开篇闲扯
打工人,打工魂,我们生而人上人。当“资本主义”逐渐禁锢我们人(大)上(韭)人(菜)肉体的时候,那一刻我才明白那个日不落帝国·资本主义收割机·瑞民族之光幸·瑞幸咖啡是多么的了不起,尽管我不懂咖啡,但还是要说一声谢谢!说到咖啡,喝完就想上厕所,对写bug的我来说太不友好了,毕竟我不(很)喜欢带薪上厕所。
回归本次的不正经Java文章,本次新闻主要内容有...tui~~嘴瓢了。上篇文章末尾处已经提到了,主要会把我对Synchronized的理解进行一次全方位的梳理,如果能帮助到大家吊打面试官,万分荣幸。
Synchronized起源
那是个月黑风高的夜晚,Doug Lee先生像我们一样喝了咖啡憋着尿加班到深夜,只是他在写JDK,我们在用他的JDK写BUG。在创作JDK1.5之前,他忘了在Java语言中提供同步可扩展的同步接口或者方法了,于是在1.5之前给了我们一个恶Synchronized凑合用一下,而到了JDK1.5之后,增加了Lock接口及很多原生的并发包供我们使用。因此,Synchronized作为关键字的形式存在了很久,且在后续JDK1.6的版本中对它做了很多优化,从而提升它的性能,使它能够跟Lock有一战之力。好了,讲完了,再见!
Synchronized是什么
如果我说,Synchronized是一种基于JVM中对象监视器的隐式非公平可重入重量级锁(这头衔跟瑞幸有一拼),加解锁都是靠JVM内部自动实现的,吧啦吧啦...简称"面试八股文",很显然我不能这么写,这样还不如直接甩个博客链接来的快。来,解释一下上面那句话,隐式锁是基于操作系统的MutexLock实现的,每次加解锁操作都会带来用户态与内核态的切换,导致系统增加很多额外的开销。可以自行百度学习一下用户态与内核态的定义,这里就不赘述了。同时Synchronized的加解锁过程开发人员是不可控的,失去了可扩展性。
接下来我们通过一个例子,看一看Synchronized在编译后到底是什么样子,上才(代)艺(码):
/**
* FileName: SynchronizeDetail
* Author: RollerRunning
* Date: 2020/11/30 10:10 PM
* Description: 详解Synchronized
*/
public class SynchronizeDetail {
public synchronized void testRoller() {
System.out.println("Roller Running!");
}
public void testRunning(){
synchronized (SynchronizeDetail.class){
System.out.println("Roller Running!");
}
}
}
将上面的源代码进行编译再输出编译后的代码:
public com.design.model.singleton.SynchronizeDetail();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 9: 0
public synchronized void testRoller();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Roller Running!
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 14: 0
line 15: 8
public void testRunning();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: ldc #5 // class com/design/model/singleton/SynchronizeDetail
2: dup
3: astore_1
4: monitorenter
5: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
8: ldc #3 // String Roller Running!
