问题
假设空间的样本复杂度(sample complexity):随着问题规模的增长导致所需训练样本的增长称为sample complexity。
实际情况中,最有可能限制学习器成功的因素是训练数据的有限性。
在使用学习器的过程中,我们希望得到与训练数据拟合程度高的假设(hypothesis)。(在前面文章中提到,这样的假设我们称之为g)。
这就要求训练错误率为0。而实际上,大部分情况下,我们找不到这样的hypothesis(通过学习机得到的hypothesis)在训练集上有错误率为0。
所以退而求其次,我们只能要求通过学习机得到的hypothesis在训练集上错误率越低越好,最好接近0。
问题描述:
令D为有限的训练集,Ein(h)(in-sample error)为假设h在训练集D上的训练错误率,Eout(h)(out-of-sample error)是定义在全部数据的错误率。
(由此可知Eout(h)是不可直接求出的,因为不太可能将学习完无限的数据)。令g代表假设集中训练错误率最小的假设。
Hoeffding Inequality

Hoeffding Inequality刻画的是某个事件的真实概率与m各不同的Bernoulli试验中观察到的频率之间的差异。由上述的Hoeffding Inequality可知,
对我们是不可能得到真实的Eout(h),但我们可以通过让假设h在有限的训练集D上的错误率Ein(h)代表Eout(h)。
什么意思呢?Hoeffding Inequality告诉我们:较好拟合训练数据的假设与该假设针对整个数据集的预测,这两者的误差率相差很大的情况发生的概率其实是很小的。
Bad Sample and Bad Data
坏的样本(Bad Sample):假设h在有限的训练集D上的错误率Ein(h)=0,而真实错误率Eout(h)=1/2的情况。
坏的数据(Bad Data):Ein和Eout差别很大的情况。(通常情况下是Eout很大,Ein很小。
下面就将包含Bad data的Data用在多个h上。
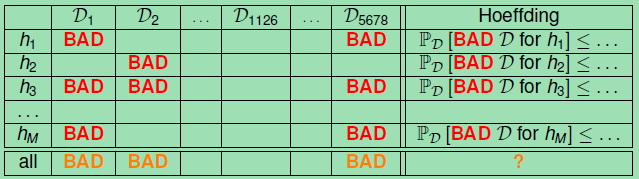
上图说明:
-
对于任一个假设hi,由Hoeffding可知其在所有的数据上(包括Bad Data)上出现不好的情况的总体概率是很小的。
Bound of Bad Data
由上面的表中可以得到下面的结论:

对于所有的M(假设的个数),N(数据集规模)和阈值,Hoeffding Inequality都是有效的
我们不必要知道Eout,可以通过Ein来代替Eout(这句话的意思是Ein(g)=Eout(g) is PAC).
感谢台大林老师的课。
参考:[原]【机器学习基础】理解为什么机器可以学习2——Hoeffding不等式
http://www.tuicool.com/articles/yyu2AnM
更多技术干货请关注:
