谈起浏览器缓存总是感觉很神秘,今天就揭开它的面纱。浏览器缓存的知识是前端工程师必须要掌握的,因为这些知识直接影响到你的页面的用户体验,影响到你的页面的加载策略。我们先来思考几个问题:为何要做缓存方案?缓存工作的原理是什么?制定缓存方案时要考虑哪些因素?等等,带着疑惑,我们来一步步认识缓存,看看它到底是何方神圣。
浅析缓存机制
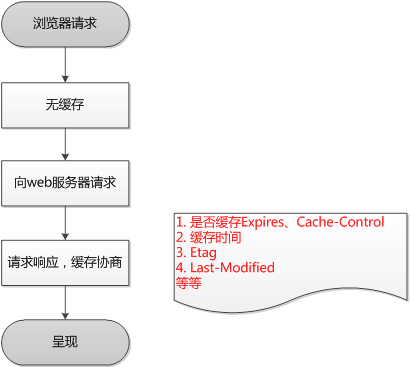
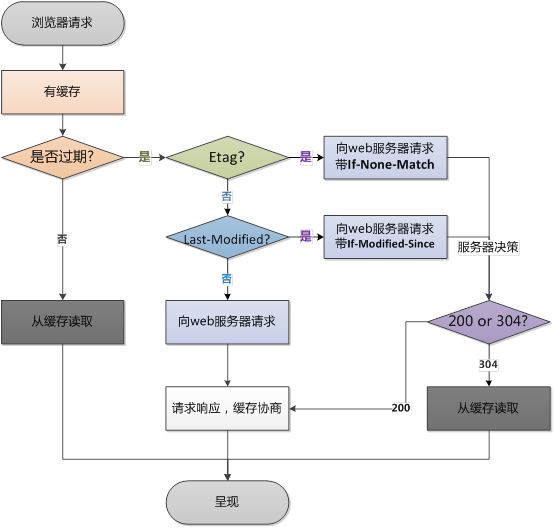
浏览器访问一个站点时,会从站点服务器下载请求的资源(比如 html、css、js、图片等)到本地,并存储在浏览器的缓存区中;等到再次访问该站点,浏览器就会先从缓存区获取能用的资源;对于每一个请求资源,浏览器都会根据该资源http协议响应头中的字段(cache-control、expires等)决定是否要缓存该资源 以及 确定该资源的有效期是多久;如果缓存的资源过了有效期,并且该资源在服务器中最后一次修改的时间也改变了,这时浏览器就会重新下载该资源;
流程图如下,盗图浏览器缓存机制:
浏览器第一次请求:
浏览器第二次请求:
浏览器http缓存的控制
控制浏览器缓存的机制有两种:一,利用http协议(主流) ;二,非http协议,利用<meta>标签;
2.1 非http协议的浏览器缓存
通过meta标签规定相关属性来告诉浏览器不需要缓存该资源,部分浏览器支持,平时很少使用;
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
以下内容为利用http协议控制缓存的知识点:
2.2 与http协议缓存相关的字段
响应头相关:
| 字段名称 | 简要说明 |
| pragma | http1.0遗留,<meta>标签中使用产生的字段 |
| expires | 指明资源有效期,http1.0协议中的 |
| cache-control | 指明资源有效期,控制缓存行为,http1.1协议增加 |
| ETag | 资源的匹配信息 |
| last-modified | 资源在服务器中最后一次修改的时间 |
请求头相关:
| 字段名称 | 简要说明 |
| if-Match | 比较ETag是否一致 |
| if-None-Match | 比较ETag是否不一致 |
| if-Modified-Since | 比较资源更新最后的时间是否一致 |
| if-Unmodified-Since | 比较资源更新最后的时间是否不一致 |
2.3 Expires
Pragma,Expires都是http1.0协议中的字段;pragma用来禁用缓存,expires则是用来开启缓存、定义缓存时间的;
Expires的值对应一个GMT(格林尼治时间),比如“Mon, 22 Jul 2002 11:12:01 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
在客户端我们同样可以使用meta标签来知会IE(也仅有IE能识别)页面(同样也只对页面有效,对页面上的资源无效)缓存时间:
<meta http-equiv="expires" content="mon, 18 apr 2016 14:30:00 GMT">
如果希望在IE下页面不走缓存,希望每次刷新页面都能发新请求,那么可以把“content”里的值写为“-1”或“0”。
注意的是该方式仅仅作为知会IE缓存时间的标记,你并不能在请求或响应报文中找到Expires字段。
2.4 cache-control
cache-control与Expires功能相似,也是用于规定资源的有效时间;cache-control是http1.1协议中字段,如果同时出现cache-control字段中的max-age和Expires,则cache-control的优先级高;同时cache-control有很多参数,不同参数定义了不同的功能;
Expires规定的资源的失效时间,cache-control中的max-age规定了资源的有效时间;
2.5 缓存校验字段
上述的首部字段均能让客户端决定是否向服务器发送请求,比如设置的缓存时间未过期,那么自然直接从本地缓存取数据即可(在chrome下表现为200 from cache),若缓存时间过期了或资源不该直接走缓存,则会发请求到服务器去。
我们现在要说的问题是,如果客户端向服务器发了请求,那么是否意味着一定要读取回该资源的整个实体内容呢?