10: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
13: aload_1
14: monitorexit
15: goto 23
18: astore_2
19: aload_1
20: monitorexit
21: aload_2
22: athrow
23: return
Exception table:
from to target type
5 15 18 any
18 21 18 any
LineNumberTable:
line 17: 0
line 18: 5
line 19: 13
line 20: 23
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 18
locals = [ class com/design/model/singleton/SynchronizeDetail, class java/lang/Object ]
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
}
观察一下编译后的代码,在testRoller()方法中有这样一行描述flags: ACC_PUBLIC, ACC_SYNCHRONIZED,表示着当前方法的访问权限为SYNCHRONIZED的状态,而这个标志就是编译后由JVM根据Synchronized加锁的位置增加的锁标识,也称作类锁,凡是要执行该方法的线程,都需要先获取Monitor对象,直到锁被释放以后才允许其他线程持有Monitor对象。以HotSport虚拟机为例Monitor的底层又是基于C++ 实现的ObjectMonitor,我不懂C++,通过查资(百)料(度)查到了这个ObjectMonitor的结构如下:
ObjectMonitor::ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; //线程重入次数
_object = NULL;
_owner = NULL; //标识拥有该monitor的线程
_WaitSet = NULL; //由等待线程组成的双向循环链表
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; //多线程竞争锁进入时的单向链表
FreeNext = NULL ;
_EntryList = NULL ; //处于等待锁block状态的线程的队列,也是一个双向链表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
那么接下来就用一张图说明一下多线程并发情况下获取testRoller()方法锁的过程
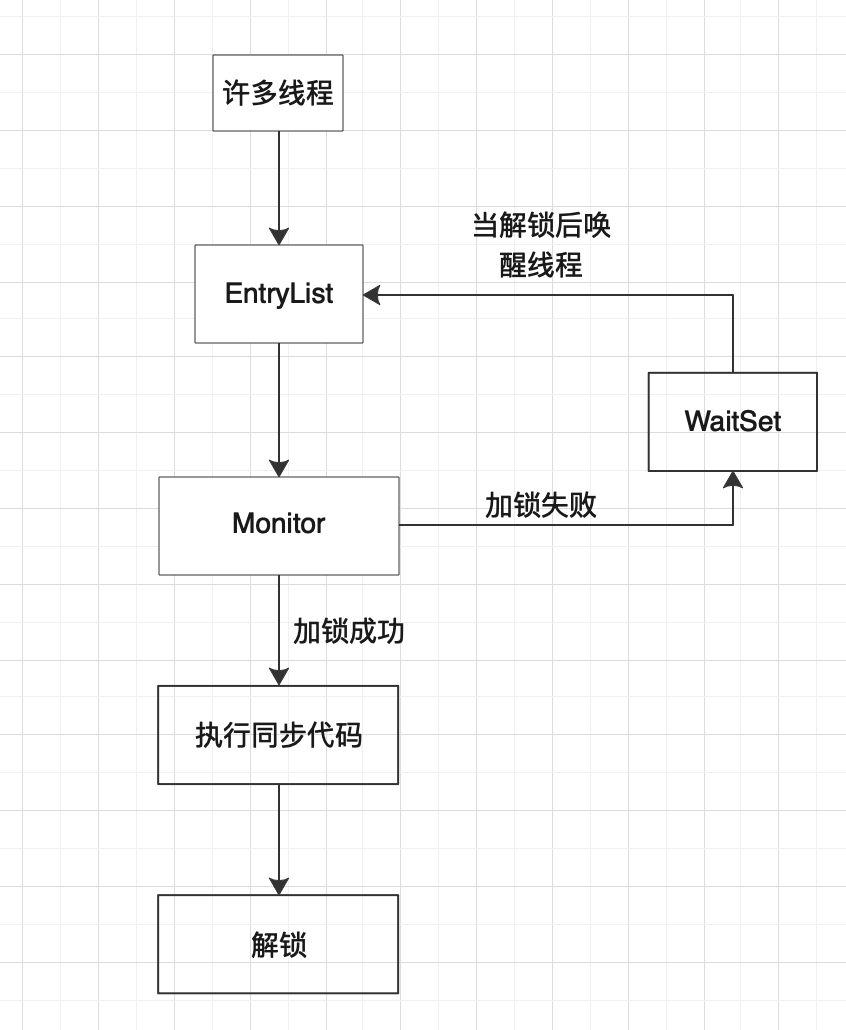
上文中提到了MutexLock,而图中加解锁获取Monitor对象就是基于它实现的互斥操作,再次强调,在加解锁过程中线程会存在内核态与用户态的切换,因此牺牲了一部分性能。
再来说一下testRunning()方法,很显然,在编译后的class中出现了一对monitorenter/monitorexit,其实就是对象监视器的另一种形态,本质上是一样的,不过区别是,对象在锁实例方法或者实例对象时称作内置锁。而上面的testRoller()是对类(对象的class)的权限控制,两者互不影响。
到这里就解释Synchronized的基本概念,接下来要说一说它到底跟对象在对空间的内存布局有什么关系。
Synchronized与对象堆空间布局
还是以64位操作系统下HotSport版本的JVM为例,看一张全网都搜的到的图
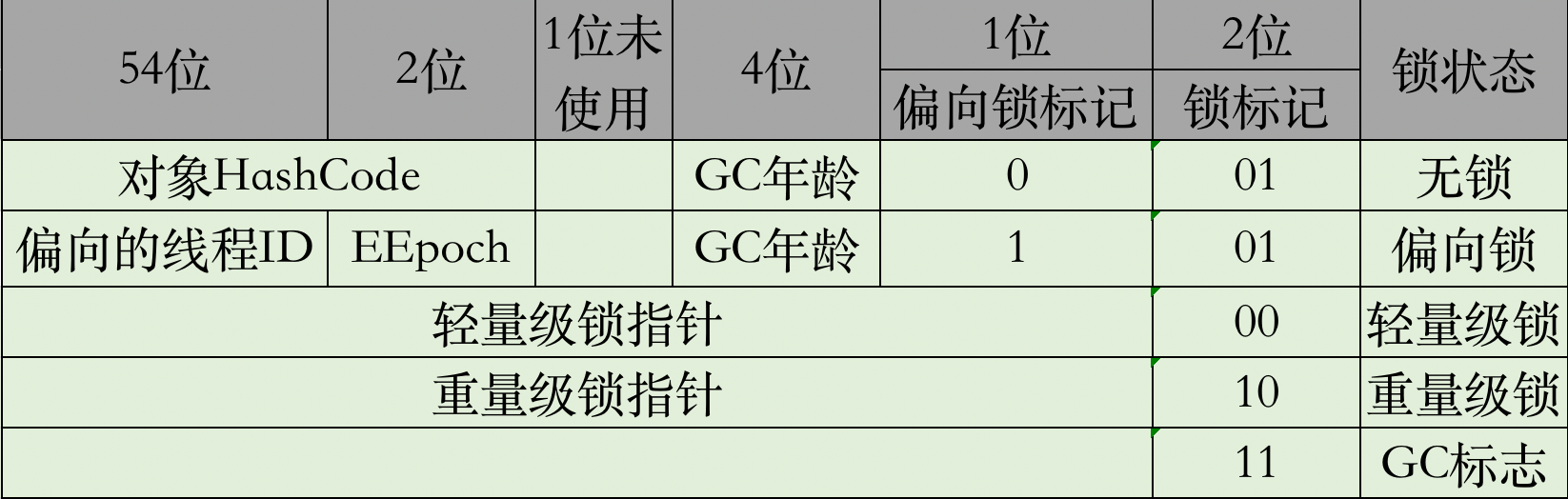
图中展示了MarkWord占用的64位在不同锁状态下记录的信息,主要有对象的HashCode、偏向锁线程ID、GC年龄以及指向锁的指针等,记住这里的GC标志记录的位置,将来的JVM文章也会用到它,逃不掉的。在上篇例子中查看内存布局的基础上稍微改动一下,代码如下:
/**
* FileName: JavaObjectMode
* Author: RollerRunning
* Date: 2020/12/01 20:12 PM
* Description:查看加锁对象在内存中的布局
*/
public class JavaObjectMode {
public static void main(String[] args) {
//创建对象
Student student = new Student();
synchronized(student){
// 获得加锁后的对象布局内容
String s = ClassLayout.parseInstance(student).toPrintable();
// 打印对象布局
System.out.println(s);
}
}
}
class Student{
