今天我要问你的问题是,请对比 Exception 和 Error,另外,运行时异常与一般异常有什么区
别?
典型回答
Exception 和 Error 都是继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出或者捕获,它是异常处理机制的基本组成类型。
Exception 和 Error 体现了 Java 平台设计者对不同异常分类情况的分类。Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error 是指正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutOfMemoryError 之类,都是 Error 的子类。
Exception 又分为可检查异常和不检查异常(运行时异常),可检查异常在源代码必须显示地进行捕获处理,这是编译器检查地一部分。前面我介绍的不可查地 Error,是 Throwable 不是 Exception。
不检查异常就是所谓地运行时异常,类似 NullPointerException、ArrayIndexOutOfBoundsException 之类,通常是可以编码避免地逻辑错误,具体工具需要来判断是否需要捕获,并不会在编译器强制要求。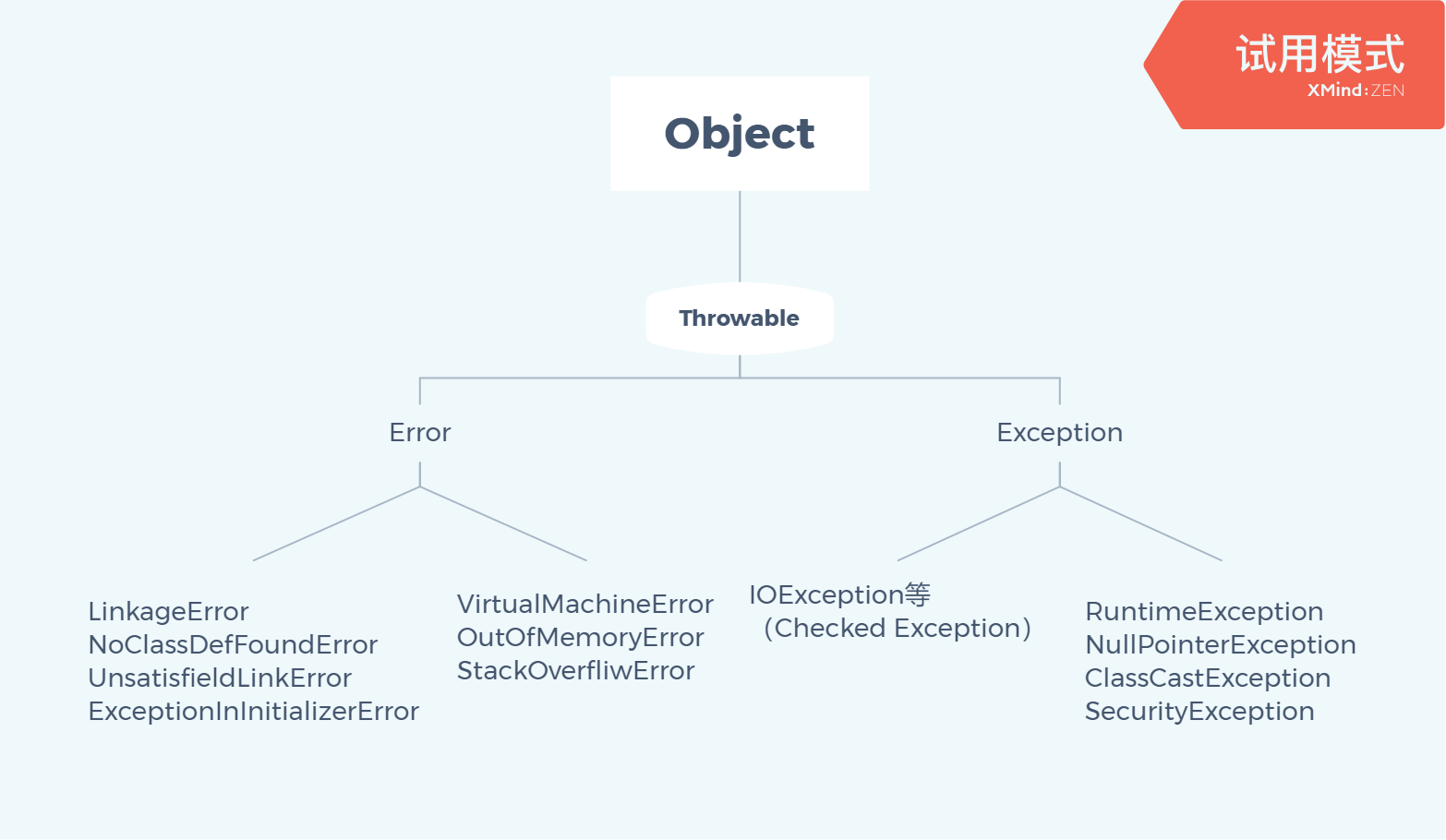
其中有些子类型,最好重点理解一下,比如 NoClassDefFoundError 和
ClassNotFoundException 有什么区别,这也是个经典的入门题目。
第二,理解 Java 语言中操作 Throwable 的元素和实践。掌握最基本的语法是必须的,如 trycatch-finally 块,throw、throws 关键字等。与此同时,也要懂得如何处理典型场景。
异常处理代码比较繁琐,比如我们需要写很多千篇一律的捕获代码,或者在 finally 里面做一些
资源回收工作。随着 Java 语言的发展,引入了一些更加便利的特性,比如 try-with-resources
和 multiple catch,具体可以参考下面的代码段。在编译时期,会自动生成相应的处理逻辑,
比如,自动按照约定俗成 close 那些扩展了 AutoCloseable 或者 Closeable 的对象。
try { // 业务代码 // … Thread.sleep(1000L); } catch (Exception e) { // Ignore it }
上述代码违反了异常处理地两个基本原则
第一、尽量不要捕获类似 Exception 这样地通用异常,而是应该捕获特定异常,在这里是 Thread.sleep() 抛出地 InterruptedException。
这是因为在日常的开发和合作中,我们读代码的机会往往超过写代码,软件工程是门协作的艺
术,所以我们有义务让自己的代码能够直观地体现出尽量多的信息,而泛泛的 Exception 之
类,恰恰隐藏了我们的目的。另外,我们也要保证程序不会捕获到我们不希望捕获的异常。比
如,你可能更希望 RuntimeException 被扩散出来,而不是被捕获。
进一步讲,除非深思熟虑了,否则不要捕获 Throwable 或者 Error,这样很难保证我们能够正
确程序处理 OutOfMemoryError。
