如果在shell脚本中处理数据文件,那么我们就必须熟悉正则表达式。正则表达式是用来过滤数据流中文本的模式模板,模式由标准文本字符和特殊字符组成。正则表达式用特殊字符来匹配一系列一个或多个字符,要想掌握正则表达式,必须深刻认识每个特殊字符:
.*^${}+?|()下面分别解释一下:
脱字符 ^ 定义从数据流中文本行的行首开始的字符;
美元符 $ 指明数据必须以该文本模式结尾;
点字符 . 用来匹配任意单字符,除了换行符;
字符组 [Yy] 用来匹配字符组中某个字符(比如y,但不清楚其大小写)出现在数据流中;
排除字符组 [^ch] 用来排除字符组中出现过字符(比如ch)的文本;
区间 [0-9] 用来匹配区间内任意字符(比如0-9间的数字);
星号 * 在字符后放置星号说明该字符将会在匹配模式中出现0次或多次;
问号 ? 表明前面的字符可以出现0次或1次;
加号 + 表明前面的字符可以出现1次或多次;
花括号 {} 允许为可重复的正则表达式指定一个上限(比如{m}正则表大会出现m次,{m,n}正则表达式至少出现m次,至多n次)。
好了,多说无益,举几个例子先体会一下:
a.目录文件计数
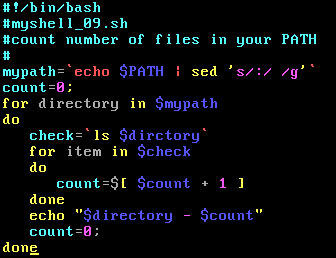
b.解析E-mail地址
E-mail地址的基本格式为: username@hostname
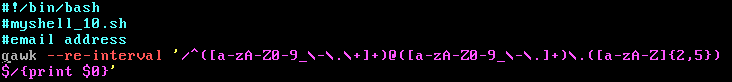
c.获取本机IP地址
