流程如下图所示。

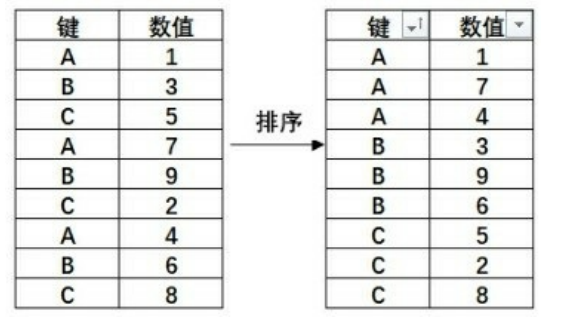
Excel 中有数据分组这个功能,但是在使用这个功能以前要先对键进行排序(你要按照哪一列进行分组,那么键就是这一列),升序或降序都可以,排序前后的结果如下图所示。
键值排序完成后,选中待分组区域,然后依次单击菜单栏中的数据>分类汇总即可。分类字段、汇总方式都可以根据需求选择。汇总方式就是对分组后的数据进行什么样的运算,我们这里进行的是计数运算, 因此在选定汇总项中勾选数值复选框。分类汇总对话框及分组结果如下图所示。

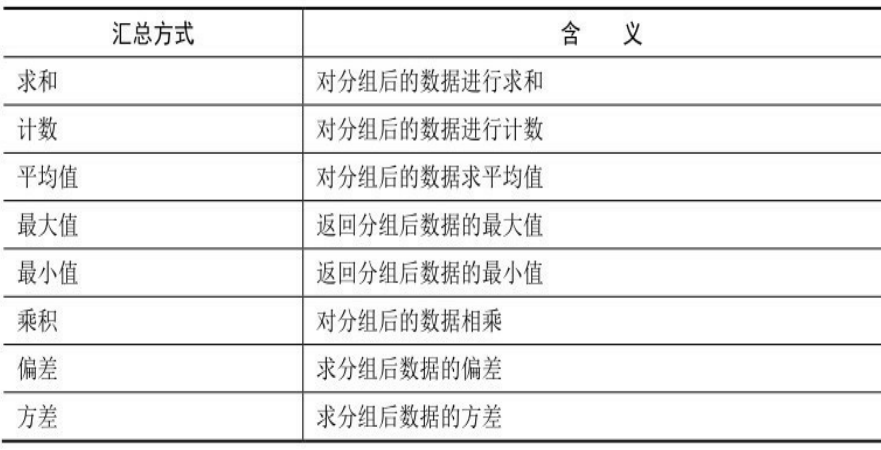
Excel中常见的汇总方式如下表所示。
在Python中对数据分组利用的是groupby()方法,这个有点类似于sql中的groupby,在接下来的几个小节里面,我们会重点介绍Python中的groupby()方法。
分组键是列名
分组键是列名时直接将某一列或多列的列名传给groupby(),groupby()方法就会按照这一列或多列进行分组。
按照一列进行分组
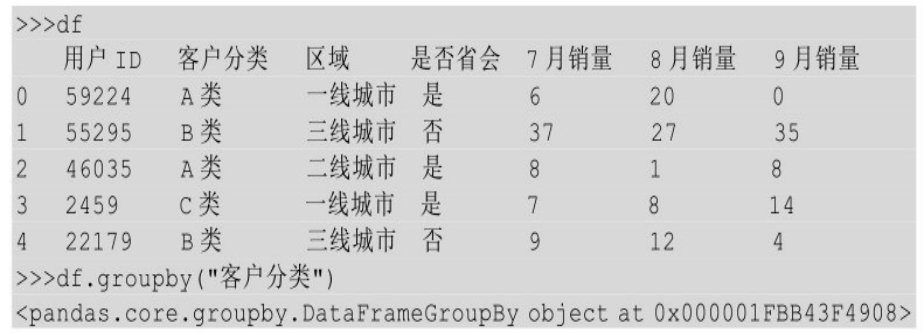
从上面的结果可以看出,如果只传入列名,运行groupby()方法以后返回的不是一个DataFrame对象,而是一个DataFrameGroupBy对象,这个对象里面包含着分组以后的若干组数据,但是没有直接显示出来,需要对这些分组进行汇总计算以后才能显示出来。

上面的代码是根据客户分类对所有数据进行分组,然后对分组以后的数据分别进行计数运算,最后进行合并。
由于对分组后的数据进行了计数运算,因此每一列都会有一个结果,但是如果对分组后的结果做一些数值运算,这个时候就只有数据类型是数值(int、float)的列才会参与运算,比如下面的求和运算。
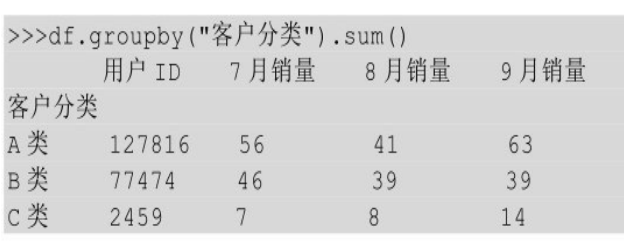
我们把这种对分组后的数据进行汇总运算的操作称为聚合,使用的函数称为聚合函数。
前面讲过的汇总函数都可以作为聚合函数对分组后的数据进行聚合。
按照多列进行分组
上面分组键是某一列,即按照一列进行分组,也可以按照多列进行分组,只要将多个列名以列表的形式传给groupby()即可,汇总计算方式与按照单列进行分组以后数据运算的方式一致。
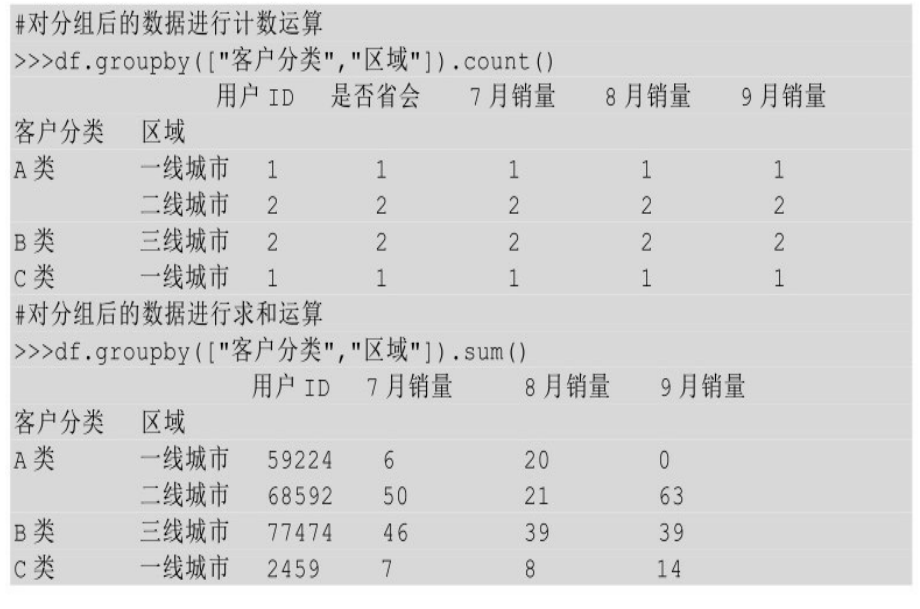
无论分组键是一列还是多列,只要直接在分组后的数据上进行汇总计算,就是对所有可以计算的列进行计算。有时候我们不需要对所有的列进行计算,这时候就可以把想要计算的列(可以是单列,也可以是多列)通过索引的方式取出来,然后在取出来这列数据的基础上进行汇总计算。
比如我们想看一下A、B、C类客户分别有多少,我们先按照客户分类进行分组,然后把用户ID这一列取出来,在这一列的基础上进行计数汇总计算即可。

分组键是Series
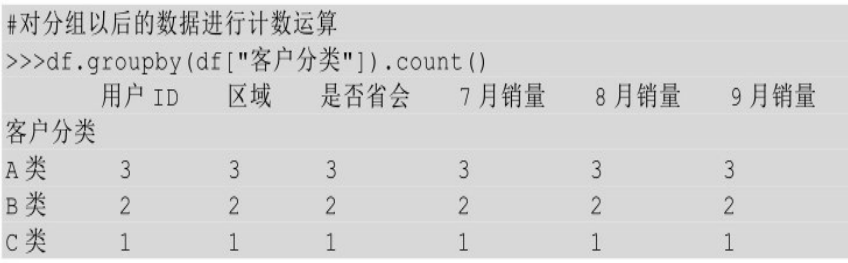
把DataFrame的其中一列取出来就是一个Series,比如下面的df["客户分类"]就是一个Series。