private String name;
private String address;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
第一张图是上篇文章的也就是没加锁时对象的内存布局,第二张图是加锁后的内存布局,观察一下VALUE的值
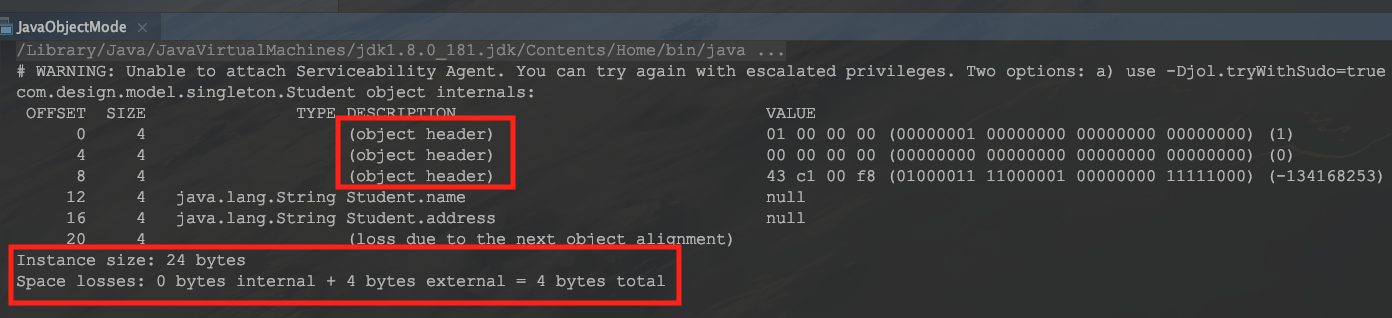

其实加锁后,就是修改了对象头中MarkWord的值用来记录当前锁状态,所以可以看到加锁前后VALUE发生了变化。
从第一张图的第一行VALUE值可以看出当前的锁标记为001(这里面涉及到一个大端序和小端序的问题,可以自己学习一下:https://blog.csdn.net/limingliang_/article/details/80815393 ),对应的表中恰好是无锁状态,实际代码也是无锁状态。而图二可以看出当前锁标记为000(提示:在上图001同样的位置),对应表中状态为轻量级锁,那么代码中的的Synchronized怎么成了轻量级锁了呢?因为在JDK1.6以后对锁进行了优化,Synchronized会在竞争逐渐激烈的过程中慢慢升级为重量级互斥锁。
但是还有问题,为啥加锁了,上来就是轻量级锁而不是偏向锁呢,原因是在初始化锁标记时JVM中默认延迟4s创建偏向锁,由-XX:BiaseedLockingStartupDelay=xxx控制。一旦创建偏向锁,在没有线程使用当前偏向锁时,叫做匿名偏向锁,即上表中偏向线程ID的值为空,当有一个线程过来加锁时,就进化成了偏向锁。
到这里,是不是已经能看明白天天说的锁也不过是一堆标志位实现的,让我写几个if-else就给你写出来了

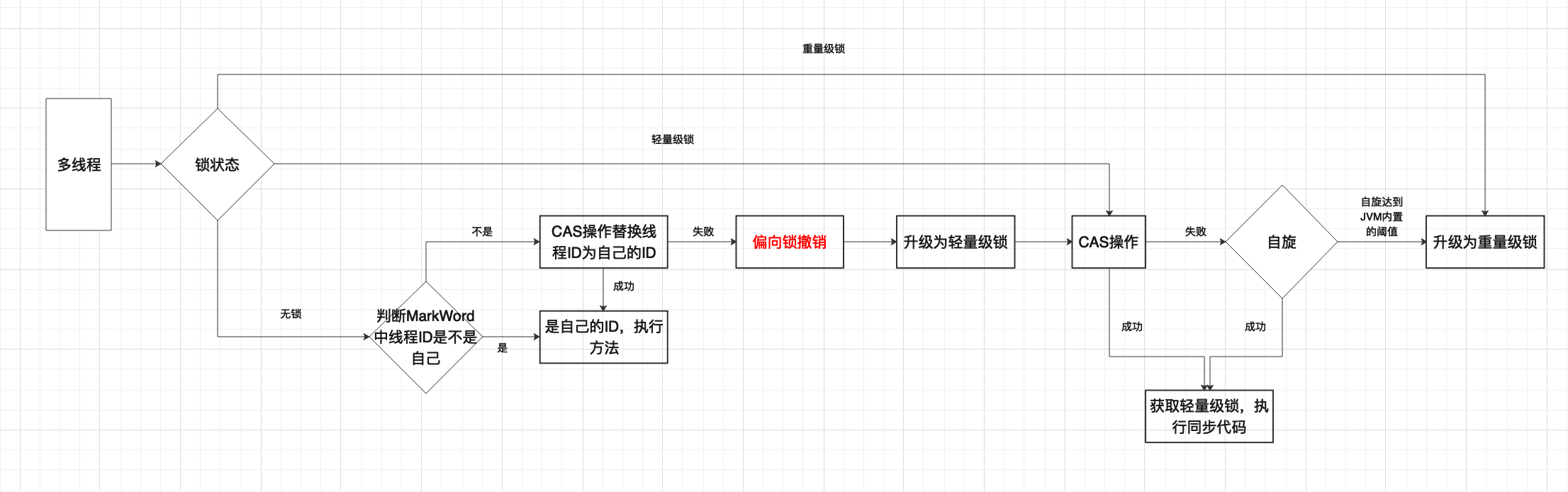
Synchronized锁升级过程
锁的升级过程为:偏向锁-->偏向锁-->轻量级锁-->重量级锁。这个过程是随着线程竞争的激烈程度而逐渐变化的。
偏向锁
其中匿名偏向锁前面已经说过了,偏向锁的作用就是当同一线程多次访问同步代码时,这一线程只需要获取MarkWord中是否为偏向锁,再判断偏向的线程ID是不是自己,就是俩if-else搞定,Doug Lee先生不过如此嘛。如果发现偏向的线程ID是自己的线程ID就去执行代码,不是就要通过CAS来尝试获取锁,一旦CAS获取失败,就要执行偏向锁撤销的操作。而这个过程在高并发的场景会代码很大的性能开销,慎重使用偏向锁。图为偏向锁的内存布局

轻量级锁