我们试着这么想——客户端上某个资源保存的缓存时间过期了,但这时候其实服务器并没有更新过这个资源,如果这个资源数据量很大,客户端要求服务器再把这个东西重新发一遍过来,是否非常浪费带宽和时间呢?
答案是肯定的,那么是否有办法让服务器知道客户端现在存有的缓存文件,其实跟自己所有的文件是一致的,然后直接告诉客户端说“这东西你直接用缓存里的就可以了,我这边没更新过呢,就不再传一次过去了”。
为了让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,Http1.1新增了几个首部字段来做这件事情。
2.5.1 Last-Modified
2.5.2 ETag
浏览器http缓存的作用
从原理中可以看出http缓存的作用显而易见,总结如下三点:
3.1 减少网络带宽消耗
无论是用户还是网站运营者,带宽流量就是金钱;请求资源如果能高效地利用缓存,就会产生很少的流量,这节省了用户、网站运营者的流量;
3.2 降低服务器的压力
用户高效地利用缓存,自然而然就会减少对服务器的请求次数;在用户基数比较大的站点中,这个效果会很明显;
3.3 提升用户体验
有时用户的网络并不是很好,冗余的请求需要消耗很长时间;如果能利用好缓存,则会快速打开网页,从而极大提升用户体验;
构建可缓存的站点
既然浏览器http缓存有这么多优点,那我们如何对一个站点做缓存方案呢?有如下几种方式( 参考:web缓存机制系列 ):
4.1 同一资源保证URL的稳定
URL是浏览器缓存机制的基础,所以如果一个资源需要在多个地方被引用,尽量保证URL是固定的。同时推荐使用公共类库,比如Google Ajax Library等,有利于最大限度使用缓存;对于常用的类库,比如jquery等,尽量使用知名CDN;
4.2 给css、js、图片等资源增加HTTP缓存头,并强制入口html不被缓存
这点非常重要,也是主要策略之一;对于不经常修改的静态资源,比如css,js,图片等,可以设置一个较长的过期的时间,或者至少加上Last-Modified/Etag,而对于html页面这种入口文件,不建议设置缓存。因为入口文件经常处于修改状态,这样既能保证在静态资源不变了情况下,可以不重发请求或直接通过304避免重复下载,又能保证在资源有更新的,只要通过给资源增加时间戳或者更换路径,就能让用户访问最新的资源
4.3 减少对cookie的依赖
过多的使用Cookie会大大增加HTTP请求的负担,每次GET或POST请求,都会把Cookie都带上,增加网络传输流量,导致增长交互时间;同时Cache是很难被缓存的,应该尽量少使用,或者这在动态页面上使用
返回码200、304
与浏览器http缓存相关的返回码是200,304;200表示返回成功,并且从服务器中获取了资源;304(not modified)表示返回成功,而是从缓存中获取资源;但是有时候明明应该返回304,但是浏览器(chrome浏览器)却返回200(from disk cache) 或者 200(from memory cache) 或者 200(from ServiceWorker);
5.1 200 from cache && 304 not modified
200 from cache 表示从缓存区获取数据,但是浏览器没有发送请求;304 not modified表示从缓存区获取数据,但是浏览器发送了请求到服务器校验,服务器验证了该资源在服务器上没有发生改动;304 not modified是在有效期过了之后,但是ETag或者last-modified没有改变时发生的;
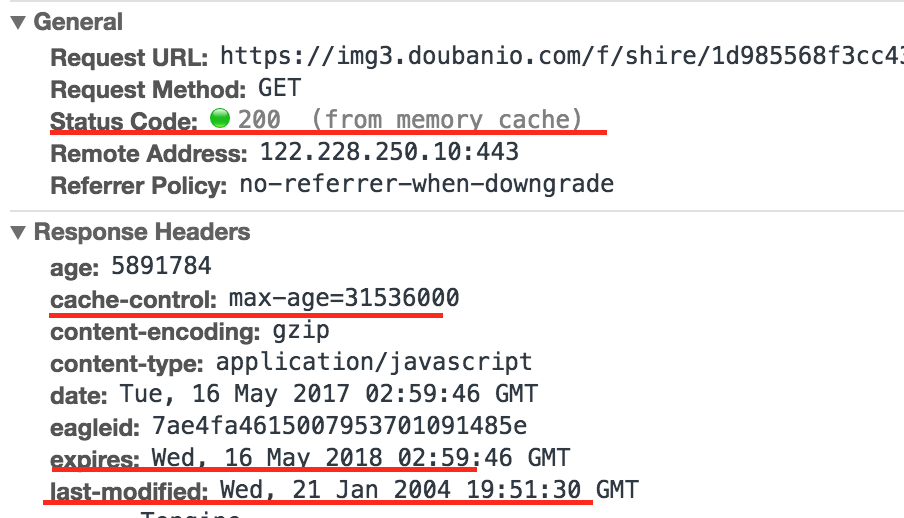
5.2 from disk cache && from memory cache
disk cache表示从磁盘中读取缓存,memory cache表示从内存中读取缓存;磁盘中的缓存可以长期存在,内存中的缓存,当关闭浏览器程序时就会清除;
5.3 from ServiceWorker
这个是chrome中出现的,目前尚不清楚;
参考:(优质的文档能够准确,快速地理解掌握知识点;感谢以下文档)
[1] 浏览器缓存机制详解
[2] 浅谈浏览器http的缓存机制
[3] Web缓存机制系列
[4] 浏览器缓存机制浅析