第二、不要生吞(swallow)异常。这是异常处理中要特别注意地事情,因为很可能会导致非常难以诊断地诡异情况。
生吞异常,往往是基于假设这段代码可能不会发生,或者感觉忽略异常时无所谓地,但是千万不要在产品代码做这种假设!
如果我们不把异常抛出来,或者也没有输出到日志(Logger)之类,程序可能在后续代码以不可控地方式结束。没人能够轻易判断究竟是哪里抛出了异常,以及是什么原因产生了异常。
再看看第二段代码:
try { // 业务代码 // … } catch (IOException e) { e.printStackTrace(); }
这段代码作为一段实验代码没有任何问题,但是在产品代码中,通常都不允许这样处理。
我们来看看printStackTrace()的文档,开头就是“Prints this throwable and its backtrace
to the standard error stream”。 问题就在这,在稍微复杂一点的生产系统中,标志出错不是个合适的输出选项,因为你很难判断到底输出到哪去了。
尤其对于分布式系统,如果发生异常,但是无法找到堆栈轨迹(stacktrace),这纯属是为诊断设置障碍。所以,最好使用产品日志,详细地输出到日志系统。
我们接下来看下面的代码段,体会一下Throw early, catch late 原则。
public void readPreferences(String fileName){ //...perform operations... InputStream in = new FileInputStream(fileName); //...read the preferences file... }
如果 fileName 是 null,那么程序就会抛出 NullPointerException,但是由于没有第一时间暴
露出问题,堆栈信息可能非常令人费解,往往需要相对复杂的定位。这个 NPE 只是作为例子,
实际产品代码中,可能是各种情况,比如获取配置失败之类的。在发现问题的时候,第一时间抛
出,能够更加清晰地反映问题。
我们可以修改一下,让问题“throw early”,对应的异常信息就非常直观了。
public void readPreferences(String filename) { Objects. requireNonNull(filename); //...perform other operations... InputStream in = new FileInputStream(filename); //...read the preferences file... }
至于“catch late”,其实是我们经常苦恼的问题,捕获异常后,需要怎么处理呢?最差的处理
方式,就是我前面提到的“生吞异常”,本质上其实是掩盖问题。如果实在不知道如何处理,可
以选择保留原有异常的 cause 信息,直接再抛出或者构建新的异常抛出去。在更高层面,因为
有了清晰的(业务)逻辑,往往会更清楚合适的处理方式是什么。