轻量级锁是一种基于CAS操作的,适用于竞争不是很激烈的场景。轻量级锁又分为自旋锁和自适应自旋锁。自旋锁:因为轻量锁是基于CAS理论实现的,因此当资源被占用,其他线程抢锁失败时,会被挂起进入阻塞状态,当资源就绪时,再次被唤醒,这样频繁的阻塞唤醒申请资源,十分低效,因此产生了自旋锁。JDK1.6中,JVM可以设置-XX:+UseSpinning参数来开启自旋锁,使用-XX:PreBlockSpin来设置自旋锁次数。不过到了JDK1.7及以后,取消自旋锁参数,JVM不再支持由用户配置自旋锁,因此出现了自适应自旋锁。自适应自旋锁:JVM会根据前一线程持有自旋锁的时间以及锁的拥有者的状态进行动态决策获取锁失败线程的自旋次数,进而优化因为过多线程自旋导致的大量CAS状态的线程占用资源。下图为轻量级锁内存布局:
随着线程的增多,竞争更加激烈以后,CAS等待已经不能满足需求,因此轻量级锁又要向重量级锁迈进了。在JDK1.6之前升级的关键条件是超过了自旋等待的次数。在JDK1.7后,由于参数不可控,JVM会自行决定升级的时机,其中有几个比较重要的因素:单个线程持有锁的时间、线程在用户态与内核态之间切换的时间、挂起阻塞时间、唤醒时间、重新申请资源时间等
重量级锁
而当升级为重量级锁的时候,就没啥好说的了,锁标记位为10,所有线程都要排队顺序执行10标记的代码,前面提到的每一种锁以及锁升级的过程,其实都伴随着MarkWord中锁标记位的变化。相信看到这,大家应该都理解了不同时期的锁对应着对象在堆空间中头部不同的标志信息。重量级锁的内存布局我模拟了半天也没出效果,有兴趣的大佬可以讲一下。
最后附上一张图,展示一下锁升级的过程,画图不易,还请观众老爷们关注啊:
锁优化
1.动态编译实现锁消除
通过在编译阶段,使用编译器对已加锁代码进行逃逸性分析,判断当前同步代码是否是只能被一个线程访问,未被发布到其他线程(其他线程无权访问)。当确认后,会在编译器,放弃生成Synchronized关键字对应的字节码。
2.锁粗化
在编译阶段,编译器扫描到相邻的两个代码块都使用了Synchronized关键字,则会将两者合二为一,降低同一线程在进出两个同步代码块过程中带来的性能损耗。
3.减小锁粒度
这是开发层面需要做的事,即将锁的范围尽量明确并降低该范围,不能简单粗暴的加锁。最佳实践:在1.7及以前的ConcurrentHashMap中的分段锁。不过已经不用了。
最后,感谢各位观众老爷,还请三连!!!
更多文章请扫码关注或微信搜索Java栈点公众号!