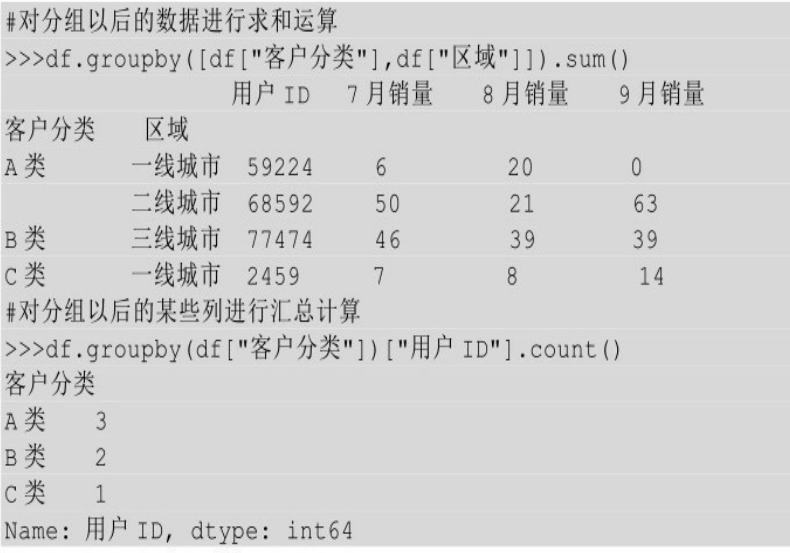
分组键是列名与分组键是Series的唯一区别就是,给groupby()方法传入了什么,其他都一样。可以按照一个或多个Series进行分组,分组以后的汇总计算也是完全一样的,也支持对分组以后的某些列进行汇总计算。
按照一个Series进行分组
按照多个Series进行分组
神奇的aggregate方法
前面用到的聚合函数都是直接在DataFrameGroupBy上调用的,这样分组以后所有列做的都是同一种汇总运算,且一次只能使用一种汇总方式。
aggregate的第一个神奇之处在于,一次可以使用多种汇总方式,比如下面的例子先对分组后的所有列进行计数汇总运算,然后对所有列做求和汇总运算。
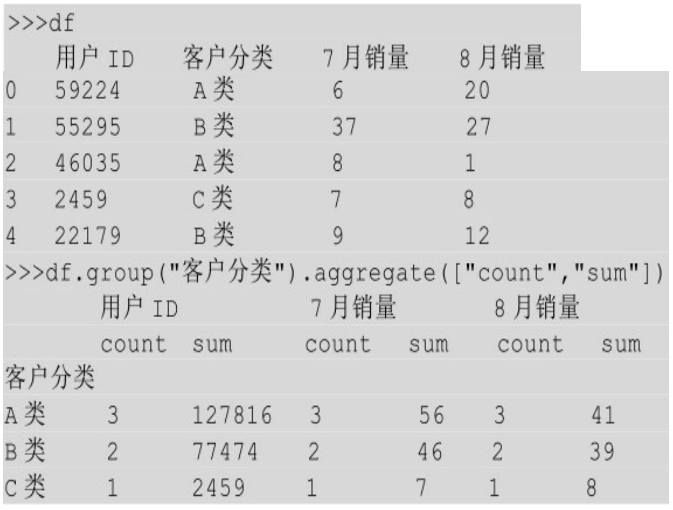
aggregate的第二个神奇之处在于,可以针对不同的列做不同的汇总运算,比如下面的例子,我们想看不同类别的用户有多少,那么对用户ID 进行计数;我们想看不同类别的用户在7、8月的销量,则需要对销量进行求和。

对分组后的结果重置索引
通过上节代码运行的结果可以看出,DataFrameGroupBy 对象经过汇总运算以后的形式并不是标准的DataFrame形式。为了接下来对分组结果进行进一步处理与分析,我们需要把非标准形式转化为标准的DataFrame 形式,利用的方法就是重置索引reset_index()方法,具体实现如下所示。

数据透视表
数据透视表实现的功能与数据分组类似但又不同,数据分组是在一维(行)方向上不断拆分,而数据透视表是在行、列方向上同时拆分。
下图为数据分组与数据透视表的对比。