有的时候,我们会根据需要自定义异常,这个时候除了保证提供足够的信息,还有两点需要考 虑: 是否需要定义成 Checked Exception,因为这种类型设计的初衷更是为了从异常情况恢复, 作为异常设计者,我们往往有充足信息进行分类。 在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致潜在的安全问 题。如果我们看 Java 的标准类库,你可能注意到类似 java.net.ConnectException,出错信 息是类似“ Connection refused (Connection refused)”,而不包含具体的机器名、IP、 端口等,一个重要考量就是信息安全。类似的情况在日志中也有,比如,用户数据一般是不 可以输出到日志里面的。 业界有一种争论(甚至可以算是某种程度的共识),Java 语言的 Checked Exception 也许是个 设计错误,反对者列举了几点: Checked Exception 的假设是我们捕获了异常,然后恢复程序。但是,其实我们大多数情况 下,根本就不可能恢复。Checked Exception 的使用,已经大大偏离了最初的设计目的。 Checked Exception 不兼容 functional 编程,如果你写过 Lambda/Stream 代码,相信深 有体会。 很多开源项目,已经采纳了这种实践,比如 Spring、Hibernate 等,甚至反映在新的编程语言 设计中,比如 Scala 等。 如果有兴趣,你可以参考: http://literatejava.com/exceptions/checked-exceptions-javas-biggest-mistake/。 当然,很多人也觉得没有必要矫枉过正,因为确实有一些异常,比如和环境相关的 IO、网络 等,其实是存在可恢复性的,而且 Java 已经通过业界的海量实践,证明了其构建高质量软件的 能力。我就不再进一步解读了,感兴趣的同学可以点击链接,观看 Bruce Eckel 在 2018 年全球 软件开发大会 QCon 的分享 Failing at Failing: How and Why We've Been Nonchalantly Moving Away From Exception Handling。 我们从性能角度来审视一下 Java 的异常处理机制,这里有两个可能会相对昂贵的地方: try-catch 代码段会产生额外的性能开销,或者换个角度说,它往往会影响 JVM 对代码进行 优化,所以建议仅捕获有必要的代码段,尽量不要一个大的 try 包住整段的代码;与此同 时,利用异常控制代码流程,也不是一个好主意,远比我们通常意义上的条件语句 (if/else、switch)要低效。 Java 每实例化一个 Exception,都会对当时的栈进行快照,这是一个相对比较重的操作。如 果发生的非常频繁,这个开销可就不能被忽略了。
所以,对于部分追求极致性能的底层类库,有种方式是尝试创建不进行栈快照的 Exception。这
本身也存在争议,因为这样做的假设在于,我创建异常时知道未来是否需要堆栈。问题是,实际
上可能吗?小范围或许可能,但是在大规模项目中,这么做可能不是个理智的选择。如果需要堆
栈,但又没有收集这些信息,在复杂情况下,尤其是类似微服务这种分布式系统,这会大大增加
诊断的难度。
当我们的服务出现反应变慢、吞吐量下降的时候,检查发生最频繁的 Exception 也是一种思
路。关于诊断后台变慢的问题,我会在后面的 Java 性能基础模块中系统探讨。
今天,我从一个常见的异常处理概念问题,简单总结了 Java 异常处理的机制。并结合代码,分
析了一些普遍认可的最佳实践,以及业界最新的一些异常使用共识。最后,我分析了异常性能开
销,希望对你有所帮助