数据透视表不管是在Excel还是Python中都是一个很重要的功能,大家需要熟练掌握。
Excel 中的数据透视表在插入菜单栏中,单击插入数据透视表以后就会看到如下图所示的界面。下图左侧为数据透视表中的所有字段,右侧为数据透视表的选项,把左侧字段拖入右侧对应的框中即完成了数据透视表的制作。
下图展示了让客户分类作为行标签,区域作为列标签,用户 ID 作为值,且值字段的计算类型为计数的结果。
在数据透视表中把多个字段拖到行对应的框中作为行标签,同样把多个字段拖到列对应的框中作为列标签,把多个字段拖到值对应的框中作为值,而且可以对不同的值字段选择不同的计算类型,请大家自行练习。
Python中数据透视表的制作原理与Excel中的制作原理是一样的。
Python中的数据透视表用到的是pivot_table()方法。

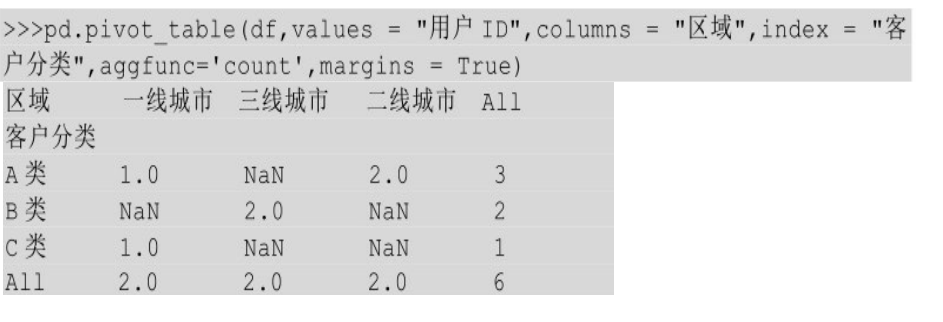
接下来看一些具体实例:客户分类作为index,区域作为columns,用户ID作为values,对values执行count运算,运行结果如下:

上面的运行结果与Excel的不同之处就是没有合计列,Python数据透视表中的合计列默认是关闭的,让其等于True就可以显示出来,示例如下所示。
合计列的名称默认为All,可以通过设置参数margins_name的值进行修改,示例如下所示。

NaN 表示缺失值,我们可以通过设置参数 fill_value 的值对缺失值进行填充,示例如下所示。

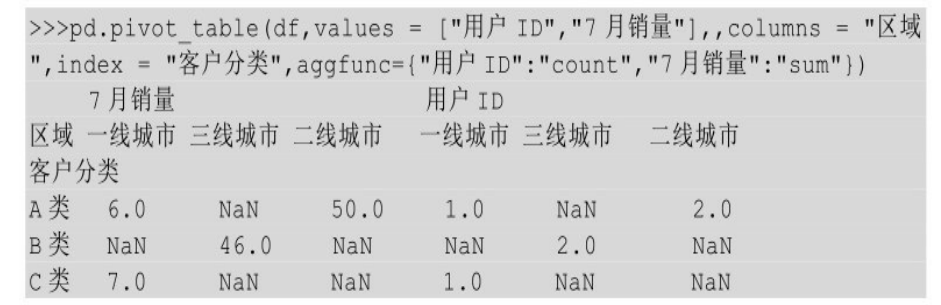
aggfunc 用来表示计算类型,当只传入一种类型时,表示对所有的值字段都进行同样的计算;如果需要对不同的值进行不同的计算类型,则需要传入一个字典,其中键为列名,值为计算方式。下面对用户ID进行计数,对7月销量进行求和。
为了便于分析与处理,我们一般会对数据透视表的结果重置索引,利用的方法同样是reset_index()。

小结
数据分组
分组键是列名
df.groupby(["客户分类","区域"]).count()
df.groupby("客户分类")[["7月销量","8月销量","9月销量"]].mean()
aggregate()
df.groupby("客户分类").aggregate(["count","sum"])
df.groupby("客户分类").aggregate({"用户ID":"count","7月销量":"sum","8月销量":sum}) # 很棒!
数据分组完成后,重置索引 reset_index
df.groupby(["客户分类","区域"]).count().reset_index()
数据透视表
pd.pivot_table()
pd.pivot_table(df,index=["客户分类"],columns=["区域"],values=["用户ID","7月销量"],aggfunc={"用户ID":"count","7月销量":"sum"},margins=True,fill_value=0)